 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinkGen: Generalized Thinking for Visual Generation
Dec 29, 2025Recent progress in Multimodal Large Language Models (MLLMs) demonstrates that Chain-of-Thought (CoT) reasoning enables systematic solutions to complex understanding tasks. However, its extension to generation tasks remains nascent and limited by scenario-specific mechanisms that hinder generalization and adaptation. In this work, we present ThinkGen, the first think-driven visual generation framework that explicitly leverages MLLM's CoT reasoning in various generation scenarios. ThinkGen employs a decoupled architecture comprising a pretrained MLLM and a Diffusion Transformer (DiT), wherein the MLLM generates tailored instructions based on user intent, and DiT produces high-quality images guided by these instructions. We further propose a separable GRPO-based training paradigm (SepGRPO), alternating reinforcement learning between the MLLM and DiT modules. This flexible design enables joint training across diverse datasets, facilitating effective CoT reasoning for a wide range of generative scenarios. Extensive experiments demonstrate that ThinkGen achieves robust, state-of-the-art performance across multiple generation benchmarks. Code is available: https://github.com/jiaosiyuu/ThinkGen
Metis-HOME: Hybrid Optimized Mixture-of-Experts for Multimodal Reasoning
Oct 23, 2025Inspired by recent advancements in LLM reasoning, the field of multimodal reasoning has seen remarkable progress, achieving significant performance gains on intricate tasks such as mathematical problem-solving. Despite this progress, current multimodal large reasoning models exhibit two key limitations. They tend to employ computationally expensive reasoning even for simple queries, leading to inefficiency. Furthermore, this focus on specialized reasoning often impairs their broader, more general understanding capabilities. In this paper, we propose Metis-HOME: a Hybrid Optimized Mixture-of-Experts framework designed to address this trade-off. Metis-HOME enables a ''Hybrid Thinking'' paradigm by structuring the original dense model into two distinct expert branches: a thinking branch tailored for complex, multi-step reasoning, and a non-thinking branch optimized for rapid, direct inference on tasks like general VQA and OCR. A lightweight, trainable router dynamically allocates queries to the most suitable expert. We instantiate Metis-HOME by adapting the Qwen2.5-VL-7B into an MoE architecture. Comprehensive evaluations reveal that our approach not only substantially enhances complex reasoning abilities but also improves the model's general capabilities, reversing the degradation trend observed in other reasoning-specialized models. Our work establishes a new paradigm for building powerful and versatile MLLMs, effectively resolving the prevalent reasoning-vs-generalization dilemma.
Metis-RISE: RL Incentivizes and SFT Enhances Multimodal Reasoning Model Learning
Jun 16, 2025Recent advancements in large language models (LLMs) have witnessed a surge in the development of advanced reasoning paradigms, which are now being integrated into multimodal large language models (MLLMs). However, existing approaches often fall short: methods solely employing reinforcement learning (RL) can struggle with sample inefficiency and activating entirely absent reasoning capabilities, while conventional pipelines that initiate with a cold-start supervised fine-tuning (SFT) phase before RL may restrict the model's exploratory capacity and face suboptimal convergence. In this work, we introduce \textbf{Metis-RISE} (\textbf{R}L \textbf{I}ncentivizes and \textbf{S}FT \textbf{E}nhances) for multimodal reasoning model learning. Unlike conventional approaches, Metis-RISE distinctively omits an initial SFT stage, beginning instead with an RL phase (e.g., using a Group Relative Policy Optimization variant) to incentivize and activate the model's latent reasoning capacity. Subsequently, the targeted SFT stage addresses two key challenges identified during RL: (1) \textit{inefficient trajectory sampling} for tasks where the model possesses but inconsistently applies correct reasoning, which we tackle using self-distilled reasoning trajectories from the RL model itself; and (2) \textit{fundamental capability absence}, which we address by injecting expert-augmented knowledge for prompts where the model entirely fails. This strategic application of RL for incentivization followed by SFT for enhancement forms the core of Metis-RISE, leading to two versions of our MLLMs (7B and 72B parameters). Evaluations on the OpenCompass Multimodal Reasoning Leaderboard demonstrate that both models achieve state-of-the-art performance among similar-sized models, with the 72B version ranking fourth overall.
