 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLD-Road:A global-local decoding road network extraction model for remote sensing images
Jun 11, 2025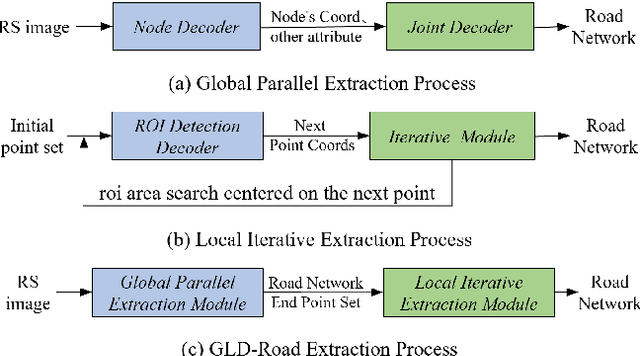
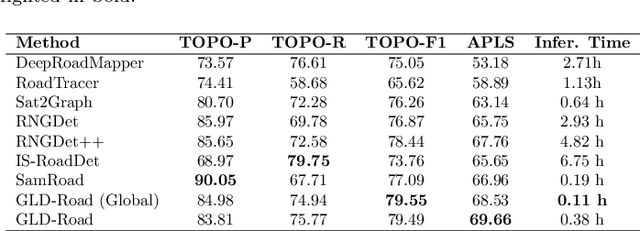

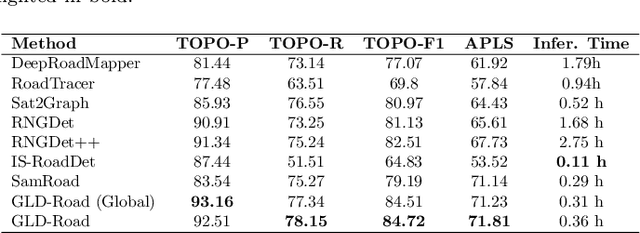
Road networks are crucial for mapping, autonomous driving, and disaster response. While manual annotation is costly, deep learning offers efficient extraction. Current methods include postprocessing (prone to errors), global parallel (fast but misses nodes), and local iterative (accurate but slow). We propose GLD-Road, a two-stage model combining global efficiency and local precision. First, it detects road nodes and connects them via a Connect Module. Then, it iteratively refines broken roads using local searches, drastically reducing computation. Experiments show GLD-Road outperforms state-of-the-art methods, improving APLS by 1.9% (City-Scale) and 0.67% (SpaceNet3). It also reduces retrieval time by 40% vs. Sat2Graph (global) and 92% vs. RNGDet++ (local). The experimental results are available at https://github.com/ucas-dlg/GLD-Road.
LRSCLIP: A Vision-Language Foundation Model for Aligning Remote Sensing Image with Longer Text
Mar 25, 2025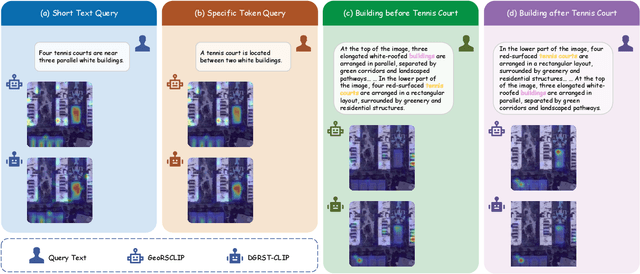
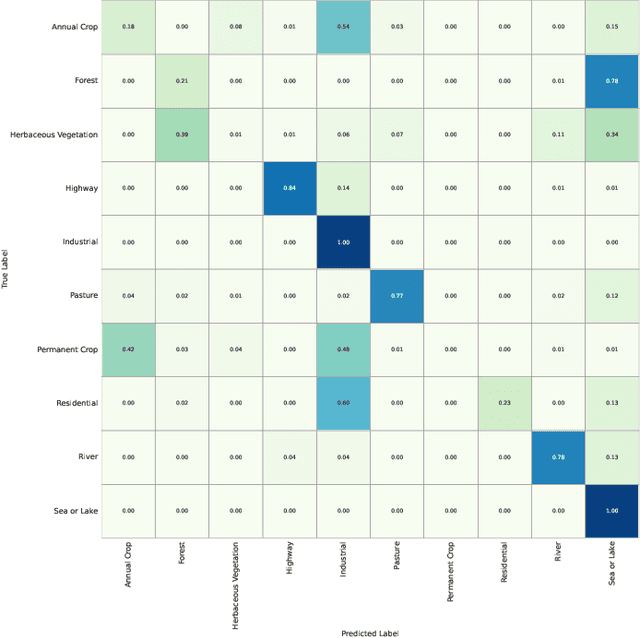
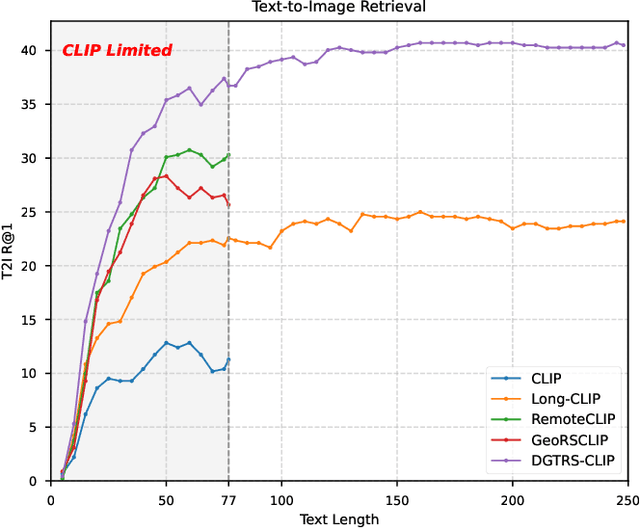
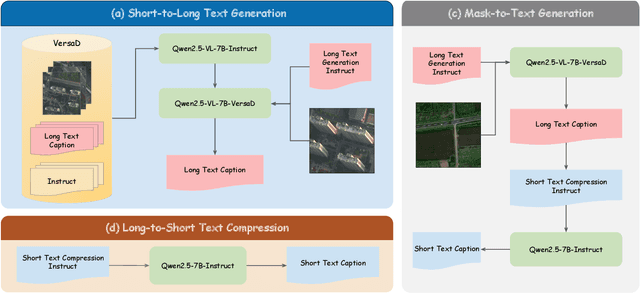
