 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIFThinker: Spatially-Aware Image Focus for Visual Reasoning
Aug 08, 2025Current multimodal large language models (MLLMs) still face significant challenges in complex visual tasks (e.g., spatial understanding, fine-grained perception). Prior methods have tried to incorporate visual reasoning, however, they fail to leverage attention correction with spatial cues to iteratively refine their focus on prompt-relevant regions. In this paper, we introduce SIFThinker, a spatially-aware "think-with-images" framework that mimics human visual perception. Specifically, SIFThinker enables attention correcting and image region focusing by interleaving depth-enhanced bounding boxes and natural language. Our contributions are twofold: First, we introduce a reverse-expansion-forward-inference strategy that facilitates the generation of interleaved image-text chains of thought for process-level supervision, which in turn leads to the construction of the SIF-50K dataset. Besides, we propose GRPO-SIF, a reinforced training paradigm that integrates depth-informed visual grounding into a unified reasoning pipeline, teaching the model to dynamically correct and focus on prompt-relevant regions. Extensive experiments demonstrate that SIFThinker outperforms state-of-the-art methods in spatial understanding and fine-grained visual perception, while maintaining strong general capabilities, highlighting the effectiveness of our method.
Is Cognition consistent with Perception? Assessing and Mitigating Multimodal Knowledge Conflicts in Document Understanding
Nov 12, 2024



Multimodal large language models (MLLMs) have shown impressive capabilities in document understanding, a rapidly growing research area with significant industrial demand in recent years. As a multimodal task, document understanding requires models to possess both perceptual and cognitive abilities. However, current MLLMs often face conflicts between perception and cognition. Taking a document VQA task (cognition) as an example, an MLLM might generate answers that do not match the corresponding visual content identified by its OCR (perception). This conflict suggests that the MLLM might struggle to establish an intrinsic connection between the information it "sees" and what it "understands." Such conflicts challenge the intuitive notion that cognition is consistent with perception, hindering the performance and explainability of MLLMs. In this paper, we define the conflicts between cognition and perception as Cognition and Perception (C&P) knowledge conflicts, a form of multimodal knowledge conflicts, and systematically assess them with a focus on document understanding. Our analysis reveals that even GPT-4o, a leading MLLM, achieves only 68.6% C&P consistency. To mitigate the C&P knowledge conflicts, we propose a novel method called Multimodal Knowledge Consistency Fine-tuning. This method first ensures task-specific consistency and then connects the cognitive and perceptual knowledge. Our method significantly reduces C&P knowledge conflicts across all tested MLLMs and enhances their performance in both cognitive and perceptual tasks in most scenarios.
ProcTag: Process Tagging for Assessing the Efficacy of Document Instruction Data
Jul 17, 2024

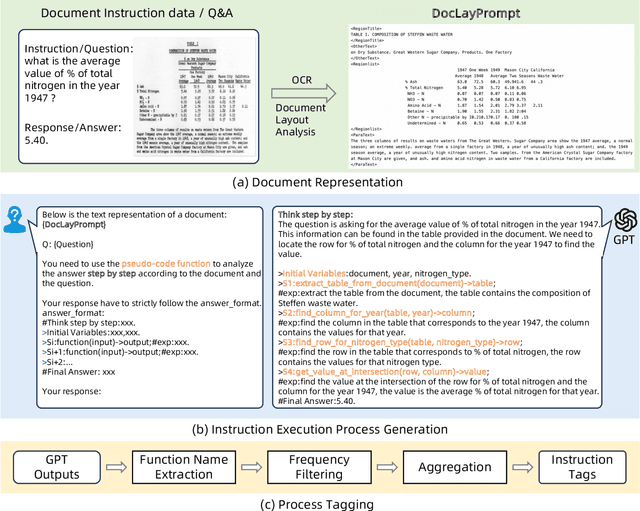

Recently, large language models (LLMs) and multimodal large language models (MLLMs) have demonstrated promising results on document visual question answering (VQA) task, particularly after training on document instruction datasets. An effective evaluation method for document instruction data is crucial in constructing instruction data with high efficacy, which, in turn, facilitates the training of LLMs and MLLMs for document VQA. However, most existing evaluation methods for instruction data are limited to the textual content of the instructions themselves, thereby hindering the effective assessment of document instruction datasets and constraining their construction. In this paper, we propose ProcTag, a data-oriented method that assesses the efficacy of document instruction data. ProcTag innovatively performs tagging on the execution process of instructions rather than the instruction text itself. By leveraging the diversity and complexity of these tags to assess the efficacy of the given dataset, ProcTag enables selective sampling or filtering of document instructions. Furthermore, DocLayPrompt, a novel semi-structured layout-aware document prompting strategy, is proposed for effectively representing documents. Experiments demonstrate that sampling existing open-sourced and generated document VQA/instruction datasets with ProcTag significantly outperforms current methods for evaluating instruction data. Impressively, with ProcTag-based sampling in the generated document datasets, only 30.5\% of the document instructions are required to achieve 100\% efficacy compared to the complete dataset. The code is publicly available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/ProcTag.