InstructionBench: An Instructional Video Understanding Benchmark
Apr 07, 2025



Despite progress in video large language models (Video-LLMs), research on instructional video understanding, crucial for enhancing access to instructional content, remains insufficient. To address this, we introduce InstructionBench, an Instructional video understanding Benchmark, which challenges models' advanced temporal reasoning within instructional videos characterized by their strict step-by-step flow. Employing GPT-4, we formulate Q\&A pairs in open-ended and multiple-choice formats to assess both Coarse-Grained event-level and Fine-Grained object-level reasoning. Our filtering strategies exclude questions answerable purely by common-sense knowledge, focusing on visual perception and analysis when evaluating Video-LLM models. The benchmark finally contains 5k questions across over 700 videos. We evaluate the latest Video-LLMs on our InstructionBench, finding that closed-source models outperform open-source ones. However, even the best model, GPT-4o, achieves only 53.42\% accuracy, indicating significant gaps in temporal reasoning. To advance the field, we also develop a comprehensive instructional video dataset with over 19k Q\&A pairs from nearly 2.5k videos, using an automated data generation framework, thereby enriching the community's research resources.
TimeMarker: A Versatile Video-LLM for Long and Short Video Understanding with Superior Temporal Localization Ability
Nov 27, 2024



Rapid development of large language models (LLMs) has significantly advanced multimodal large language models (LMMs), particularly in vision-language tasks. However, existing video-language models often overlook precise temporal localization and struggle with videos of varying lengths. We introduce TimeMarker, a versatile Video-LLM designed for high-quality dialogue based on video content, emphasizing temporal localization. TimeMarker integrates Temporal Separator Tokens to enhance temporal awareness, accurately marking specific moments within videos. It employs the AnyLength mechanism for dynamic frame sampling and adaptive token merging, enabling effective handling of both short and long videos. Additionally, TimeMarker utilizes diverse datasets, including further transformed temporal-related video QA datasets, to bolster its temporal understanding capabilities. Image and interleaved data are also employed to further enhance the model's semantic perception ability. Evaluations demonstrate that TimeMarker achieves state-of-the-art performance across multiple benchmarks, excelling in both short and long video categories. Our project page is at \url{https://github.com/TimeMarker-LLM/TimeMarker/}.
