 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid System of Sound Event Detection Transformer and Frame-wise Model for DCASE 2022 Task 4
Oct 18, 2022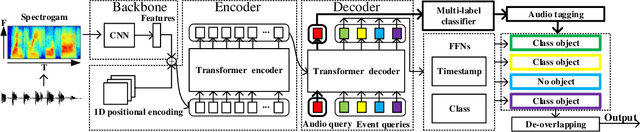
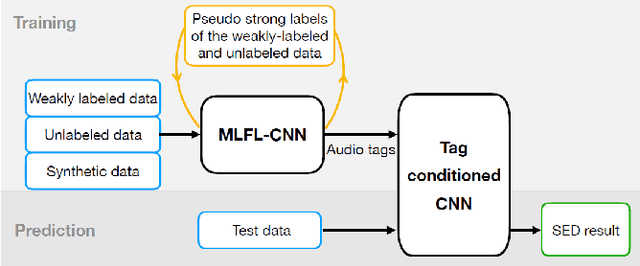
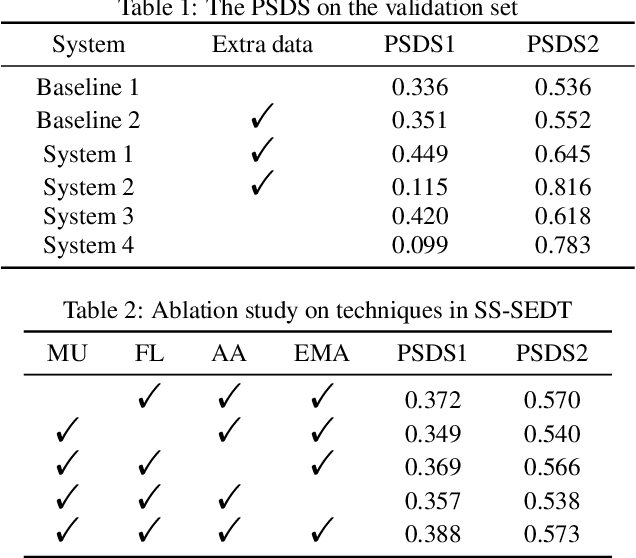

In this paper, we describe in detail our system for DCASE 2022 Task4. The system combines two considerably different models: an end-to-end Sound Event Detection Transformer (SEDT) and a frame-wise model, Metric Learning and Focal Loss CNN (MLFL-CNN). The former is an event-wise model which learns event-level representations and predicts sound event categories and boundaries directly, while the latter is based on the widely adopted frame-classification scheme, under which each frame is classified into event categories and event boundaries are obtained by post-processing such as thresholding and smoothing. For SEDT, self-supervised pre-training using unlabeled data is applied, and semi-supervised learning is adopted by using an online teacher, which is updated from the student model using the Exponential Moving Average (EMA) strategy and generates reliable pseudo labels for weakly-labeled and unlabeled data. For the frame-wise model, the ICT-TOSHIBA system of DCASE 2021 Task 4 is used. Experimental results show that the hybrid system considerably outperforms either individual model and achieves psds1 of 0.420 and psds2 of 0.783 on the validation set without external data. The code is available at https://github.com/965694547/Hybrid-system-of-frame-wise-model-and-SEDT.
