 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-DeepResearch Benchmark: Rethinking Visual and Textual Search for Multimodal Large Language Models
Feb 02, 2026Multimodal Large Language Models (MLLMs) have advanced VQA and now support Vision-DeepResearch systems that use search engines for complex visual-textual fact-finding. However, evaluating these visual and textual search abilities is still difficult, and existing benchmarks have two major limitations. First, existing benchmarks are not visual search-centric: answers that should require visual search are often leaked through cross-textual cues in the text questions or can be inferred from the prior world knowledge in current MLLMs. Second, overly idealized evaluation scenario: On the image-search side, the required information can often be obtained via near-exact matching against the full image, while the text-search side is overly direct and insufficiently challenging. To address these issues, we construct the Vision-DeepResearch benchmark (VDR-Bench) comprising 2,000 VQA instances. All questions are created via a careful, multi-stage curation pipeline and rigorous expert review, designed to assess the behavior of Vision-DeepResearch systems under realistic real-world conditions. Moreover, to address the insufficient visual retrieval capabilities of current MLLMs, we propose a simple multi-round cropped-search workflow. This strategy is shown to effectively improve model performance in realistic visual retrieval scenarios. Overall, our results provide practical guidance for the design of future multimodal deep-research systems. The code will be released in https://github.com/Osilly/Vision-DeepResearch.
ReLaX: Reasoning with Latent Exploration for Large Reasoning Models
Dec 08, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has recently demonstrated remarkable potential in enhancing the reasoning capability of Large Reasoning Models (LRMs). However, RLVR often leads to entropy collapse, resulting in premature policy convergence and performance saturation. While manipulating token-level entropy has proven effective for promoting policy exploration, we argue that the latent dynamics underlying token generation encode a far richer computational structure for steering policy optimization toward a more effective exploration-exploitation tradeoff. To enable tractable analysis and intervention of the latent dynamics of LRMs, we leverage Koopman operator theory to obtain a linearized representation of their hidden-state dynamics. This enables us to introduce Dynamic Spectral Dispersion (DSD), a new metric to quantify the heterogeneity of the model's latent dynamics, serving as a direct indicator of policy exploration. Building upon these foundations, we propose Reasoning with Latent eXploration (ReLaX), a paradigm that explicitly incorporates latent dynamics to regulate exploration and exploitation during policy optimization. Comprehensive experiments across a wide range of multimodal and text-only reasoning benchmarks show that ReLaX significantly mitigates premature convergence and consistently achieves state-of-the-art performance.
Learning on the Job: An Experience-Driven Self-Evolving Agent for Long-Horizon Tasks
Oct 09, 2025Large Language Models have demonstrated remarkable capabilities across diverse domains, yet significant challenges persist when deploying them as AI agents for real-world long-horizon tasks. Existing LLM agents suffer from a critical limitation: they are test-time static and cannot learn from experience, lacking the ability to accumulate knowledge and continuously improve on the job. To address this challenge, we propose MUSE, a novel agent framework that introduces an experience-driven, self-evolving system centered around a hierarchical Memory Module. MUSE organizes diverse levels of experience and leverages them to plan and execute long-horizon tasks across multiple applications. After each sub-task execution, the agent autonomously reflects on its trajectory, converting the raw trajectory into structured experience and integrating it back into the Memory Module. This mechanism enables the agent to evolve beyond its static pretrained parameters, fostering continuous learning and self-evolution. We evaluate MUSE on the long-horizon productivity benchmark TAC. It achieves new SOTA performance by a significant margin using only a lightweight Gemini-2.5 Flash model. Sufficient Experiments demonstrate that as the agent autonomously accumulates experience, it exhibits increasingly superior task completion capabilities, as well as robust continuous learning and self-evolution capabilities. Moreover, the accumulated experience from MUSE exhibits strong generalization properties, enabling zero-shot improvement on new tasks. MUSE establishes a new paradigm for AI agents capable of real-world productivity task automation.