VidCompress: Memory-Enhanced Temporal Compression for Video Understanding in Large Language Models
Oct 15, 2024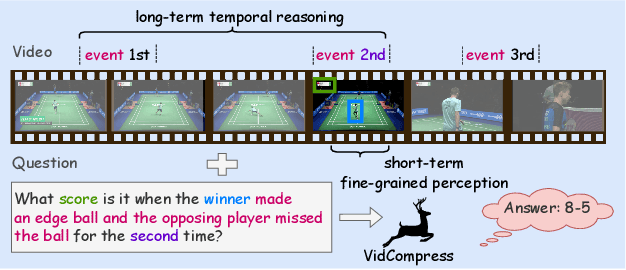
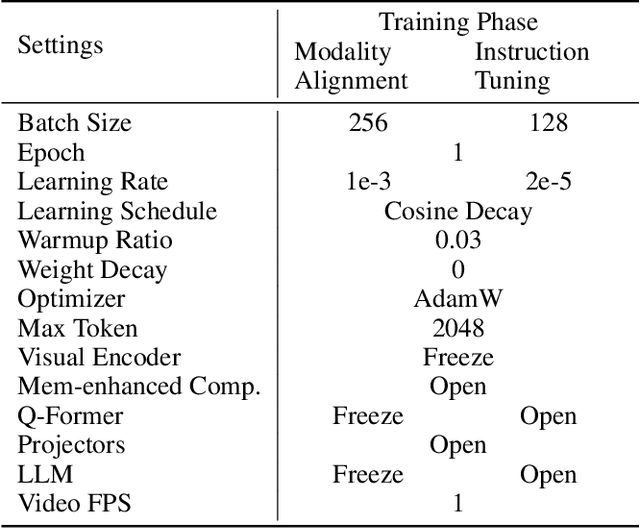
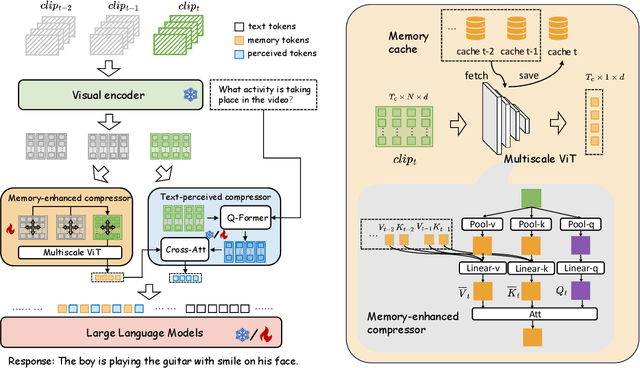
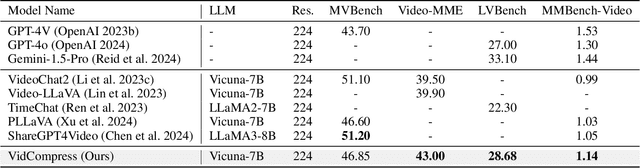
Video-based multimodal large language models (Video-LLMs) possess significant potential for video understanding tasks. However, most Video-LLMs treat videos as a sequential set of individual frames, which results in insufficient temporal-spatial interaction that hinders fine-grained comprehension and difficulty in processing longer videos due to limited visual token capacity. To address these challenges, we propose VidCompress, a novel Video-LLM featuring memory-enhanced temporal compression. VidCompress employs a dual-compressor approach: a memory-enhanced compressor captures both short-term and long-term temporal relationships in videos and compresses the visual tokens using a multiscale transformer with a memory-cache mechanism, while a text-perceived compressor generates condensed visual tokens by utilizing Q-Former and integrating temporal contexts into query embeddings with cross attention. Experiments on several VideoQA datasets and comprehensive benchmarks demonstrate that VidCompress efficiently models complex temporal-spatial relations and significantly outperforms existing Video-LLMs.
A Closer Look at Debiased Temporal Sentence Grounding in Videos: Dataset, Metric, and Approach
Mar 10, 2022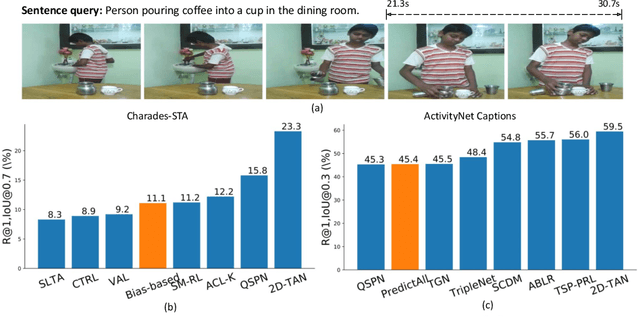
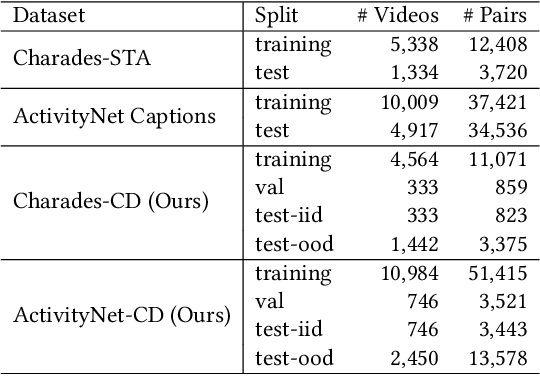
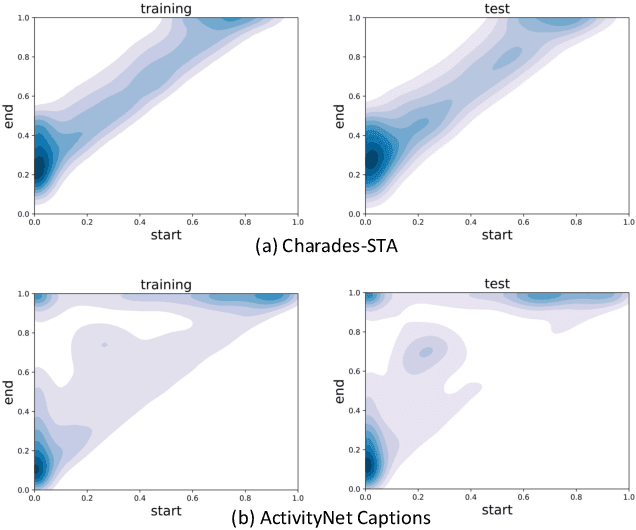
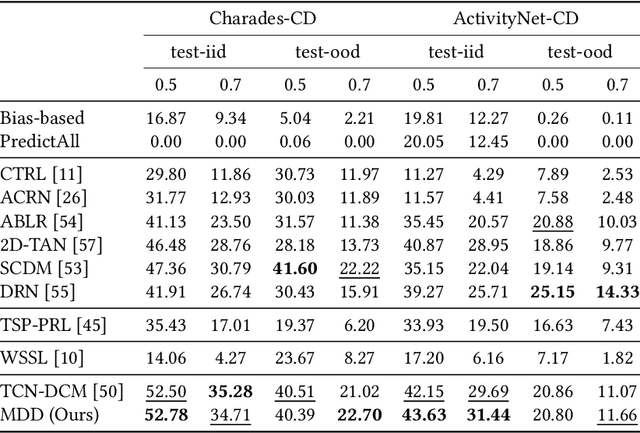
Temporal Sentence Grounding in Videos (TSGV), which aims to ground a natural language sentence in an untrimmed video, has drawn widespread attention over the past few years. However, recent studies have found that current benchmark datasets may have obvious moment annotation biases, enabling several simple baselines even without training to achieve SOTA performance. In this paper, we take a closer look at existing evaluation protocols, and find both the prevailing dataset and evaluation metrics are the devils that lead to untrustworthy benchmarking. Therefore, we propose to re-organize the two widely-used datasets, making the ground-truth moment distributions different in the training and test splits, i.e., out-of-distribution (OOD) test. Meanwhile, we introduce a new evaluation metric "dR@n,IoU@m" that discounts the basic recall scores to alleviate the inflating evaluation caused by biased datasets. New benchmarking results indicate that our proposed evaluation protocols can better monitor the research