 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRHanDS: Refining Malformed Hands for Generated Images with Decoupled Structure and Style Guidance
Apr 22, 2024
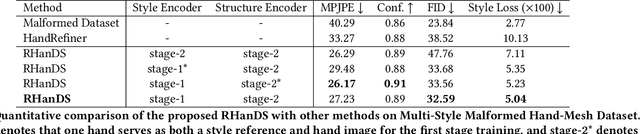


Although diffusion models can generate high-quality human images, their applications are limited by the instability in generating hands with correct structures. Some previous works mitigate the problem by considering hand structure yet struggle to maintain style consistency between refined malformed hands and other image regions. In this paper, we aim to solve the problem of inconsistency regarding hand structure and style. We propose a conditional diffusion-based framework RHanDS to refine the hand region with the help of decoupled structure and style guidance. Specifically, the structure guidance is the hand mesh reconstructed from the malformed hand, serving to correct the hand structure. The style guidance is a hand image, e.g., the malformed hand itself, and is employed to furnish the style reference for hand refining. In order to suppress the structure leakage when referencing hand style and effectively utilize hand data to improve the capability of the model, we build a multi-style hand dataset and introduce a twostage training strategy. In the first stage, we use paired hand images for training to generate hands with the same style as the reference. In the second stage, various hand images generated based on the human mesh are used for training to enable the model to gain control over the hand structure. We evaluate our method and counterparts on the test dataset of the proposed multi-style hand dataset. The experimental results show that RHanDS can effectively refine hands structure- and style- correctly compared with previous methods. The codes and datasets will be available soon.
GBA: A Tuning-free Approach to Switch between Synchronous and Asynchronous Training for Recommendation Model
May 23, 2022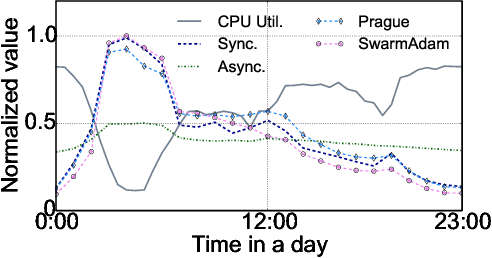
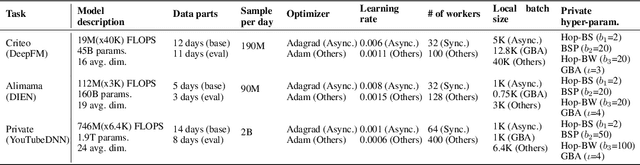
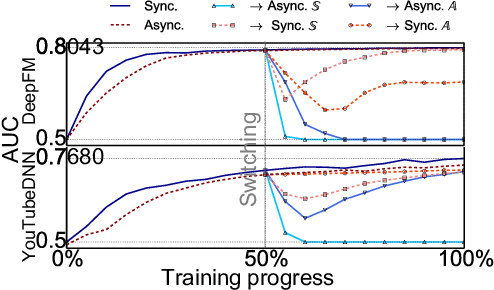

High-concurrency asynchronous training upon parameter server (PS) architecture and high-performance synchronous training upon all-reduce (AR) architecture are the most commonly deployed distributed training modes for recommender systems. Although the synchronous AR training is designed to have higher training efficiency, the asynchronous PS training would be a better choice on training speed when there are stragglers (slow workers) in the shared cluster, especially under limited computing resources. To take full advantages of these two training modes, an ideal way is to switch between them upon the cluster status. We find two obstacles to a tuning-free approach: the different distribution of the gradient values and the stale gradients from the stragglers. In this paper, we propose Global Batch gradients Aggregation (GBA) over PS, which aggregates and applies gradients with the same global batch size as the synchronous training. A token-control process is implemented to assemble the gradients and decay the gradients with severe staleness. We provide the convergence analysis to demonstrate the robustness of GBA over the recommendation models against the gradient staleness. Experiments on three industrial-scale recommendation tasks show that GBA is an effective tuning-free approach for switching. Compared to the state-of-the-art derived asynchronous training, GBA achieves up to 0.2% improvement on the AUC metric, which is significant for the recommendation models. Meanwhile, under the strained hardware resource, GBA speeds up at least 2.4x compared to the synchronous training.