 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Debiased Temporal Sentence Grounding in Videos: Dataset, Metric, and Approach
Paper and Code
Mar 10, 2022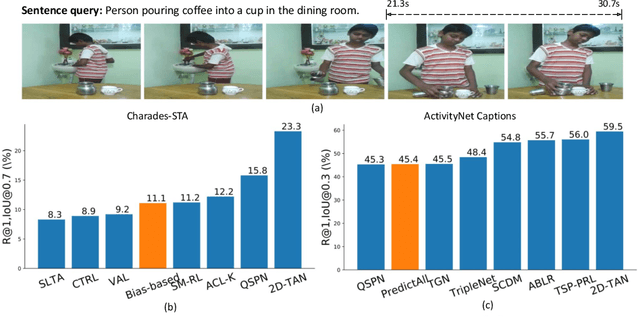
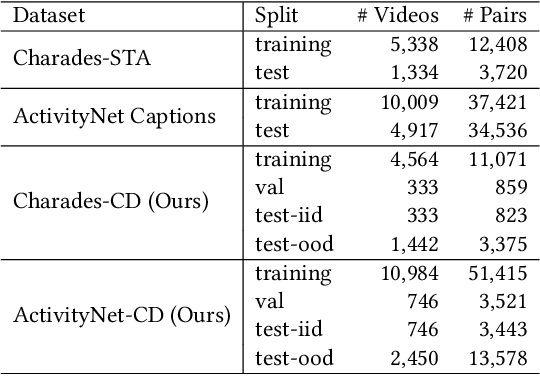
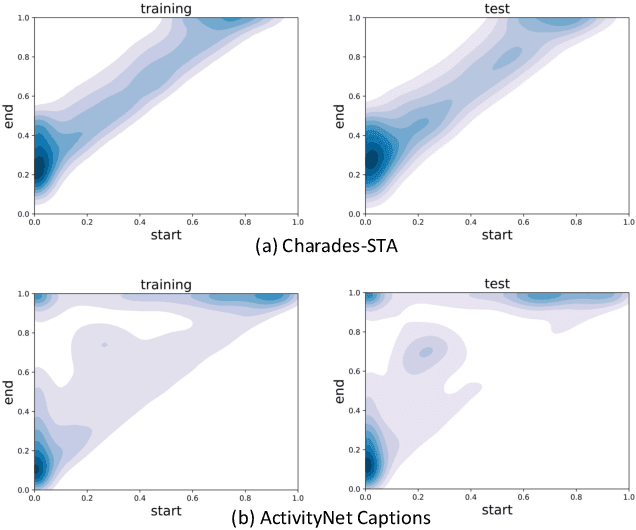
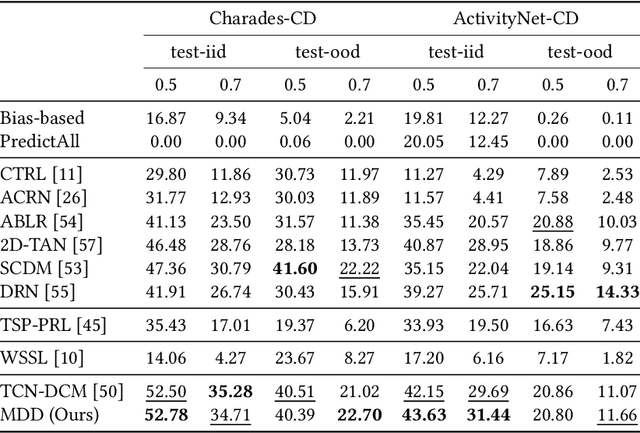
Temporal Sentence Grounding in Videos (TSGV), which aims to ground a natural language sentence in an untrimmed video, has drawn widespread attention over the past few years. However, recent studies have found that current benchmark datasets may have obvious moment annotation biases, enabling several simple baselines even without training to achieve SOTA performance. In this paper, we take a closer look at existing evaluation protocols, and find both the prevailing dataset and evaluation metrics are the devils that lead to untrustworthy benchmarking. Therefore, we propose to re-organize the two widely-used datasets, making the ground-truth moment distributions different in the training and test splits, i.e., out-of-distribution (OOD) test. Meanwhile, we introduce a new evaluation metric "dR@n,IoU@m" that discounts the basic recall scores to alleviate the inflating evaluation caused by biased datasets. New benchmarking results indicate that our proposed evaluation protocols can better monitor the research progress. Furthermore, we propose a novel causality-based Multi-branch Deconfounding Debiasing (MDD) framework for unbiased moment prediction. Specifically, we design a multi-branch deconfounder to eliminate the effects caused by multiple confounders with causal intervention. In order to help the model better align the semantics between sentence queries and video moments, we enhance the representations during feature encoding. Specifically, for textual information, the query is parsed into several verb-centered phrases to obtain a more fine-grained textual feature. For visual information, the positional information has been decomposed from moment features to enhance representations of moments with diverse locations. Extensive experiments demonstrate that our proposed approach can achieve competitive results among existing SOTA approaches and outperform the base model with great gains.