 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large Language Model-Enhanced Q-learning for Capacitated Vehicle Routing Problem with Time Windows
May 09, 2025



The Capacitated Vehicle Routing Problem with Time Windows (CVRPTW) is a classic NP-hard combinatorial optimization problem widely applied in logistics distribution and transportation management. Its complexity stems from the constraints of vehicle capacity and time windows, which pose significant challenges to traditional approaches. Advances in Large Language Models (LLMs) provide new possibilities for finding approximate solutions to CVRPTW. This paper proposes a novel LLM-enhanced Q-learning framework to address the CVRPTW with real-time emergency constraints. Our solution introduces an adaptive two-phase training mechanism that transitions from the LLM-guided exploration phase to the autonomous optimization phase of Q-network. To ensure reliability, we design a three-tier self-correction mechanism based on the Chain-of-Thought (CoT) for LLMs: syntactic validation, semantic verification, and physical constraint enforcement. In addition, we also prioritized replay of the experience generated by LLMs to amplify the regulatory role of LLMs in the architecture. Experimental results demonstrate that our framework achieves a 7.3\% average reduction in cost compared to traditional Q-learning, with fewer training steps required for convergence.
PaliGemma: A versatile 3B VLM for transfer
Jul 10, 2024



PaliGemma is an open Vision-Language Model (VLM) that is based on the SigLIP-So400m vision encoder and the Gemma-2B language model. It is trained to be a versatile and broadly knowledgeable base model that is effective to transfer. It achieves strong performance on a wide variety of open-world tasks. We evaluate PaliGemma on almost 40 diverse tasks including standard VLM benchmarks, but also more specialized tasks such as remote-sensing and segmentation.
iLLM-TSC: Integration reinforcement learning and large language model for traffic signal control policy improvement
Jul 08, 2024
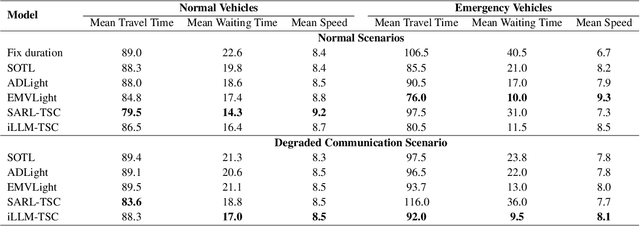
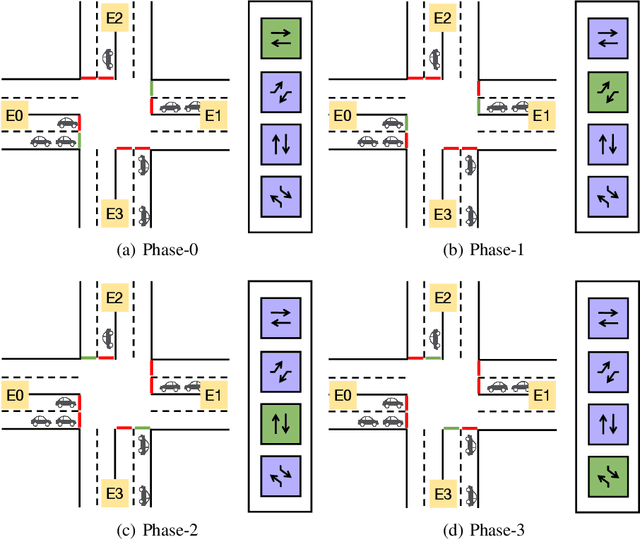

Urban congestion remains a critical challenge, with traffic signal control (TSC) emerging as a potent solution. TSC is often modeled as a Markov Decision Process problem and then solved using reinforcement learning (RL), which has proven effective. However, the existing RL-based TSC system often overlooks imperfect observations caused by degraded communication, such as packet loss, delays, and noise, as well as rare real-life events not included in the reward function, such as unconsidered emergency vehicles. To address these limitations, we introduce a novel integration framework that combines a large language model (LLM) with RL. This framework is designed to manage overlooked elements in the reward function and gaps in state information, thereby enhancing the policies of RL agents. In our approach, RL initially makes decisions based on observed data. Subsequently, LLMs evaluate these decisions to verify their reasonableness. If a decision is found to be unreasonable, it is adjusted accordingly. Additionally, this integration approach can be seamlessly integrated with existing RL-based TSC systems without necessitating modifications. Extensive testing confirms that our approach reduces the average waiting time by $17.5\%$ in degraded communication conditions as compared to traditional RL methods, underscoring its potential to advance practical RL applications in intelligent transportation systems. The related code can be found at \url{https://github.com/Traffic-Alpha/iLLM-TSC}.
Dyna-Style Learning with A Macroscopic Model for Vehicle Platooning in Mixed-Autonomy Traffic
May 03, 2024



Platooning of connected and autonomous vehicles (CAVs) plays a vital role in modernizing highways, ushering in enhanced efficiency and safety. This paper explores the significance of platooning in smart highways, employing a coupled partial differential equation (PDE) and ordinary differential equation (ODE) model to elucidate the complex interaction between bulk traffic flow and CAV platoons. Our study focuses on developing a Dyna-style planning and learning framework tailored for platoon control, with a specific goal of reducing fuel consumption. By harnessing the coupled PDE-ODE model, we improve data efficiency in Dyna-style learning through virtual experiences. Simulation results validate the effectiveness of our macroscopic model in modeling platoons within mixed-autonomy settings, demonstrating a notable $10.11\%$ reduction in vehicular fuel consumption compared to conventional approaches.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
UniTSA: A Universal Reinforcement Learning Framework for V2X Traffic Signal Control
Dec 08, 2023