SP-SEDT: Self-supervised Pre-training for Sound Event Detection Transformer
Nov 30, 2021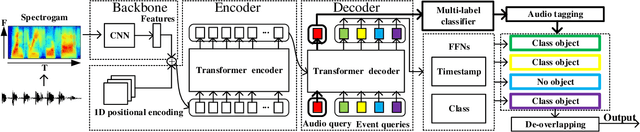
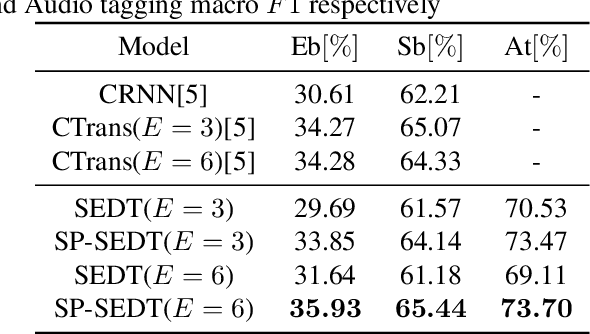
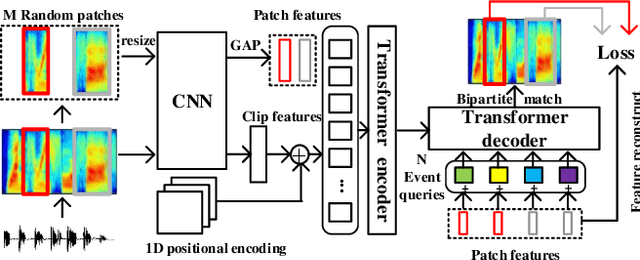
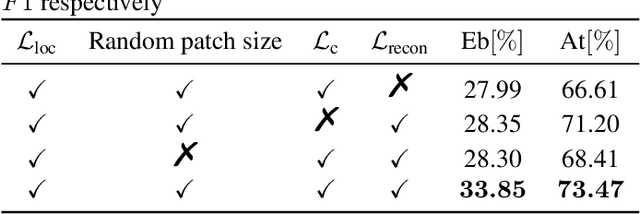
Recently, an event-based end-to-end model (SEDT) has been proposed for sound event detection (SED) and achieves competitive performance. However, compared with the frame-based model, it requires more training data with temporal annotations to improve the localization ability. Synthetic data is an alternative, but it suffers from a great domain gap with real recordings. Inspired by the great success of UP-DETR in object detection, we propose to self-supervisedly pre-train SEDT (SP-SEDT) by detecting random patches (only cropped along the time axis). Experiments on the DCASE2019 task4 dataset show the proposed SP-SEDT can outperform fine-tuned frame-based model. The ablation study is also conducted to investigate the impact of different loss functions and patch size.
Sound Event Detection Transformer: An Event-based End-to-End Model for Sound Event Detection
Oct 18, 2021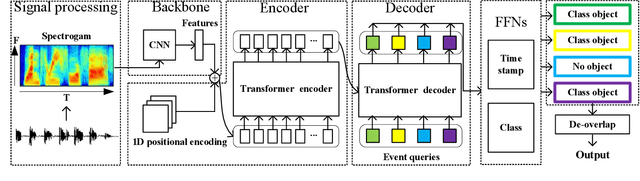

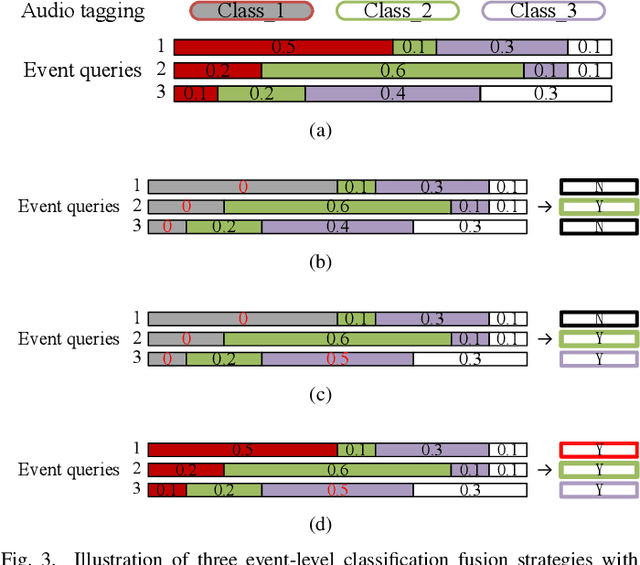

Sound event detection (SED) has gained increasing attention with its wide application in surveillance, video indexing, etc. Existing models in SED mainly generate frame-level predictions, converting it into a sequence multi-label classification problem, which inevitably brings a trade-off between event boundary detection and audio tagging when using weakly labeled data to train the model. Besides, it needs post-processing and cannot be trained in an end-to-end way. This paper firstly presents the 1D Detection Transformer (1D-DETR), inspired by Detection Transformer. Furthermore, given the characteristics of SED, the audio query and a one-to-many matching strategy for fine-tuning the model are added to 1D-DETR to form the model of Sound Event Detection Transformer (SEDT), which generates event-level predictions, end-to-end detection. Experiments are conducted on the URBAN-SED dataset and the DCASE2019 Task4 dataset, and both experiments have achieved competitive results compared with SOTA models. The application of SEDT on SED shows that it can be used as a framework for one-dimensional signal detection and may be extended to other similar tasks.
