 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLMLight: Traffic Signal Control via Vision-Language Meta-Control and Dual-Branch Reasoning
May 26, 2025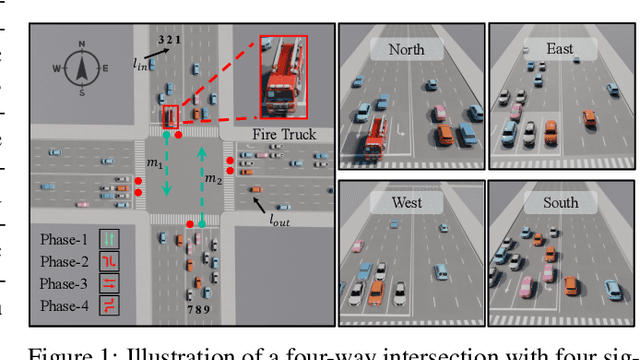
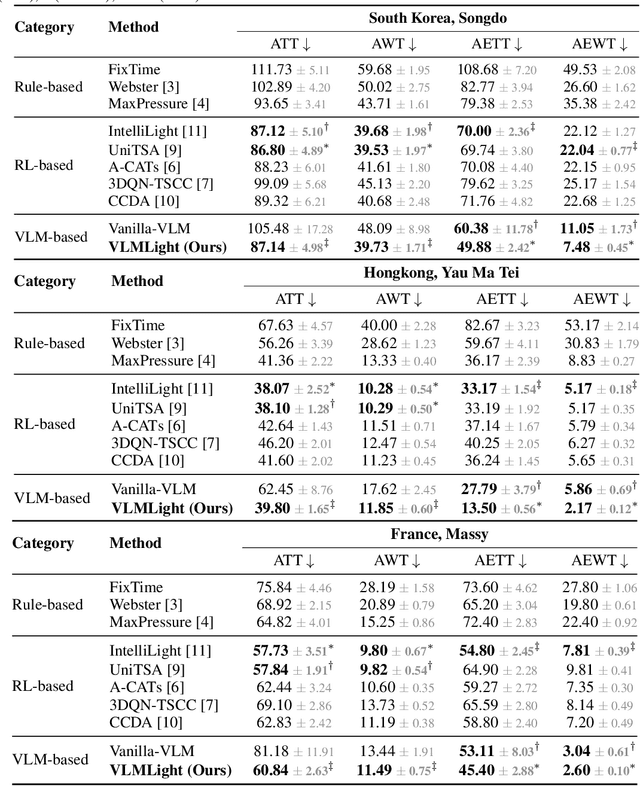
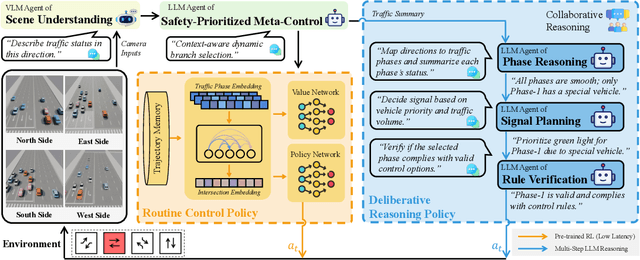

Traffic signal control (TSC) is a core challenge in urban mobility, where real-time decisions must balance efficiency and safety. Existing methods - ranging from rule-based heuristics to reinforcement learning (RL) - often struggle to generalize to complex, dynamic, and safety-critical scenarios. We introduce VLMLight, a novel TSC framework that integrates vision-language meta-control with dual-branch reasoning. At the core of VLMLight is the first image-based traffic simulator that enables multi-view visual perception at intersections, allowing policies to reason over rich cues such as vehicle type, motion, and spatial density. A large language model (LLM) serves as a safety-prioritized meta-controller, selecting between a fast RL policy for routine traffic and a structured reasoning branch for critical cases. In the latter, multiple LLM agents collaborate to assess traffic phases, prioritize emergency vehicles, and verify rule compliance. Experiments show that VLMLight reduces waiting times for emergency vehicles by up to 65% over RL-only systems, while preserving real-time performance in standard conditions with less than 1% degradation. VLMLight offers a scalable, interpretable, and safety-aware solution for next-generation traffic signal control.
