 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciRerankBench: Benchmarking Rerankers Towards Scientific Retrieval-Augmented Generated LLMs
Aug 12, 2025Scientific literature question answering is a pivotal step towards new scientific discoveries. Recently, \textit{two-stage} retrieval-augmented generated large language models (RAG-LLMs) have shown impressive advancements in this domain. Such a two-stage framework, especially the second stage (reranker), is particularly essential in the scientific domain, where subtle differences in terminology may have a greatly negative impact on the final factual-oriented or knowledge-intensive answers. Despite this significant progress, the potential and limitations of these works remain unexplored. In this work, we present a Scientific Rerank-oriented RAG Benchmark (SciRerankBench), for evaluating rerankers within RAG-LLMs systems, spanning five scientific subjects. To rigorously assess the reranker performance in terms of noise resilience, relevance disambiguation, and factual consistency, we develop three types of question-context-answer (Q-C-A) pairs, i.e., Noisy Contexts (NC), Semantically Similar but Logically Irrelevant Contexts (SSLI), and Counterfactual Contexts (CC). Through systematic evaluation of 13 widely used rerankers on five families of LLMs, we provide detailed insights into their relative strengths and limitations. To the best of our knowledge, SciRerankBench is the first benchmark specifically developed to evaluate rerankers within RAG-LLMs, which provides valuable observations and guidance for their future development.
m-KAILIN: Knowledge-Driven Agentic Scientific Corpus Distillation Framework for Biomedical Large Language Models Training
Apr 28, 2025The rapid progress of large language models (LLMs) in biomedical research has underscored the limitations of existing open-source annotated scientific corpora, which are often insufficient in quantity and quality. Addressing the challenge posed by the complex hierarchy of biomedical knowledge, we propose a knowledge-driven, multi-agent framework for scientific corpus distillation tailored for LLM training in the biomedical domain. Central to our approach is a collaborative multi-agent architecture, where specialized agents, each guided by the Medical Subject Headings (MeSH) hierarchy, work in concert to autonomously extract, synthesize, and self-evaluate high-quality textual data from vast scientific literature. These agents collectively generate and refine domain-specific question-answer pairs, ensuring comprehensive coverage and consistency with biomedical ontologies while minimizing manual involvement. Extensive experimental results show that language models trained on our multi-agent distilled datasets achieve notable improvements in biomedical question-answering tasks, outperforming both strong life sciences LLM baselines and advanced proprietary models. Notably, our AI-Ready dataset enables Llama3-70B to surpass GPT-4 with MedPrompt and Med-PaLM-2, despite their larger scale. Detailed ablation studies and case analyses further validate the effectiveness and synergy of each agent within the framework, highlighting the potential of multi-agent collaboration in biomedical LLM training.
Knowledge Hierarchy Guided Biological-Medical Dataset Distillation for Domain LLM Training
Jan 25, 2025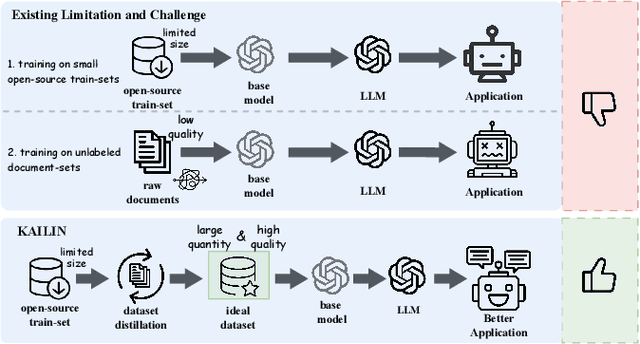

