 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Grid Transformer for Document Layout Analysis
Paper and Code
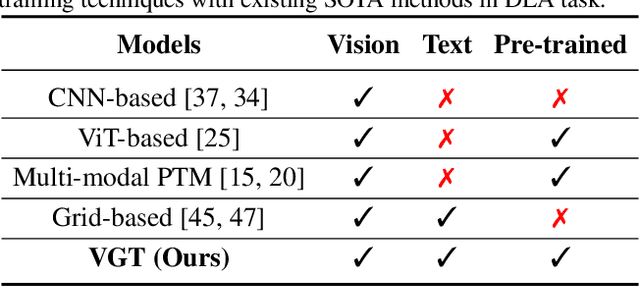



Document pre-trained models and grid-based models have proven to be very effective on various tasks in Document AI. However, for the document layout analysis (DLA) task, existing document pre-trained models, even those pre-trained in a multi-modal fashion, usually rely on either textual features or visual features. Grid-based models for DLA are multi-modality but largely neglect the effect of pre-training. To fully leverage multi-modal information and exploit pre-training techniques to learn better representation for DLA, in this paper, we present VGT, a two-stream Vision Grid Transformer, in which Grid Transformer (GiT) is proposed and pre-trained for 2D token-level and segment-level semantic understanding. Furthermore, a new dataset named D$^4$LA, which is so far the most diverse and detailed manually-annotated benchmark for document layout analysis, is curated and released. Experiment results have illustrated that the proposed VGT model achieves new state-of-the-art results on DLA tasks, e.g. PubLayNet ($95.7\%$$\rightarrow$$96.2\%$), DocBank ($79.6\%$$\rightarrow$$84.1\%$), and D$^4$LA ($67.7\%$$\rightarrow$$68.8\%$). The code and models as well as the D$^4$LA dataset will be made publicly available ~\url{https://github.com/AlibabaResearch/AdvancedLiterateMachinery}.