SMART: Scalable Multi-agent Real-time Simulation via Next-token Prediction
May 24, 2024
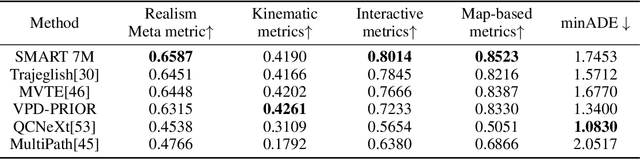

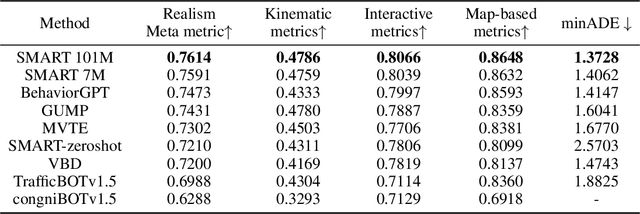
Data-driven autonomous driving motion generation tasks are frequently impacted by the limitations of dataset size and the domain gap between datasets, which precludes their extensive application in real-world scenarios. To address this issue, we introduce SMART, a novel autonomous driving motion generation paradigm that models vectorized map and agent trajectory data into discrete sequence tokens. These tokens are then processed through a decoder-only transformer architecture to train for the next token prediction task across spatial-temporal series. This GPT-style method allows the model to learn the motion distribution in real driving scenarios. SMART achieves state-of-the-art performance across most of the metrics on the generative Sim Agents challenge, ranking 1st on the leaderboards of Waymo Open Motion Dataset (WOMD), demonstrating remarkable inference speed. Moreover, SMART represents the generative model in the autonomous driving motion domain, exhibiting zero-shot generalization capabilities: Using only the NuPlan dataset for training and WOMD for validation, SMART achieved a competitive score of 0.71 on the Sim Agents challenge. Lastly, we have collected over 1 billion motion tokens from multiple datasets, validating the model's scalability. These results suggest that SMART has initially emulated two important properties: scalability and zero-shot generalization, and preliminarily meets the needs of large-scale real-time simulation applications. We have released all the code to promote the exploration of models for motion generation in the autonomous driving field.
LLM-Assisted Light: Leveraging Large Language Model Capabilities for Human-Mimetic Traffic Signal Control in Complex Urban Environments
Mar 13, 2024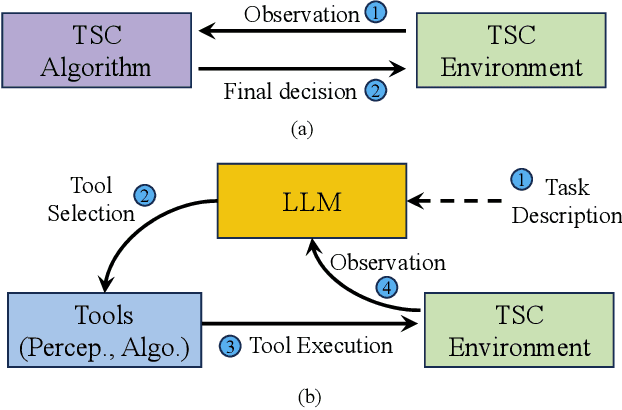
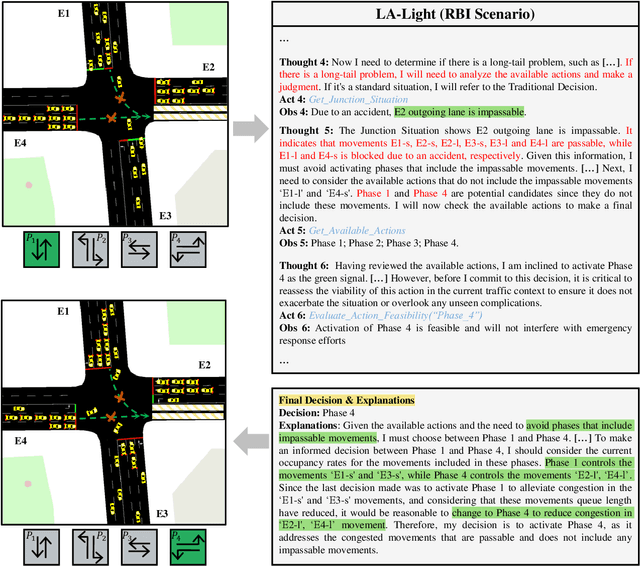

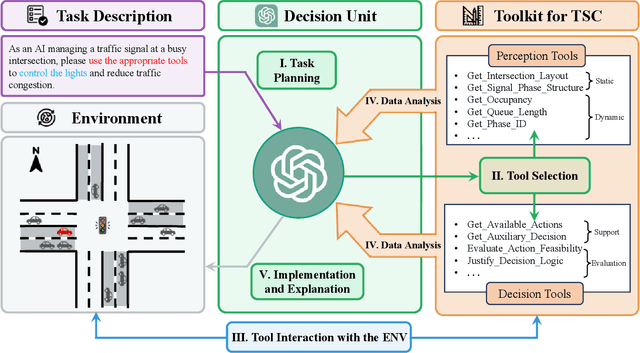
Traffic congestion in metropolitan areas presents a formidable challenge with far-reaching economic, environmental, and societal ramifications. Therefore, effective congestion management is imperative, with traffic signal control (TSC) systems being pivotal in this endeavor. Conventional TSC systems, designed upon rule-based algorithms or reinforcement learning (RL), frequently exhibit deficiencies in managing the complexities and variabilities of urban traffic flows, constrained by their limited capacity for adaptation to unfamiliar scenarios. In response to these limitations, this work introduces an innovative approach that integrates