Traffic congestion is a persistent problem in urban areas, which calls for the development of effective traffic signal control (TSC) systems. While existing Reinforcement Learning (RL)-based methods have shown promising performance in optimizing TSC, it is challenging to generalize these methods across intersections of different structures. In this work, a universal RL-based TSC framework is proposed for Vehicle-to-Everything (V2X) environments. The proposed framework introduces a novel agent design that incorporates a junction matrix to characterize intersection states, making the proposed model applicable to diverse intersections. To equip the proposed RL-based framework with enhanced capability of handling various intersection structures, novel traffic state augmentation methods are tailor-made for signal light control systems. Finally, extensive experimental results derived from multiple intersection configurations confirm the effectiveness of the proposed framework. The source code in this work is available at https://github.com/wmn7/Universal_Light
Combining Policy Gradient and Safety-Based Control for Autonomous Driving
Oct 20, 2023



With the advancement of data-driven techniques, addressing continuous con-trol challenges has become more efficient. However, the reliance of these methods on historical data introduces the potential for unexpected decisions in novel scenarios. To enhance performance in autonomous driving and collision avoidance, we propose a symbiotic fusion of policy gradient with safety-based control. In this study, we em-ploy the Deep Deterministic Policy Gradient (DDPG) algorithm to enable autono-mous driving in the absence of surrounding vehicles. By training the vehicle's driving policy within a stable and familiar environment, a robust and efficient learning pro-cess is achieved. Subsequently, an artificial potential field approach is utilized to formulate a collision avoidance algorithm, accounting for the presence of surround-ing vehicles. Furthermore, meticulous consideration is given to path tracking meth-ods. The amalgamation of these approaches demonstrates substantial performance across diverse scenarios, underscoring its potential for advancing autonomous driving while upholding safety standards.
PaLI-3 Vision Language Models: Smaller, Faster, Stronger
Oct 17, 2023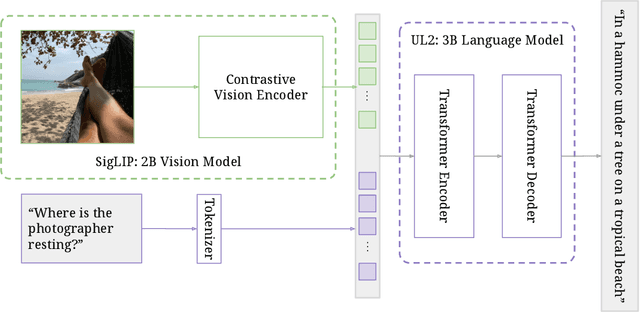
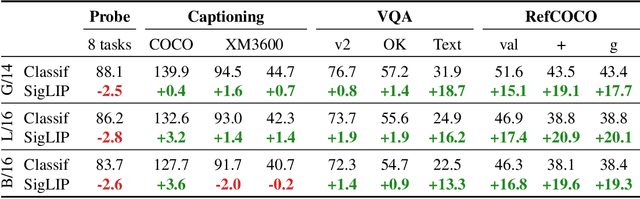
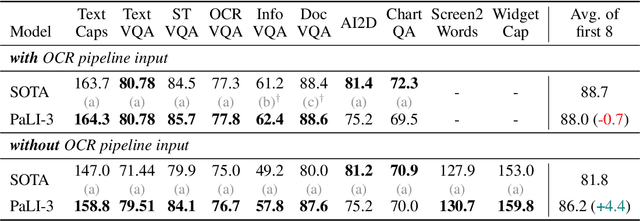
This paper presents PaLI-3, a smaller, faster, and stronger vision language model (VLM) that compares favorably to similar models that are 10x larger. As part of arriving at this strong performance, we compare Vision Transformer (ViT) models pretrained using classification objectives to contrastively (SigLIP) pretrained ones. We find that, while slightly underperforming on standard image classification benchmarks, SigLIP-based PaLI shows superior performance across various multimodal benchmarks, especially on localization and visually-situated text understanding. We scale the SigLIP image encoder up to 2 billion parameters, and achieves a new state-of-the-art on multilingual cross-modal retrieval. We hope that PaLI-3, at only 5B parameters, rekindles research on fundamental pieces of complex VLMs, and could fuel a new generation of scaled-up models.
ADLight: A Universal Approach of Traffic Signal Control with Augmented Data Using Reinforcement Learning
Oct 24, 2022



Traffic signal control has the potential to reduce congestion in dynamic networks. Recent studies show that traffic signal control with reinforcement learning (RL) methods can significantly reduce the average waiting time. However, a shortcoming of existing methods is that they require model retraining for new intersections with different structures. In this paper, we propose a novel reinforcement learning approach with augmented data (ADLight) to train a universal model for intersections with different structures. We propose a new agent design incorporating features on movements and actions with set current phase duration to allow the generalized model to have the same structure for different intersections. A new data augmentation method named \textit{movement shuffle} is developed to improve the generalization performance. We also test the universal model with new intersections in Simulation of Urban MObility (SUMO). The results show that the performance of our approach is close to the models trained in a single environment directly (only a 5% loss of average waiting time), and we can reduce more than 80% of training time, which saves a lot of computational resources in scalable operations of traffic lights.