An End-to-end Approach for Lexical Stress Detection based on Transformer
Nov 06, 2019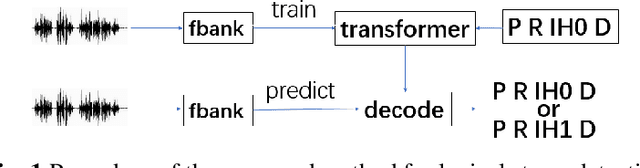
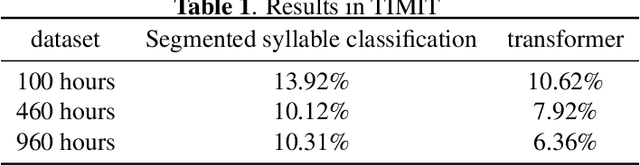
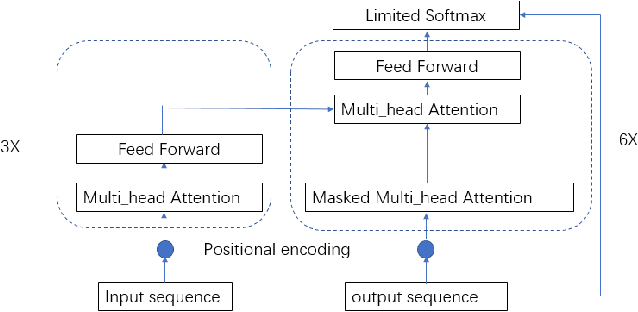

The dominant automatic lexical stress detection method is to split the utterance into syllable segments using phoneme sequence and their time-aligned boundaries. Then we extract features from syllable to use classification method to classify the lexical stress. However, we can't get very accurate time boundaries of each phoneme and we have to design some features in the syllable segments to classify the lexical stress. Therefore, we propose a end-to-end approach using sequence to sequence model of transformer to estimate lexical stress. For this, we train transformer model using feature sequence of audio and their phoneme sequence with lexical stress marks. During the recognition process, the recognized phoneme sequence is restricted according to the original standard phoneme sequence without lexical stress marks, but the lexical stress mark of each phoneme is not limited. We train the model in different subset of Librispeech and do lexical stress recognition in TIMIT and L2-ARCTIC dataset. For all subsets, the end-to-end model will perform better than the syllable segments classification method. Our method can achieve a 6.36% phoneme error rate on the TIMIT dataset, which exceeds the 7.2% error rate in other studies.
Guided Learning Convolution System for DCASE 2019 Task 4
Sep 11, 2019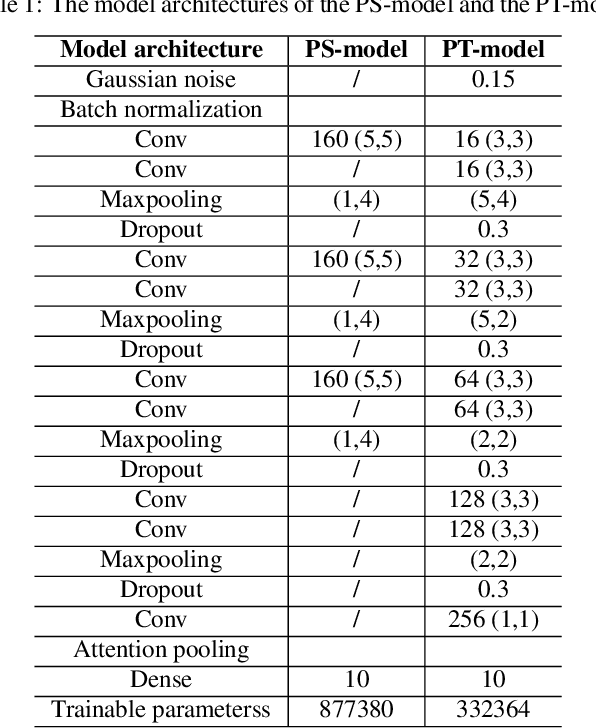


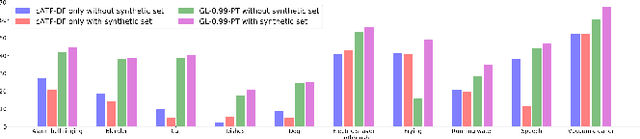
