 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSP-SEDT: Self-supervised Pre-training for Sound Event Detection Transformer
Paper and Code
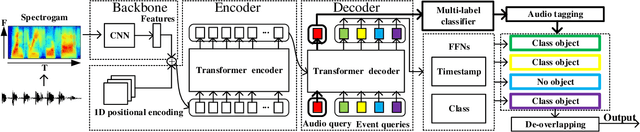
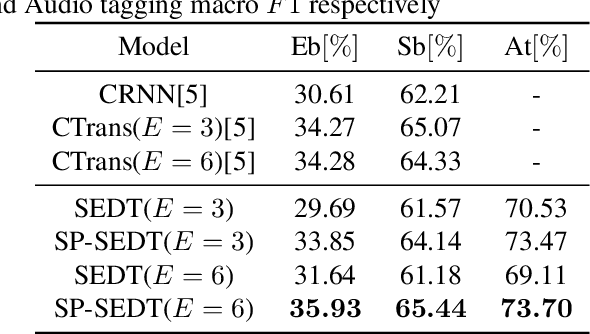
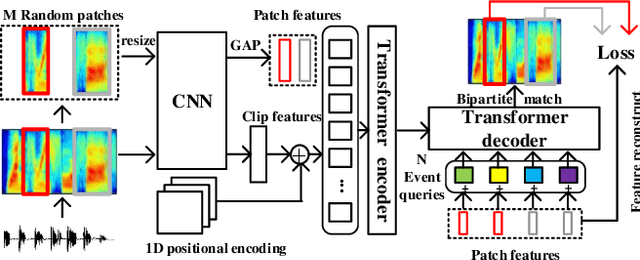
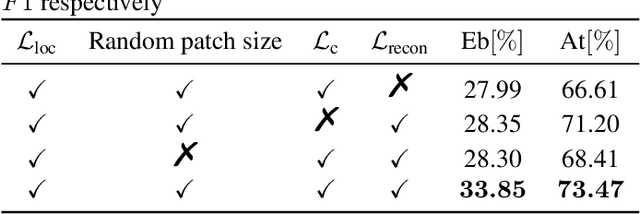
Recently, an event-based end-to-end model (SEDT) has been proposed for sound event detection (SED) and achieves competitive performance. However, compared with the frame-based model, it requires more training data with temporal annotations to improve the localization ability. Synthetic data is an alternative, but it suffers from a great domain gap with real recordings. Inspired by the great success of UP-DETR in object detection, we propose to self-supervisedly pre-train SEDT (SP-SEDT) by detecting random patches (only cropped along the time axis). Experiments on the DCASE2019 task4 dataset show the proposed SP-SEDT can outperform fine-tuned frame-based model. The ablation study is also conducted to investigate the impact of different loss functions and patch size.