LayoutLLM: Layout Instruction Tuning with Large Language Models for Document Understanding
Apr 08, 2024Recently, leveraging large language models (LLMs) or multimodal large language models (MLLMs) for document understanding has been proven very promising. However, previous works that employ LLMs/MLLMs for document understanding have not fully explored and utilized the document layout information, which is vital for precise document understanding. In this paper, we propose LayoutLLM, an LLM/MLLM based method for document understanding. The core of LayoutLLM is a layout instruction tuning strategy, which is specially designed to enhance the comprehension and utilization of document layouts. The proposed layout instruction tuning strategy consists of two components: Layout-aware Pre-training and Layout-aware Supervised Fine-tuning. To capture the characteristics of document layout in Layout-aware Pre-training, three groups of pre-training tasks, corresponding to document-level, region-level and segment-level information, are introduced. Furthermore, a novel module called layout chain-of-thought (LayoutCoT) is devised to enable LayoutLLM to focus on regions relevant to the question and generate accurate answers. LayoutCoT is effective for boosting the performance of document understanding. Meanwhile, it brings a certain degree of interpretability, which could facilitate manual inspection and correction. Experiments on standard benchmarks show that the proposed LayoutLLM significantly outperforms existing methods that adopt open-source 7B LLMs/MLLMs for document understanding. The training data of the LayoutLLM is publicly available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/LayoutLLM
Vision Grid Transformer for Document Layout Analysis
Aug 29, 2023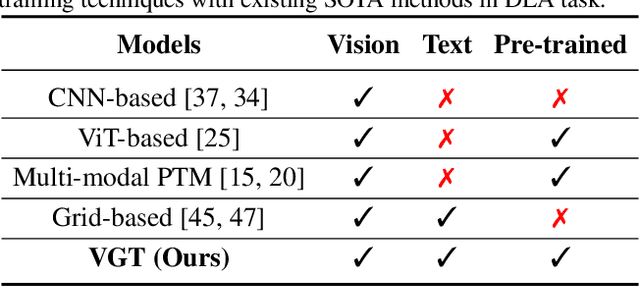



Document pre-trained models and grid-based models have proven to be very effective on various tasks in Document AI. However, for the document layout analysis (DLA) task, existing document pre-trained models, even those pre-trained in a multi-modal fashion, usually rely on either textual features or visual features. Grid-based models for DLA are multi-modality but largely neglect the effect of pre-training. To fully leverage multi-modal information and exploit pre-training techniques to learn better representation for DLA, in this paper, we present VGT, a two-stream Vision Grid Transformer, in which Grid Transformer (GiT) is proposed and pre-trained for 2D token-level and segment-level semantic understanding. Furthermore, a new dataset named D$^4$LA, which is so far the most diverse and detailed manually-annotated benchmark for document layout analysis, is curated and released. Experiment results have illustrated that the proposed VGT model achieves new state-of-the-art results on DLA tasks, e.g. PubLayNet ($95.7\%$$\rightarrow$$96.2\%$), DocBank ($79.6\%$$\rightarrow$$84.1\%$), and D$^4$LA ($67.7\%$$\rightarrow$$68.8\%$). The code and models as well as the D$^4$LA dataset will be made publicly available ~\url{https://github.com/AlibabaResearch/AdvancedLiterateMachinery}.