Interleaving Reasoning for Better Text-to-Image Generation
Sep 09, 2025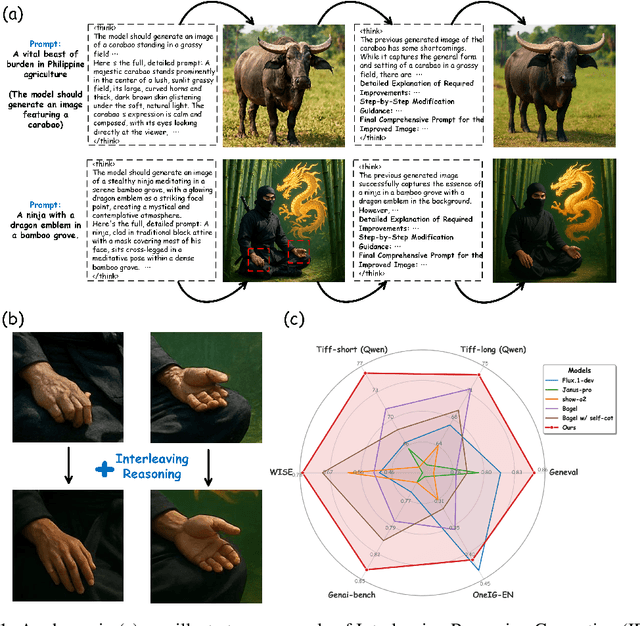
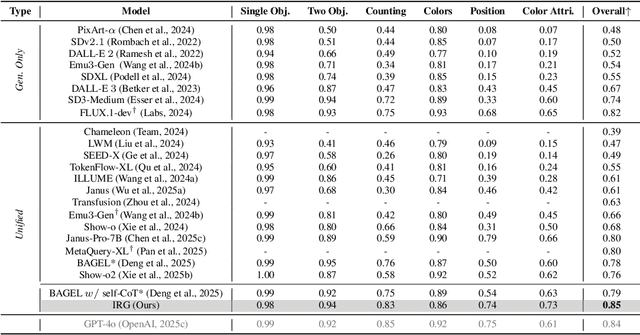

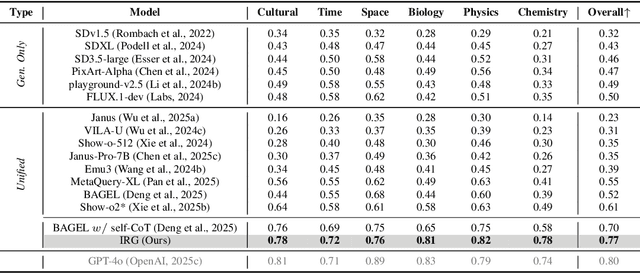
Unified multimodal understanding and generation models recently have achieve significant improvement in image generation capability, yet a large gap remains in instruction following and detail preservation compared to systems that tightly couple comprehension with generation such as GPT-4o. Motivated by recent advances in interleaving reasoning, we explore whether such reasoning can further improve Text-to-Image (T2I) generation. We introduce Interleaving Reasoning Generation (IRG), a framework that alternates between text-based thinking and image synthesis: the model first produces a text-based thinking to guide an initial image, then reflects on the result to refine fine-grained details, visual quality, and aesthetics while preserving semantics. To train IRG effectively, we propose Interleaving Reasoning Generation Learning (IRGL), which targets two sub-goals: (1) strengthening the initial think-and-generate stage to establish core content and base quality, and (2) enabling high-quality textual reflection and faithful implementation of those refinements in a subsequent image. We curate IRGL-300K, a dataset organized into six decomposed learning modes that jointly cover learning text-based thinking, and full thinking-image trajectories. Starting from a unified foundation model that natively emits interleaved text-image outputs, our two-stage training first builds robust thinking and reflection, then efficiently tunes the IRG pipeline in the full thinking-image trajectory data. Extensive experiments show SoTA performance, yielding absolute gains of 5-10 points on GenEval, WISE, TIIF, GenAI-Bench, and OneIG-EN, alongside substantial improvements in visual quality and fine-grained fidelity. The code, model weights and datasets will be released in: https://github.com/Osilly/Interleaving-Reasoning-Generation .
Learning Only with Images: Visual Reinforcement Learning with Reasoning, Rendering, and Visual Feedback
Jul 28, 2025



Multimodal Large Language Models (MLLMs) have exhibited impressive performance across various visual tasks. Subsequent investigations into enhancing their visual reasoning abilities have significantly expanded their performance envelope. However, a critical bottleneck in the advancement of MLLMs toward deep visual reasoning is their heavy reliance on curated image-text supervision. To solve this problem, we introduce a novel framework termed ``Reasoning-Rendering-Visual-Feedback'' (RRVF), which enables MLLMs to learn complex visual reasoning from only raw images. This framework builds on the ``Asymmetry of Verification'' principle to train MLLMs, i.e., verifying the rendered output against a source image is easier than generating it. We demonstrate that this relative ease provides an ideal reward signal for optimization via Reinforcement Learning (RL) training, reducing the reliance on the image-text supervision. Guided by the above principle, RRVF implements a closed-loop iterative process encompassing reasoning, rendering, and visual feedback components, enabling the model to perform self-correction through multi-turn interactions and tool invocation, while this pipeline can be optimized by the GRPO algorithm in an end-to-end manner. Extensive experiments on image-to-code generation for data charts and web interfaces show that RRVF substantially outperforms existing open-source MLLMs and surpasses supervised fine-tuning baselines. Our findings demonstrate that systems driven by purely visual feedback present a viable path toward more robust and generalizable reasoning models without requiring explicit supervision. Code will be available at https://github.com/L-O-I/RRVF.