In this paper, we describe in detail the system we submitted to DCASE2019 task 4: sound event detection (SED) in domestic environments. We employ a convolutional neural network (CNN) with an embedding-level attention pooling module to solve it. By considering the interference caused by the co-occurrence of multiple events in the unbalanced dataset, we utilize the disentangled feature to raise the performance of the model. To take advantage of the unlabeled data, we adopt Guided Learning for semi-supervised learning. A group of median filters with adaptive window sizes is utilized in the post-processing of output probabilities of the model. We also analyze the effect of the synthetic data on the performance of the model and finally achieve an event-based F-measure of 45.43% on the validation set and an event-based F-measure of 42.7% on the test set. The system we submitted to the challenge achieves the best performance compared to those of other participates.
Guided Learning for the combination of weakly-supervised and semi-supervised learning
Jul 16, 2019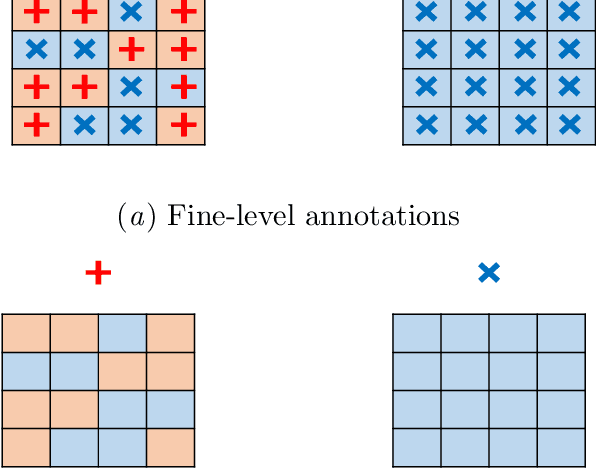
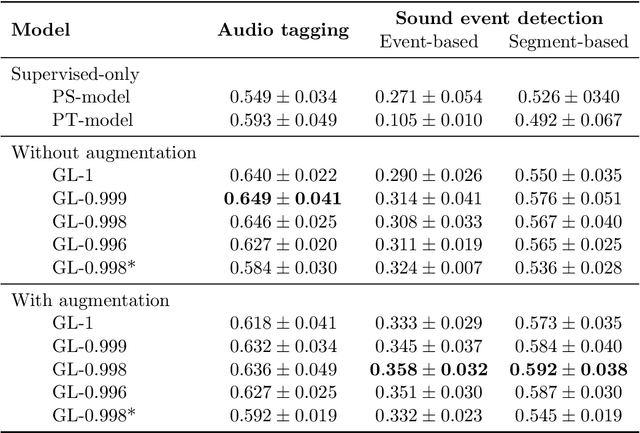
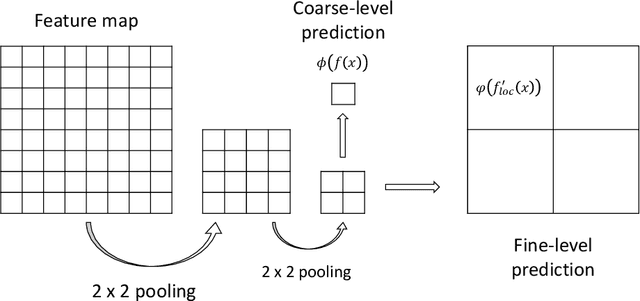
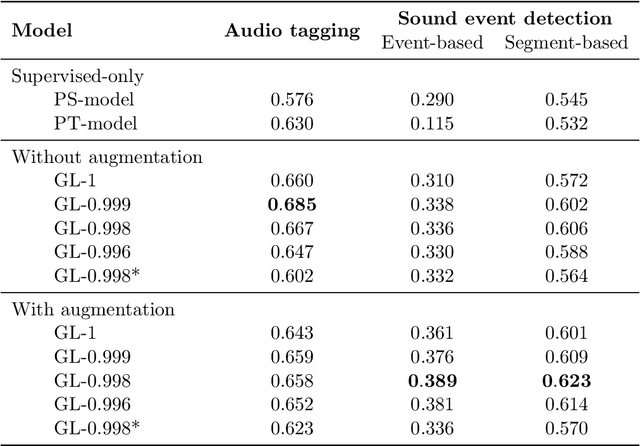
We propose a simple but efficient method to combine semi-supervised learning with weakly-supervised learning for deep neural networks. Weakly-supervised learning is to solve the task which requires fine-level prediction with only coarse-level annotations available. Designing deep neural networks for weakly-supervised learning is always accompanied by a trade-off between fine-level information detection performance and coarse-level classification accuracy. While combining weakly-supervised learning with semi-supervised learning using unlabeled data, in contrast to seeking for this trade-off, we design two different models for different targets. One merely pursues finer information