GeoLayoutLM: Geometric Pre-training for Visual Information Extraction
Apr 21, 2023



Visual information extraction (VIE) plays an important role in Document Intelligence. Generally, it is divided into two tasks: semantic entity recognition (SER) and relation extraction (RE). Recently, pre-trained models for documents have achieved substantial progress in VIE, particularly in SER. However, most of the existing models learn the geometric representation in an implicit way, which has been found insufficient for the RE task since geometric information is especially crucial for RE. Moreover, we reveal another factor that limits the performance of RE lies in the objective gap between the pre-training phase and the fine-tuning phase for RE. To tackle these issues, we propose in this paper a multi-modal framework, named GeoLayoutLM, for VIE. GeoLayoutLM explicitly models the geometric relations in pre-training, which we call geometric pre-training. Geometric pre-training is achieved by three specially designed geometry-related pre-training tasks. Additionally, novel relation heads, which are pre-trained by the geometric pre-training tasks and fine-tuned for RE, are elaborately designed to enrich and enhance the feature representation. According to extensive experiments on standard VIE benchmarks, GeoLayoutLM achieves highly competitive scores in the SER task and significantly outperforms the previous state-of-the-arts for RE (\eg, the F1 score of RE on FUNSD is boosted from 80.35\% to 89.45\%). The code and models are publicly available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/GeoLayoutLM
Bi-VLDoc: Bidirectional Vision-Language Modeling for Visually-Rich Document Understanding
Jun 27, 2022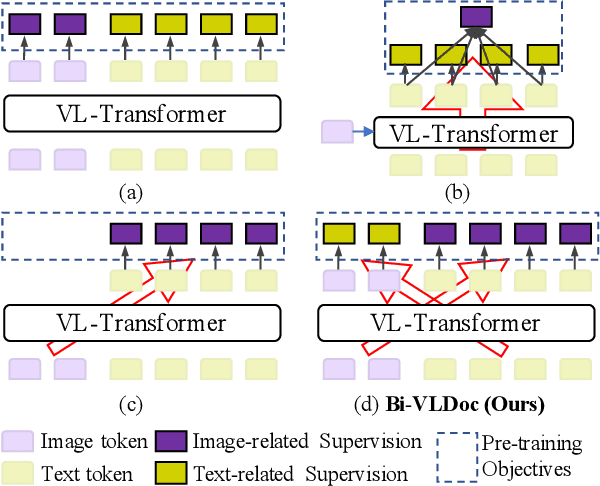
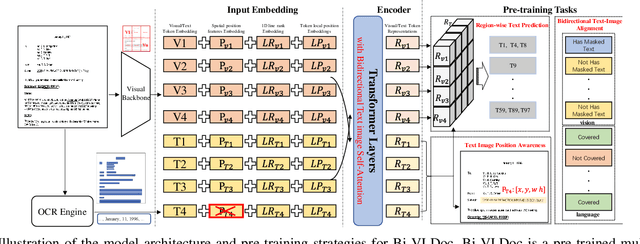
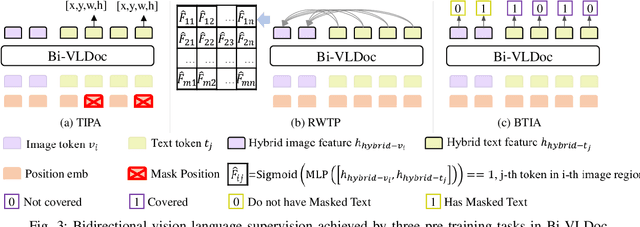
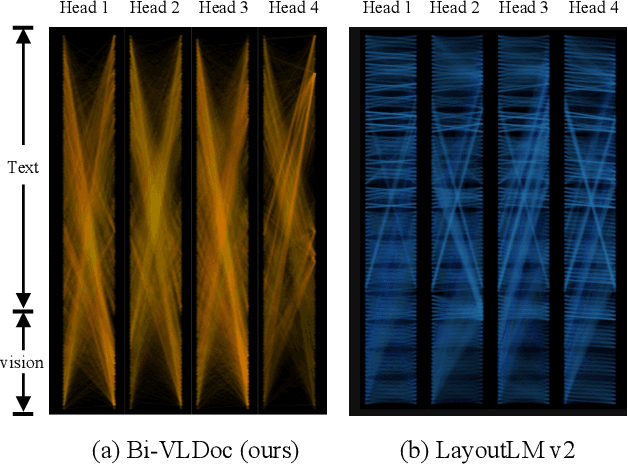