GDI-Bench: A Benchmark for General Document Intelligence with Vision and Reasoning Decoupling
Apr 30, 2025The rapid advancement of multimodal large language models (MLLMs) has profoundly impacted the document domain, creating a wide array of application scenarios. This progress highlights the need for a comprehensive benchmark to evaluate these models' capabilities across various document-specific tasks. However, existing benchmarks often fail to locate specific model weaknesses or guide systematic improvements. To bridge this gap, we introduce a General Document Intelligence Benchmark (GDI-Bench), featuring 1.9k images across 9 key scenarios and 19 document-specific tasks. By decoupling visual complexity and reasoning complexity, the GDI-Bench structures graded tasks that allow performance assessment by difficulty, aiding in model weakness identification and optimization guidance. We evaluate the GDI-Bench on various open-source and closed-source models, conducting decoupled analyses in the visual and reasoning domains. For instance, the GPT-4o model excels in reasoning tasks but exhibits limitations in visual capabilities. To address the diverse tasks and domains in the GDI-Bench, we propose a GDI Model that mitigates the issue of catastrophic forgetting during the supervised fine-tuning (SFT) process through a intelligence-preserving training strategy. Our model achieves state-of-the-art performance on previous benchmarks and the GDI-Bench. Both our benchmark and model will be open source.
ProcTag: Process Tagging for Assessing the Efficacy of Document Instruction Data
Jul 17, 2024

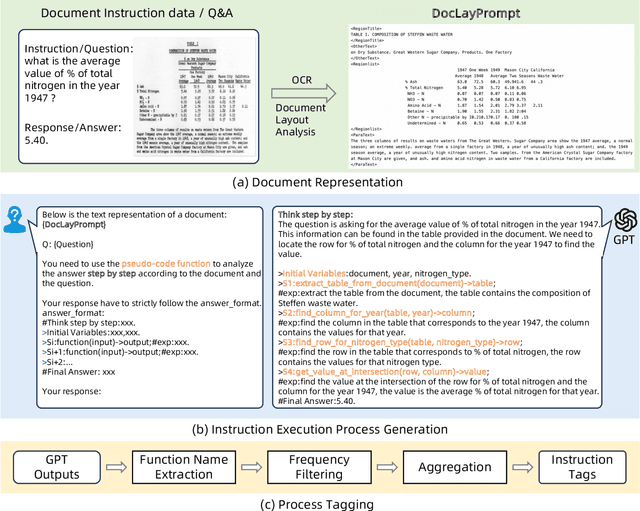

Recently, large language models (LLMs) and multimodal large language models (MLLMs) have demonstrated promising results on document visual question answering (VQA) task, particularly after training on document instruction datasets. An effective evaluation method for document instruction data is crucial in constructing instruction data with high efficacy, which, in turn, facilitates the training of LLMs and MLLMs for document VQA. However, most existing evaluation methods for instruction data are limited to the textual content of the instructions themselves, thereby hindering the effective assessment of document instruction datasets and constraining their construction. In this paper, we propose ProcTag, a data-oriented method that assesses the efficacy of document instruction data. ProcTag innovatively performs tagging on the execution process of instructions rather than the instruction text itself. By leveraging the diversity and complexity of these tags to assess the efficacy of the given dataset, ProcTag enables selective sampling or filtering of document instructions. Furthermore, DocLayPrompt, a novel semi-structured layout-aware document prompting strategy, is proposed for effectively representing documents. Experiments demonstrate that sampling existing open-sourced and generated document VQA/instruction datasets with ProcTag significantly outperforms current methods for evaluating instruction data. Impressively, with ProcTag-based sampling in the generated document datasets, only 30.5\% of the document instructions are required to achieve 100\% efficacy compared to the complete dataset. The code is publicly available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/ProcTag.
LayoutLLM: Layout Instruction Tuning with Large Language Models for Document Understanding
Apr 08, 2024Recently, leveraging large language models (LLMs) or multimodal large language models (MLLMs) for document understanding has been proven very promising. However, previous works that employ LLMs/MLLMs for document understanding have not fully explored and utilized the document layout information, which is vital for precise document understanding. In this paper, we propose LayoutLLM, an LLM/MLLM based method for document understanding. The core of LayoutLLM is a layout instruction tuning strategy, which is specially designed to enhance the comprehension and utilization of document layouts. The proposed layout instruction tuning strategy consists of two components: Layout-aware Pre-training and Layout-aware Supervised Fine-tuning. To capture the characteristics of document layout in Layout-aware Pre-training, three groups of pre-training tasks, corresponding to document-level, region-level and segment-level information, are introduced. Furthermore, a novel module called layout chain-of-thought (LayoutCoT) is devised to enable LayoutLLM to focus on regions relevant to the question and generate accurate answers. LayoutCoT is effective for boosting the performance of document understanding. Meanwhile, it brings a certain degree of interpretability, which could facilitate manual inspection and correction. Experiments on standard benchmarks show that the proposed LayoutLLM significantly outperforms existing methods that adopt open-source 7B LLMs/MLLMs for document understanding. The training data of the LayoutLLM is publicly available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/LayoutLLM