 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFGP: Feature-Gradient-Prune for Efficient Convolutional Layer Pruning
Nov 19, 2024



To reduce computational overhead while maintaining model performance, model pruning techniques have been proposed. Among these, structured pruning, which removes entire convolutional channels or layers, significantly enhances computational efficiency and is compatible with hardware acceleration. However, existing pruning methods that rely solely on image features or gradients often result in the retention of redundant channels, negatively impacting inference efficiency. To address this issue, this paper introduces a novel pruning method called Feature-Gradient Pruning (FGP). This approach integrates both feature-based and gradient-based information to more effectively evaluate the importance of channels across various target classes, enabling a more accurate identification of channels that are critical to model performance. Experimental results demonstrate that the proposed method improves both model compactness and practicality while maintaining stable performance. Experiments conducted across multiple tasks and datasets show that FGP significantly reduces computational costs and minimizes accuracy loss compared to existing methods, highlighting its effectiveness in optimizing pruning outcomes. The source code is available at: https://github.com/FGP-code/FGP.
An End-to-end Approach for Lexical Stress Detection based on Transformer
Nov 06, 2019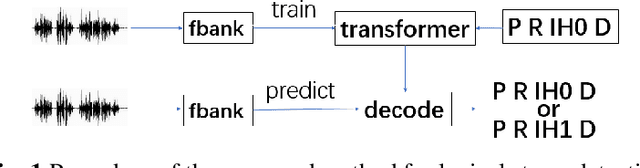
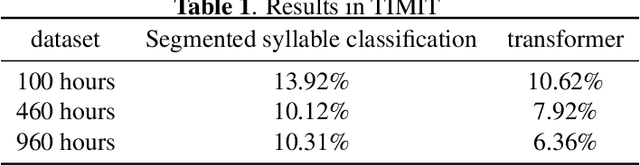
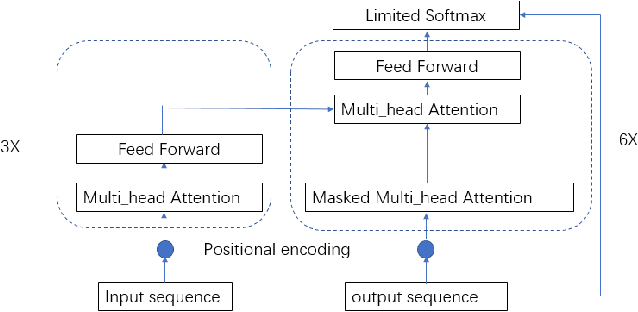

The dominant automatic lexical stress detection method is to split the utterance into syllable segments using phoneme sequence and their time-aligned boundaries. Then we extract features from syllable to use classification method to classify the lexical stress. However, we can't get very accurate time boundaries of each phoneme and we have to design some features in the syllable segments to classify the lexical stress. Therefore, we propose a end-to-end approach using sequence to sequence model of transformer to estimate lexical stress. For this, we train transformer model using feature sequence of audio and their phoneme sequence with lexical stress marks. During the recognition process, the recognized phoneme sequence is restricted according to the original standard phoneme sequence without lexical stress marks, but the lexical stress mark of each phoneme is not limited. We train the model in different subset of Librispeech and do lexical stress recognition in TIMIT and L2-ARCTIC dataset. For all subsets, the end-to-end model will perform better than the syllable segments classification method. Our method can achieve a 6.36% phoneme error rate on the TIMIT dataset, which exceeds the 7.2% error rate in other studies.