 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-VLDoc: Bidirectional Vision-Language Modeling for Visually-Rich Document Understanding
Paper and Code
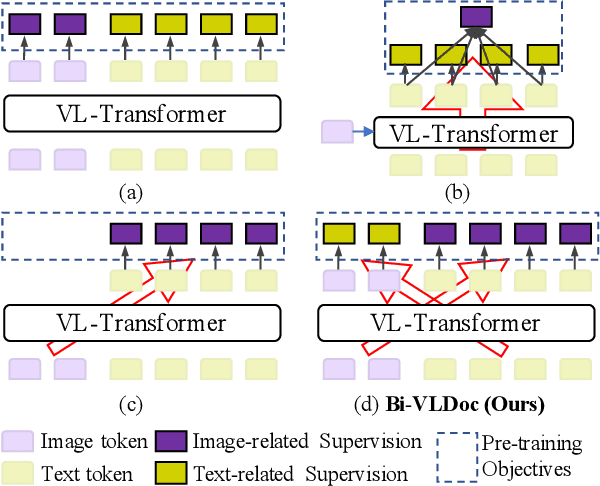
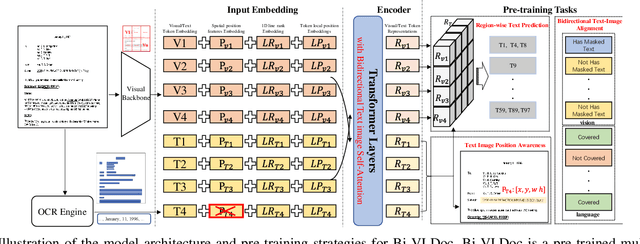
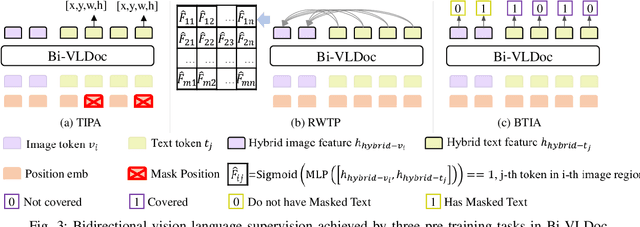
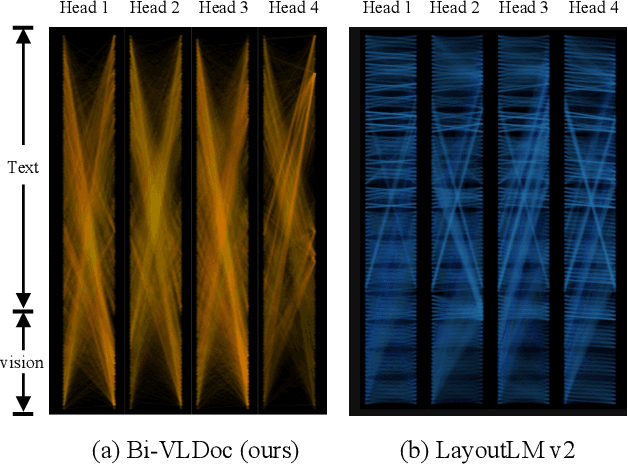
Multi-modal document pre-trained models have proven to be very effective in a variety of visually-rich document understanding (VrDU) tasks. Though existing document pre-trained models have achieved excellent performance on standard benchmarks for VrDU, the way they model and exploit the interactions between vision and language on documents has hindered them from better generalization ability and higher accuracy. In this work, we investigate the problem of vision-language joint representation learning for VrDU mainly from the perspective of supervisory signals. Specifically, a pre-training paradigm called Bi-VLDoc is proposed, in which a bidirectional vision-language supervision strategy and a vision-language hybrid-attention mechanism are devised to fully explore and utilize the interactions between these two modalities, to learn stronger cross-modal document representations with richer semantics. Benefiting from the learned informative cross-modal document representations, Bi-VLDoc significantly advances the state-of-the-art performance on three widely-used document understanding benchmarks, including Form Understanding (from 85.14% to 93.44%), Receipt Information Extraction (from 96.01% to 97.84%), and Document Classification (from 96.08% to 97.12%). On Document Visual QA, Bi-VLDoc achieves the state-of-the-art performance compared to previous single model methods.