Large Language Models (LLMs) into TSC, harnessing their advanced reasoning and decision-making faculties. Specifically, a hybrid framework that augments LLMs with a suite of perception and decision-making tools is proposed, facilitating the interrogation of both the static and dynamic traffic information. This design places the LLM at the center of the decision-making process, combining external traffic data with established TSC methods. Moreover, a simulation platform is developed to corroborate the efficacy of the proposed framework. The findings from our simulations attest to the system's adeptness in adjusting to a multiplicity of traffic environments without the need for additional training. Notably, in cases of Sensor Outage (SO), our approach surpasses conventional RL-based systems by reducing the average waiting time by $20.4\%$. This research signifies a notable advance in TSC strategies and paves the way for the integration of LLMs into real-world, dynamic scenarios, highlighting their potential to revolutionize traffic management. The related code is available at \href{https://github.com/Traffic-Alpha/LLM-Assisted-Light}{https://github.com/Traffic-Alpha/LLM-Assisted-Light}.
HoloVIC: Large-scale Dataset and Benchmark for Multi-Sensor Holographic Intersection and Vehicle-Infrastructure Cooperative
Mar 06, 2024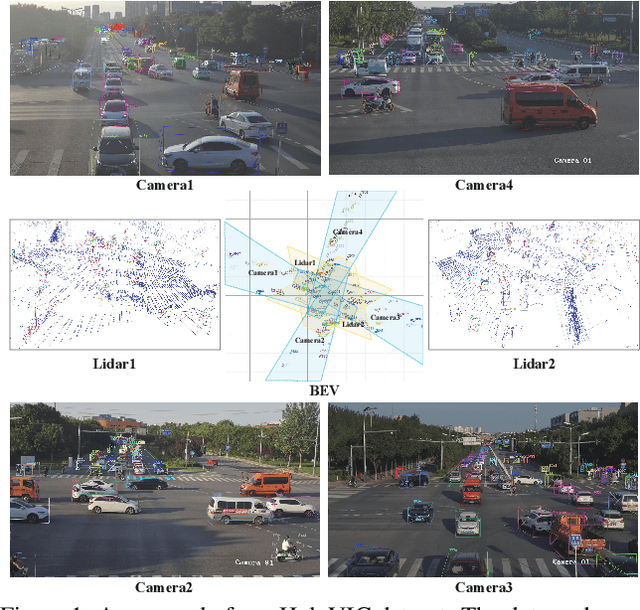
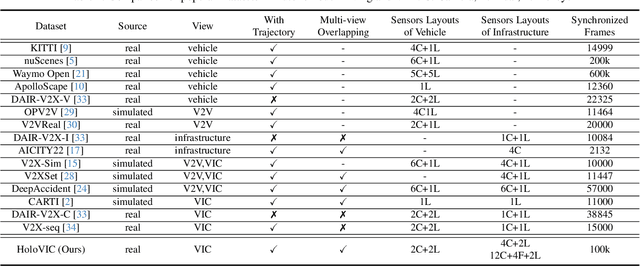
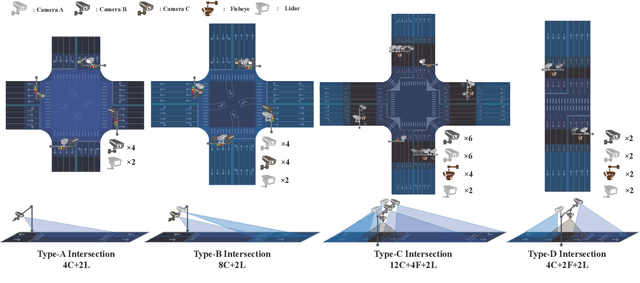
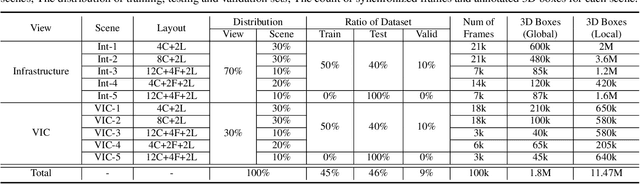
Vehicle-to-everything (V2X) is a popular topic in the field of Autonomous Driving in recent years. Vehicle-infrastructure cooperation (VIC) becomes one of the important research area. Due to the complexity of traffic conditions such as blind spots and occlusion, it greatly limits the perception capabilities of single-view roadside sensing systems. To further enhance the accuracy of roadside perception and provide better information to the vehicle side, in this paper, we constructed holographic intersections with various layouts to build a large-scale multi-sensor holographic vehicle-infrastructure cooperation dataset, called HoloVIC. Our dataset includes 3 different types of sensors (Camera, Lidar, Fisheye) and employs 4 sensor-layouts based on the different intersections. Each intersection is equipped with 6-18 sensors to capture synchronous data. While autonomous vehicles pass through these intersections for collecting VIC data. HoloVIC contains in total on 100k+ synchronous frames from different sensors. Additionally, we annotated 3D bounding boxes based on Camera, Fisheye, and Lidar. We also associate the IDs of the same objects across different devices and consecutive frames in sequence. Based on HoloVIC, we formulated four tasks to facilitate the development of related research. We also provide benchmarks for these tasks.