Multi-modal document pre-trained models have proven to be very effective in a variety of visually-rich document understanding (VrDU) tasks. Though existing document pre-trained models have achieved excellent performance on standard benchmarks for VrDU, the way they model and exploit the interactions between vision and language on documents has hindered them from better generalization ability and higher accuracy. In this work, we investigate the problem of vision-language joint representation learning for VrDU mainly from the perspective of supervisory signals. Specifically, a pre-training paradigm called Bi-VLDoc is proposed, in which a bidirectional vision-language supervision strategy and a vision-language hybrid-attention mechanism are devised to fully explore and utilize the interactions between these two modalities, to learn stronger cross-modal document representations with richer semantics. Benefiting from the learned informative cross-modal document representations, Bi-VLDoc significantly advances the state-of-the-art performance on three widely-used document understanding benchmarks, including Form Understanding (from 85.14% to 93.44%), Receipt Information Extraction (from 96.01% to 97.84%), and Document Classification (from 96.08% to 97.12%). On Document Visual QA, Bi-VLDoc achieves the state-of-the-art performance compared to previous single model methods.
Joint Copying and Restricted Generation for Paraphrase
Nov 28, 2016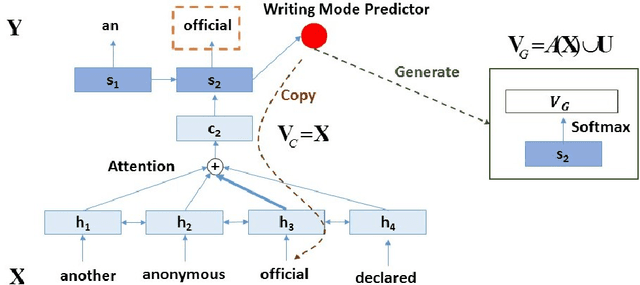

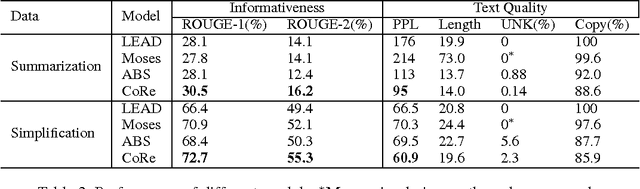
Many natural language generation tasks, such as abstractive summarization and text simplification, are paraphrase-orientated. In these tasks, copying and rewriting are two main writing modes. Most previous sequence-to-sequence (Seq2Seq) models use a single decoder and neglect this fact. In this paper, we develop a novel Seq2Seq model to fuse a copying decoder and a restricted generative decoder. The copying decoder finds the position to be copied based on a typical attention model. The generative decoder produces words limited in the source-specific vocabulary. To combine the two decoders and determine the final output, we develop a predictor to predict the mode of copying or rewriting. This predictor can be guided by the actual writing mode in the training data. We conduct extensive experiments on two different paraphrase datasets. The result shows that our model outperforms the state-of-the-art approaches in terms of both informativeness and language quality.