progress. Furthermore, we propose a novel causality-based Multi-branch Deconfounding Debiasing (MDD) framework for unbiased moment prediction. Specifically, we design a multi-branch deconfounder to eliminate the effects caused by multiple confounders with causal intervention. In order to help the model better align the semantics between sentence queries and video moments, we enhance the representations during feature encoding. Specifically, for textual information, the query is parsed into several verb-centered phrases to obtain a more fine-grained textual feature. For visual information, the positional information has been decomposed from moment features to enhance representations of moments with diverse locations. Extensive experiments demonstrate that our proposed approach can achieve competitive results among existing SOTA approaches and outperform the base model with great gains.
A Survey on Temporal Sentence Grounding in Videos
Sep 17, 2021


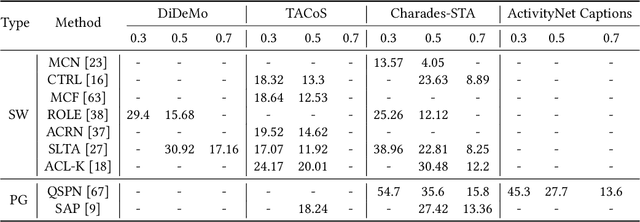
Temporal sentence grounding in videos(TSGV), which aims to localize one target segment from an untrimmed video with respect to a given sentence query, has drawn increasing attentions in the research community over the past few years. Different from the task of temporal action localization, TSGV is more flexible since it can locate complicated activities via natural languages, without restrictions from predefined action categories. Meanwhile, TSGV is more challenging since it requires both textual and visual understanding for semantic alignment between two modalities(i.e., text and video). In this survey, we give a comprehensive overview for TSGV, which i) summarizes the taxonomy of existing methods, ii) provides a detailed description of the evaluation protocols(i.e., datasets and metrics) to be used in TSGV, and iii) in-depth discusses potential problems of current benchmarking designs and research directions for further investigations. To the best of our knowledge, this is the first systematic survey on temporal sentence grounding. More specifically, we first discuss existing TSGV approaches by grouping them into four categories, i.e., two-stage methods, end-to-end methods, reinforcement learning-based methods, and weakly supervised methods. Then we present the benchmark datasets and evaluation metrics to assess current research progress. Finally, we discuss some limitations in TSGV through pointing out potential problems improperly resolved in the current evaluation protocols, which may push forwards more cutting edge research in TSGV. Besides, we also share our insights on several promising directions, including three typical tasks with new and practical settings based on TSGV.