This study addresses the technical bottlenecks in handling long text and the "hallucination" issue caused by insufficient short text information in remote sensing vision-language foundation models (VLFM). We propose a novel vision-language foundation model, LRSCLIP, and a multimodal dataset, LRS2M. The main contributions are as follows: (1) By integrating multi-source remote sensing data and adopting a large language model labeling strategy, we construct the LRS2M dataset, which contains 2 million image-text pairs, providing both short and long texts for the first time, thus solving the problem of semantic granularity limitations in existing datasets; (2) The design of the LRSCLIP architecture based on Long-CLIP's KPS module, which extends CLIP's text processing capacity and achieves fine-grained cross-modal feature alignment through a dual-text loss weighting mechanism. Experimental results show that LRSCLIP improves retrieval accuracy by 10\%-20\% over the Long-CLIP baseline in the zero-shot long-text cross-modal retrieval task. For the zero-shot short-text cross-modal retrieval task, LRSCLIP achieves improvements over the current best model, GeoRSCLIP, with increases of 0.17\%, 0.67\%, and 0.92\% in Text to Image R@1, Image to Text R@1, and mR on RSITMD, respectively, and 0.04\%, 2.93\%, and 1.28\% on RSICD. In the zero-shot image classification task (average accuracy=75.75\%) and semantic localization task (Rmi=0.7653), LRSCLIP achieves state-of-the-art performance. These results validate the dual advantages of fine-grained semantic understanding and global feature matching in LRSCLIP. This work provides a new benchmark model and data support for remote sensing multimodal learning. The related code has been open source and is available at https://github.com/MitsuiChen14/LRSCLIP.