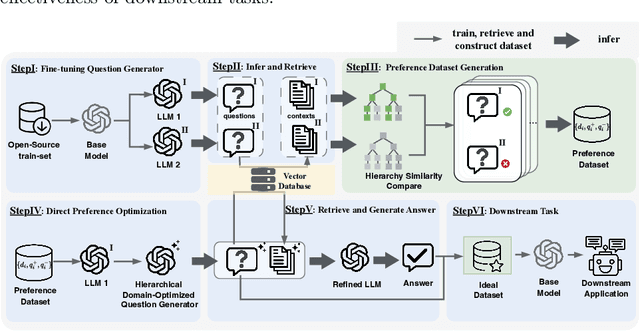

The rapid advancement of large language models (LLMs) in biological-medical applications has highlighted a gap between their potential and the limited scale and often low quality of available open-source annotated textual datasets. In addition, the inherent complexity of the biomedical knowledge hierarchy significantly hampers efforts to bridge this gap.Can LLMs themselves play a pivotal role in overcoming this limitation? Motivated by this question, we investigate this challenge in the present study.We propose a framework that automates the distillation of high-quality textual training data from the extensive scientific literature. Our approach self-evaluates and generates questions that are more closely aligned with the biomedical domain, guided by the biomedical knowledge hierarchy through medical subject headings (MeSH). This comprehensive framework establishes an automated workflow, thereby eliminating the need for manual intervention. Furthermore, we conducted comprehensive experiments to evaluate the impact of our framework-generated data on downstream language models of varying sizes. Our approach substantially improves question-answering tasks compared to pre-trained models from the life sciences domain and powerful close-source models represented by GPT-4. Notably, the generated AI-Ready dataset enabled the Llama3-70B base model to outperform GPT-4 using MedPrompt with multiple times the number of parameters. Detailed case studies and ablation experiments underscore the significance of each component within our framework
Comprehensive Metapath-based Heterogeneous Graph Transformer for Gene-Disease Association Prediction
Jan 14, 2025



Discovering gene-disease associations is crucial for understanding disease mechanisms, yet identifying these associations remains challenging due to the time and cost of biological experiments. Computational methods are increasingly vital for efficient and scalable gene-disease association prediction. Graph-based learning models, which leverage node features and network relationships, are commonly employed for biomolecular predictions. However, existing methods often struggle to effectively integrate node features, heterogeneous structures, and semantic information. To address these challenges, we propose COmprehensive MEtapath-based heterogeneous graph Transformer(COMET) for predicting gene-disease associations. COMET integrates diverse datasets to construct comprehensive heterogeneous networks, initializing node features with BioGPT. We define seven Metapaths and utilize a transformer framework to aggregate Metapath instances, capturing global contexts and long-distance dependencies. Through intra- and inter-metapath aggregation using attention mechanisms, COMET fuses latent vectors from multiple Metapaths to enhance GDA prediction accuracy. Our method demonstrates superior robustness compared to state-of-the-art approaches. Ablation studies and visualizations validate COMET's effectiveness, providing valuable insights for advancing human health research.
BioRAG: A RAG-LLM Framework for Biological Question Reasoning
Aug 02, 2024



The question-answering system for Life science research, which is characterized by the rapid pace of discovery, evolving insights, and complex interactions among knowledge entities, presents unique challenges in maintaining a comprehensive knowledge warehouse and accurate information retrieval. To address these issues, we introduce BioRAG, a novel Retrieval-Augmented Generation (RAG) with the Large Language Models (LLMs) framework. Our approach starts with parsing, indexing, and segmenting an extensive collection of 22 million scientific papers as the basic knowledge, followed by training a specialized embedding model tailored to this domain. Additionally, we enhance the vector retrieval process by incorporating a domain-specific knowledge hierarchy, which aids in modeling the intricate interrelationships among each query and context. For queries requiring the most current information, BioRAG deconstructs the question and employs an iterative retrieval process incorporated with the search engine for step-by-step reasoning. Rigorous experiments have demonstrated that our model outperforms fine-tuned LLM, LLM with search engines, and other scientific RAG frameworks across multiple life science question-answering tasks.
RHanDS: Refining Malformed Hands for Generated Images with Decoupled Structure and Style Guidance
Apr 22, 2024
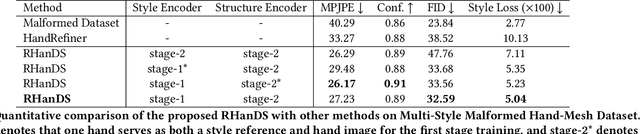


