 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidCompress: Memory-Enhanced Temporal Compression for Video Understanding in Large Language Models
Paper and Code
Oct 15, 2024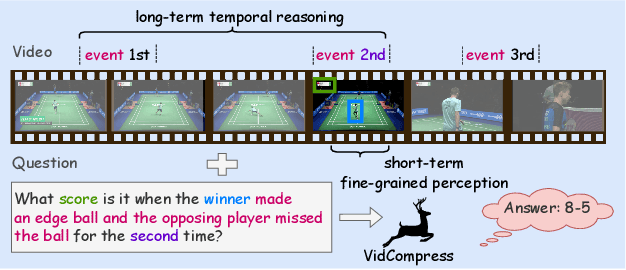
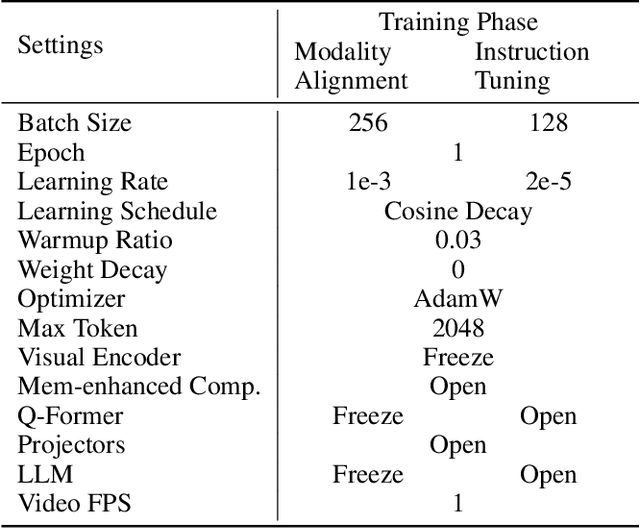
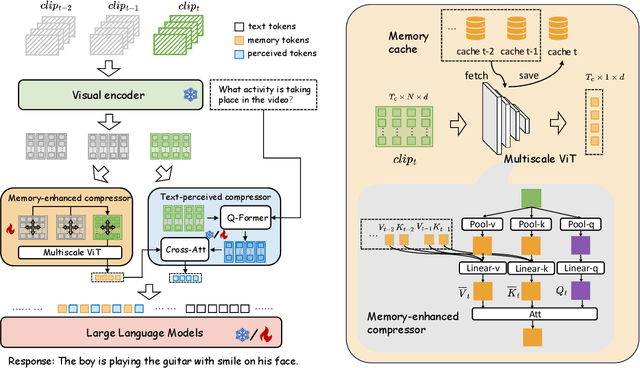
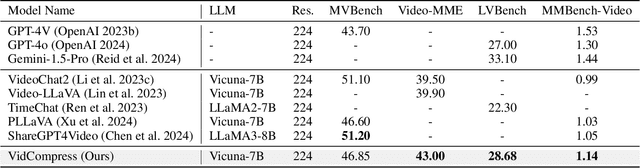
Video-based multimodal large language models (Video-LLMs) possess significant potential for video understanding tasks. However, most Video-LLMs treat videos as a sequential set of individual frames, which results in insufficient temporal-spatial interaction that hinders fine-grained comprehension and difficulty in processing longer videos due to limited visual token capacity. To address these challenges, we propose VidCompress, a novel Video-LLM featuring memory-enhanced temporal compression. VidCompress employs a dual-compressor approach: a memory-enhanced compressor captures both short-term and long-term temporal relationships in videos and compresses the visual tokens using a multiscale transformer with a memory-cache mechanism, while a text-perceived compressor generates condensed visual tokens by utilizing Q-Former and integrating temporal contexts into query embeddings with cross attention. Experiments on several VideoQA datasets and comprehensive benchmarks demonstrate that VidCompress efficiently models complex temporal-spatial relations and significantly outperforms existing Video-LLMs.