detection performance as the final target, while another one is more professional in achieving higher coarse-level classification accuracy so that it is regarded as a more professional teacher to teach the former model using unlabeled data. We present an end-to-end semi-supervised learning process termed Guided Learning for these two different models to improve the training efficiency. Our approach outperforms the first place result on DCASE2018 Task 4 which employs Mean Teacher with a well-design CRNN network from 32.4% to 38.9%, achieving state-of-the-art performance.
Disentangled Feature for Weakly Supervised Multi-class Sound Event Detection
Jun 03, 2019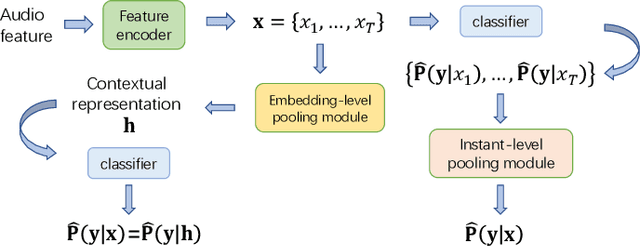
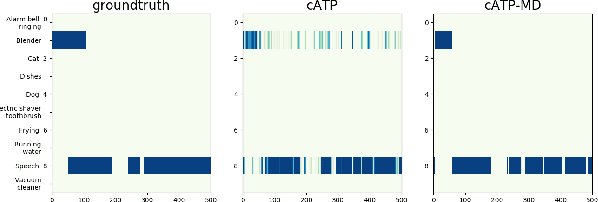
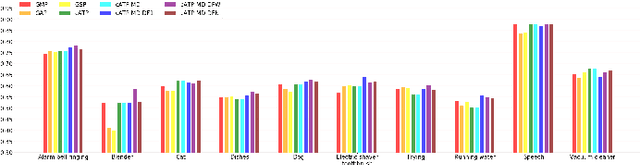
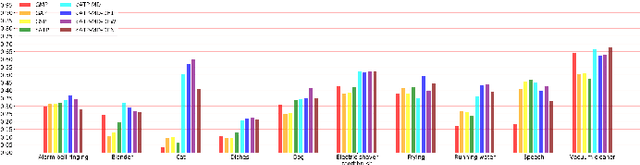
We propose a disentangled feature for weakly supervised multiclass sound event detection (SED), which helps ameliorate the performance and the training efficiency of class-wise attention based detection system by the introduction of more class-wise prior information as well as the network redundancy weight reduction. In this paper, we approach SED as a multiple instance learning (MIL) problem and utilize a neural network framework with class-wise attention pooling (cATP) module to solve it. Aiming at making finer detection even if there is only a small number of clips with less co-occurrence of the categories available in the training set, we optimize the high-level feature space of cATP-MIL by disentangling it based on class-wise identifiable information in the training set and obtain multiple different subspaces. Experiments show that our approach achieves competitive performance on Task4 of the DCASE2018 challenge.