Although diffusion models can generate high-quality human images, their applications are limited by the instability in generating hands with correct structures. Some previous works mitigate the problem by considering hand structure yet struggle to maintain style consistency between refined malformed hands and other image regions. In this paper, we aim to solve the problem of inconsistency regarding hand structure and style. We propose a conditional diffusion-based framework RHanDS to refine the hand region with the help of decoupled structure and style guidance. Specifically, the structure guidance is the hand mesh reconstructed from the malformed hand, serving to correct the hand structure. The style guidance is a hand image, e.g., the malformed hand itself, and is employed to furnish the style reference for hand refining. In order to suppress the structure leakage when referencing hand style and effectively utilize hand data to improve the capability of the model, we build a multi-style hand dataset and introduce a twostage training strategy. In the first stage, we use paired hand images for training to generate hands with the same style as the reference. In the second stage, various hand images generated based on the human mesh are used for training to enable the model to gain control over the hand structure. We evaluate our method and counterparts on the test dataset of the proposed multi-style hand dataset. The experimental results show that RHanDS can effectively refine hands structure- and style- correctly compared with previous methods. The codes and datasets will be available soon.
Learn From All: Erasing Attention Consistency for Noisy Label Facial Expression Recognition
Jul 21, 2022
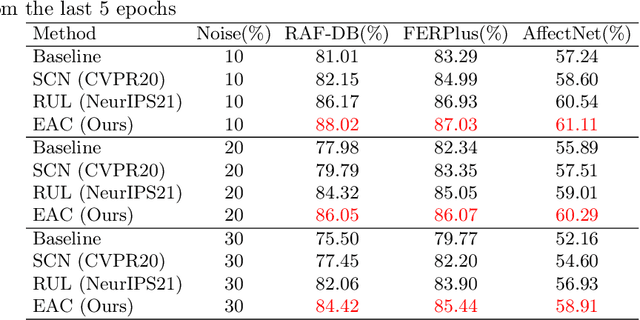
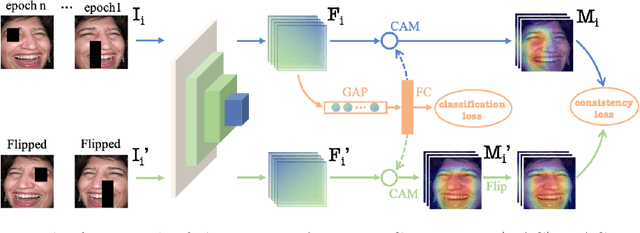
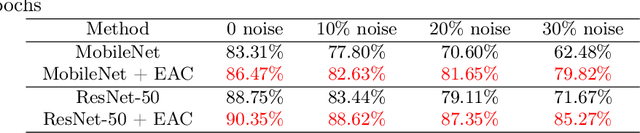
Noisy label Facial Expression Recognition (FER) is more challenging than traditional noisy label classification tasks due to the inter-class similarity and the annotation ambiguity. Recent works mainly tackle this problem by filtering out large-loss samples. In this paper, we explore dealing with noisy labels from a new feature-learning perspective. We find that FER models remember noisy samples by focusing on a part of the features that can be considered related to the noisy labels instead of learning from the whole features that lead to the latent truth. Inspired by that, we propose a novel Erasing Attention Consistency (EAC) method to suppress the noisy samples during the training process automatically. Specifically, we first utilize the flip semantic consistency of facial images to design an imbalanced framework. We then randomly erase input images and use flip attention consistency to prevent the model from focusing on a part of the features. EAC significantly outperforms state-of-the-art noisy label FER methods and generalizes well to other tasks with a large number of classes like CIFAR100 and Tiny-ImageNet. The code is available at https://github.com/zyh-uaiaaaa/Erasing-Attention-Consistency.
MLFW: A Database for Face Recognition on Masked Faces
Sep 15, 2021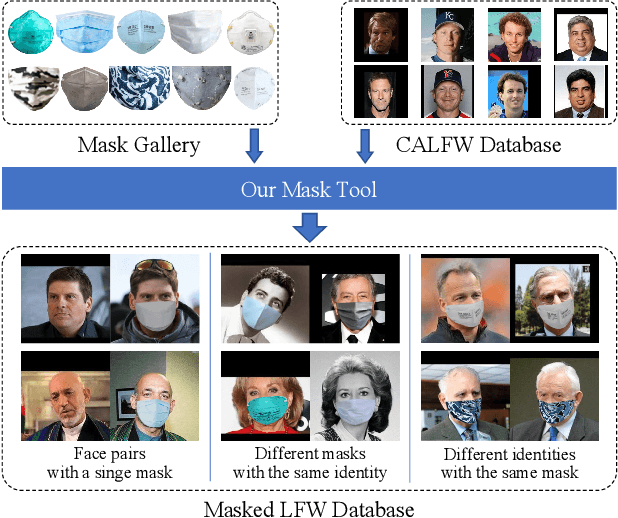