A Closer Look at Temporal Sentence Grounding in Videos: Datasets and Metrics
Jan 27, 2021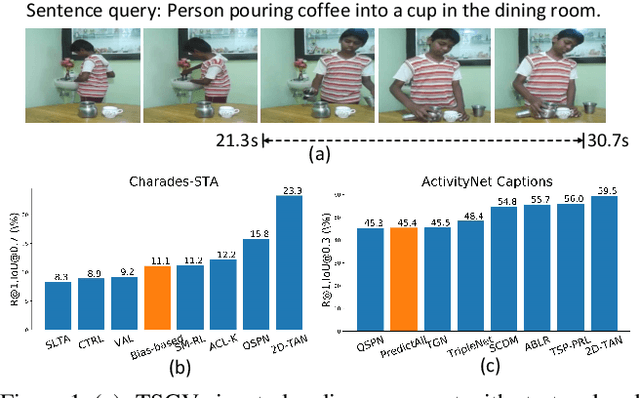
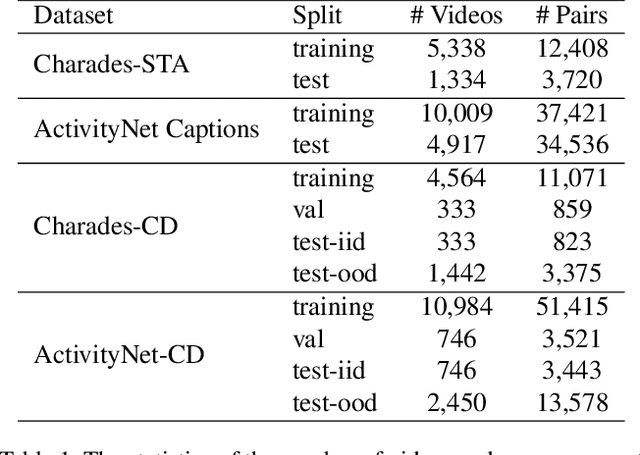
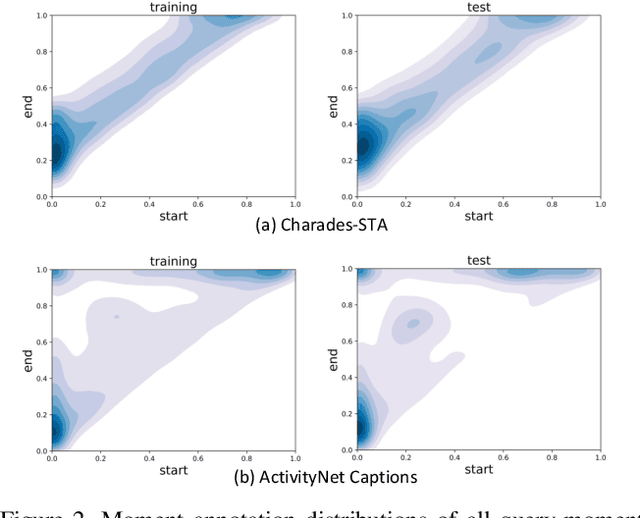
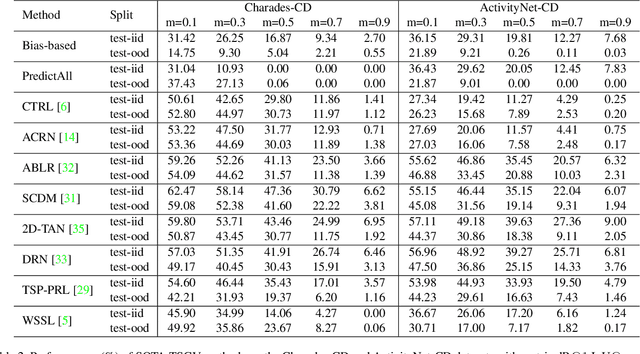
Despite Temporal Sentence Grounding in Videos (TSGV) has realized impressive progress over the last few years, current TSGV models tend to capture the moment annotation biases and fail to take full advantage of multi-modal inputs. Miraculously, some extremely simple TSGV baselines even without training can also achieve state-of-the-art performance. In this paper, we first take a closer look at the existing evaluation protocol, and argue that both the prevailing datasets and metrics are the devils to cause the unreliable benchmarking. To this end, we propose to re-organize two widely-used TSGV datasets (Charades-STA and ActivityNet Captions), and deliberately \textbf{C}hange the moment annotation \textbf{D}istribution of the test split to make it different from the training split, dubbed as Charades-CD and ActivityNet-CD, respectively. Meanwhile, we further introduce a new evaluation metric "dR@$n$,IoU@$m$" to calibrate the basic IoU scores by penalizing more on the over-long moment predictions and reduce the inflating performance caused by the moment annotation biases. Under this new evaluation protocol, we conduct extensive experiments and ablation studies on eight state-of-the-art TSGV models. All the results demonstrate that the re-organized datasets and new metric can better monitor the progress in TSGV, which is still far from satisfactory. The repository of this work is at \url{https://github.com/yytzsy/grounding_changing_distribution}.