UniTSA: A Universal Reinforcement Learning Framework for V2X Traffic Signal Control
Dec 08, 2023



Traffic congestion is a persistent problem in urban areas, which calls for the development of effective traffic signal control (TSC) systems. While existing Reinforcement Learning (RL)-based methods have shown promising performance in optimizing TSC, it is challenging to generalize these methods across intersections of different structures. In this work, a universal RL-based TSC framework is proposed for Vehicle-to-Everything (V2X) environments. The proposed framework introduces a novel agent design that incorporates a junction matrix to characterize intersection states, making the proposed model applicable to diverse intersections. To equip the proposed RL-based framework with enhanced capability of handling various intersection structures, novel traffic state augmentation methods are tailor-made for signal light control systems. Finally, extensive experimental results derived from multiple intersection configurations confirm the effectiveness of the proposed framework. The source code in this work is available at https://github.com/wmn7/Universal_Light
ADLight: A Universal Approach of Traffic Signal Control with Augmented Data Using Reinforcement Learning
Oct 24, 2022



Traffic signal control has the potential to reduce congestion in dynamic networks. Recent studies show that traffic signal control with reinforcement learning (RL) methods can significantly reduce the average waiting time. However, a shortcoming of existing methods is that they require model retraining for new intersections with different structures. In this paper, we propose a novel reinforcement learning approach with augmented data (ADLight) to train a universal model for intersections with different structures. We propose a new agent design incorporating features on movements and actions with set current phase duration to allow the generalized model to have the same structure for different intersections. A new data augmentation method named \textit{movement shuffle} is developed to improve the generalization performance. We also test the universal model with new intersections in Simulation of Urban MObility (SUMO). The results show that the performance of our approach is close to the models trained in a single environment directly (only a 5% loss of average waiting time), and we can reduce more than 80% of training time, which saves a lot of computational resources in scalable operations of traffic lights.