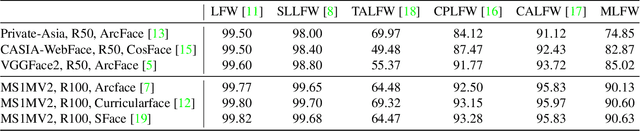
As more and more people begin to wear masks due to current COVID-19 pandemic, existing face recognition systems may encounter severe performance degradation when recognizing masked faces. To figure out the impact of masks on face recognition model, we build a simple but effective tool to generate masked faces from unmasked faces automatically, and construct a new database called Masked LFW (MLFW) based on Cross-Age LFW (CALFW) database. The mask on the masked face generated by our method has good visual consistency with the original face. Moreover, we collect various mask templates, covering most of the common styles appeared in the daily life, to achieve diverse generation effects. Considering realistic scenarios, we design three kinds of combinations of face pairs. The recognition accuracy of SOTA models declines 5%-16% on MLFW database compared with the accuracy on the original images. MLFW database can be viewed and downloaded at \url{http://whdeng.cn/mlfw}.
Representative Forgery Mining for Fake Face Detection
Apr 14, 2021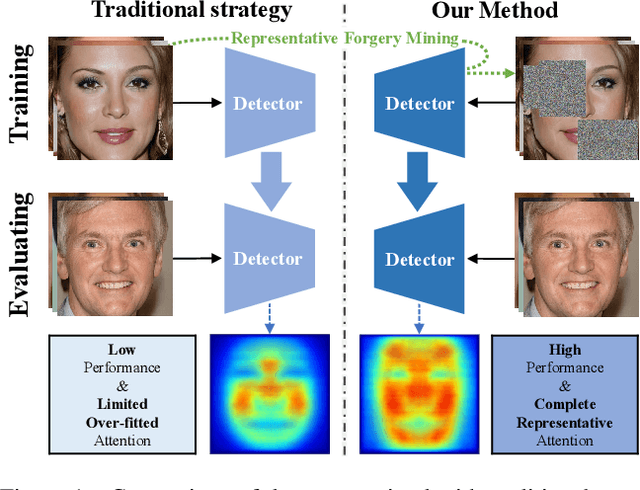
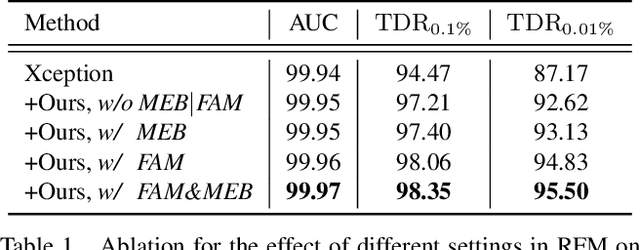

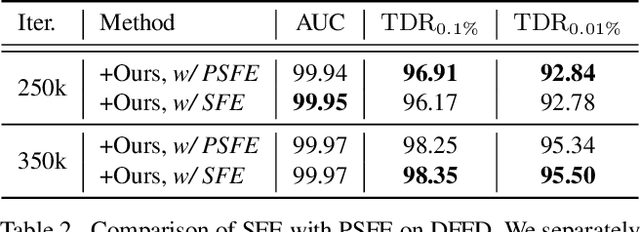
Although vanilla Convolutional Neural Network (CNN) based detectors can achieve satisfactory performance on fake face detection, we observe that the detectors tend to seek forgeries on a limited region of face, which reveals that the detectors is short of understanding of forgery. Therefore, we propose an attention-based data augmentation framework to guide detector refine and enlarge its attention. Specifically, our method tracks and occludes the Top-N sensitive facial regions, encouraging the detector to mine deeper into the regions ignored before for more representative forgery. Especially, our method is simple-to-use and can be easily integrated with various CNN models. Extensive experiments show that the detector trained with our method is capable to separately point out the representative forgery of fake faces generated by different manipulation techniques, and our method enables a vanilla CNN-based detector to achieve state-of-the-art performance without structure modification.