 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Temporal Sentence Grounding in Videos: Datasets and Metrics
Paper and Code
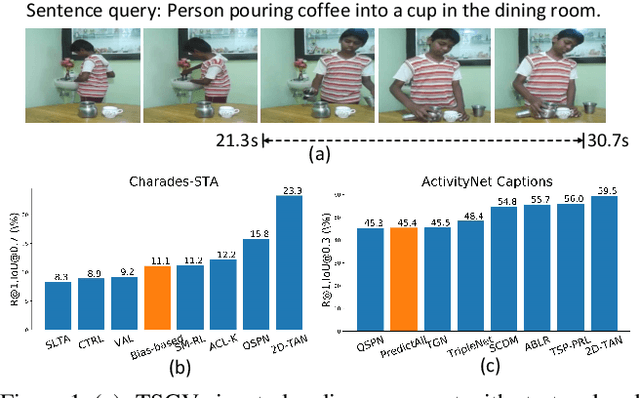
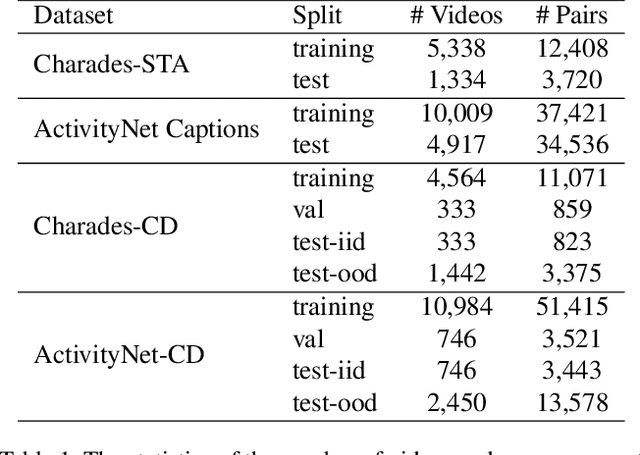
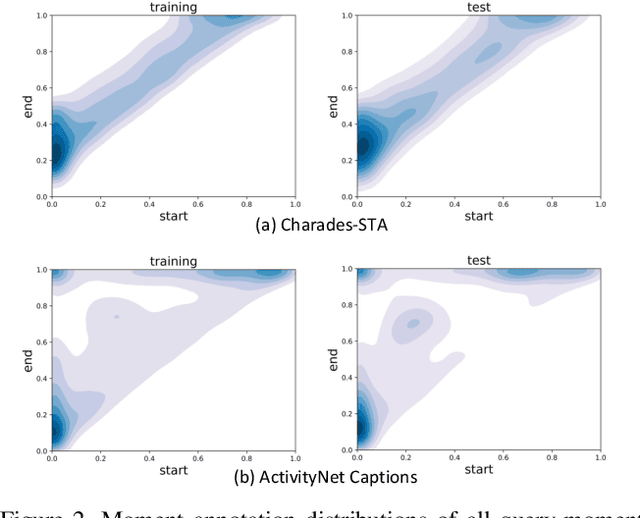
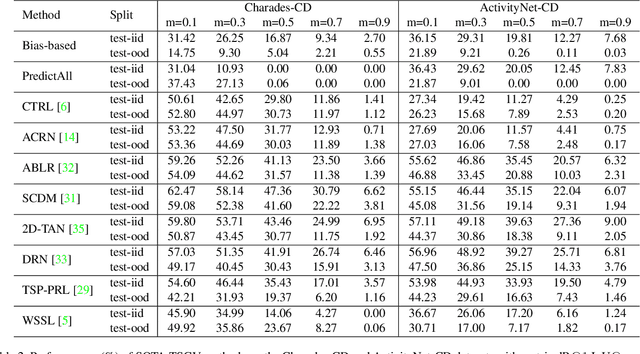
Despite Temporal Sentence Grounding in Videos (TSGV) has realized impressive progress over the last few years, current TSGV models tend to capture the moment annotation biases and fail to take full advantage of multi-modal inputs. Miraculously, some extremely simple TSGV baselines even without training can also achieve state-of-the-art performance. In this paper, we first take a closer look at the existing evaluation protocol, and argue that both the prevailing datasets and metrics are the devils to cause the unreliable benchmarking. To this end, we propose to re-organize two widely-used TSGV datasets (Charades-STA and ActivityNet Captions), and deliberately \textbf{C}hange the moment annotation \textbf{D}istribution of the test split to make it different from the training split, dubbed as Charades-CD and ActivityNet-CD, respectively. Meanwhile, we further introduce a new evaluation metric "dR@$n$,IoU@$m$" to calibrate the basic IoU scores by penalizing more on the over-long moment predictions and reduce the inflating performance caused by the moment annotation biases. Under this new evaluation protocol, we conduct extensive experiments and ablation studies on eight state-of-the-art TSGV models. All the results demonstrate that the re-organized datasets and new metric can better monitor the progress in TSGV, which is still far from satisfactory. The repository of this work is at \url{https://github.com/yytzsy/grounding_changing_distribution}.