 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgem-KAILIN: Knowledge-Driven Agentic Scientific Corpus Distillation Framework for Biomedical Large Language Models Training
Apr 28, 2025The rapid progress of large language models (LLMs) in biomedical research has underscored the limitations of existing open-source annotated scientific corpora, which are often insufficient in quantity and quality. Addressing the challenge posed by the complex hierarchy of biomedical knowledge, we propose a knowledge-driven, multi-agent framework for scientific corpus distillation tailored for LLM training in the biomedical domain. Central to our approach is a collaborative multi-agent architecture, where specialized agents, each guided by the Medical Subject Headings (MeSH) hierarchy, work in concert to autonomously extract, synthesize, and self-evaluate high-quality textual data from vast scientific literature. These agents collectively generate and refine domain-specific question-answer pairs, ensuring comprehensive coverage and consistency with biomedical ontologies while minimizing manual involvement. Extensive experimental results show that language models trained on our multi-agent distilled datasets achieve notable improvements in biomedical question-answering tasks, outperforming both strong life sciences LLM baselines and advanced proprietary models. Notably, our AI-Ready dataset enables Llama3-70B to surpass GPT-4 with MedPrompt and Med-PaLM-2, despite their larger scale. Detailed ablation studies and case analyses further validate the effectiveness and synergy of each agent within the framework, highlighting the potential of multi-agent collaboration in biomedical LLM training.
Knowledge Hierarchy Guided Biological-Medical Dataset Distillation for Domain LLM Training
Jan 25, 2025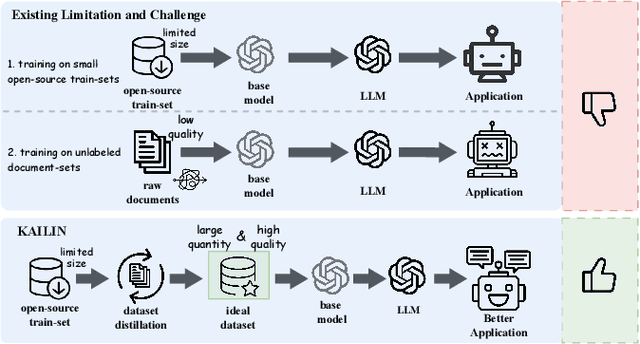

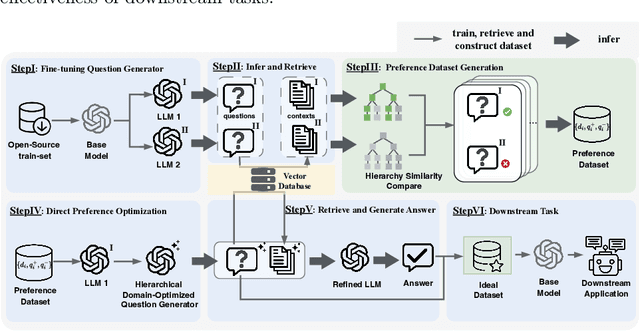

The rapid advancement of large language models (LLMs) in biological-medical applications has highlighted a gap between their potential and the limited scale and often low quality of available open-source annotated textual datasets. In addition, the inherent complexity of the biomedical knowledge hierarchy significantly hampers efforts to bridge this gap.Can LLMs themselves play a pivotal role in overcoming this limitation? Motivated by this question, we investigate this challenge in the present study.We propose a framework that automates the distillation of high-quality textual training data from the extensive scientific literature. Our approach self-evaluates and generates questions that are more closely aligned with the biomedical domain, guided by the biomedical knowledge hierarchy through medical subject headings (MeSH). This comprehensive framework establishes an automated workflow, thereby eliminating the need for manual intervention. Furthermore, we conducted comprehensive experiments to evaluate the impact of our framework-generated data on downstream language models of varying sizes. Our approach substantially improves question-answering tasks compared to pre-trained models from the life sciences domain and powerful close-source models represented by GPT-4. Notably, the generated AI-Ready dataset enabled the Llama3-70B base model to outperform GPT-4 using MedPrompt with multiple times the number of parameters. Detailed case studies and ablation experiments underscore the significance of each component within our framework
BioRAG: A RAG-LLM Framework for Biological Question Reasoning
Aug 02, 2024



The question-answering system for Life science research, which is characterized by the rapid pace of discovery, evolving insights, and complex interactions among knowledge entities, presents unique challenges in maintaining a comprehensive knowledge warehouse and accurate information retrieval. To address these issues, we introduce BioRAG, a novel Retrieval-Augmented Generation (RAG) with the Large Language Models (LLMs) framework. Our approach starts with parsing, indexing, and segmenting an extensive collection of 22 million scientific papers as the basic knowledge, followed by training a specialized embedding model tailored to this domain. Additionally, we enhance the vector retrieval process by incorporating a domain-specific knowledge hierarchy, which aids in modeling the intricate interrelationships among each query and context. For queries requiring the most current information, BioRAG deconstructs the question and employs an iterative retrieval process incorporated with the search engine for step-by-step reasoning. Rigorous experiments have demonstrated that our model outperforms fine-tuned LLM, LLM with search engines, and other scientific RAG frameworks across multiple life science question-answering tasks.
Resolving the Imbalance Issue in Hierarchical Disciplinary Topic Inference via LLM-based Data Augmentation
Oct 15, 2023In addressing the imbalanced issue of data within the realm of Natural Language Processing, text data augmentation methods have emerged as pivotal solutions. This data imbalance is prevalent in the research proposals submitted during the funding application process. Such imbalances, resulting from the varying popularity of disciplines or the emergence of interdisciplinary studies, significantly impede the precision of downstream topic models that deduce the affiliated disciplines of these proposals. At the data level, proposals penned by experts and scientists are inherently complex technological texts, replete with intricate terminologies, which augmenting such specialized text data poses unique challenges. At the system level, this, in turn, compromises the fairness of AI-assisted reviewer assignment systems, which raises a spotlight on solving this issue. This study leverages large language models (Llama V1) as data generators to augment research proposals categorized within intricate disciplinary hierarchies, aiming to rectify data imbalances and enhance the equity of expert assignments. We first sample within the hierarchical structure to find the under-represented class. Then we designed a prompt for keyword-based research proposal generation. Our experiments attests to the efficacy of the generated data, demonstrating that research proposals produced using the prompts can effectively address the aforementioned issues and generate high quality scientific text data, thus help the model overcome the imbalanced issue.