 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-to-Robot Interaction: Learning from Video Demonstration for Robot Imitation
Feb 22, 2026Learning from Demonstration (LfD) offers a promising paradigm for robot skill acquisition. Recent approaches attempt to extract manipulation commands directly from video demonstrations, yet face two critical challenges: (1) general video captioning models prioritize global scene features over task-relevant objects, producing descriptions unsuitable for precise robotic execution, and (2) end-to-end architectures coupling visual understanding with policy learning require extensive paired datasets and struggle to generalize across objects and scenarios. To address these limitations, we propose a novel ``Human-to-Robot'' imitation learning pipeline that enables robots to acquire manipulation skills directly from unstructured video demonstrations, inspired by the human ability to learn by watching and imitating. Our key innovation is a modular framework that decouples the learning process into two distinct stages: (1) Video Understanding, which combines Temporal Shift Modules (TSM) with Vision-Language Models (VLMs) to extract actions and identify interacted objects, and (2) Robot Imitation, which employs TD3-based deep reinforcement learning to execute the demonstrated manipulations. We validated our approach in PyBullet simulation environments with a UR5e manipulator and in a real-world experiment with a UF850 manipulator across four fundamental actions: reach, pick, move, and put. For video understanding, our method achieves 89.97% action classification accuracy and BLEU-4 scores of 0.351 on standard objects and 0.265 on novel objects, representing improvements of 76.4% and 128.4% over the best baseline, respectively. For robot manipulation, our framework achieves an average success rate of 87.5% across all actions, with 100% success on reaching tasks and up to 90% on complex pick-and-place operations. The project website is available at https://thanhnguyencanh.github.io/LfD4hri.
Visual Prompt Guided Unified Pushing Policy
Feb 22, 2026As one of the simplest non-prehensile manipulation skills, pushing has been widely studied as an effective means to rearrange objects. Existing approaches, however, typically rely on multi-step push plans composed of pre-defined pushing primitives with limited application scopes, which restrict their efficiency and versatility across different scenarios. In this work, we propose a unified pushing policy that incorporates a lightweight prompting mechanism into a flow matching policy to guide the generation of reactive, multimodal pushing actions. The visual prompt can be specified by a high-level planner, enabling the reuse of the pushing policy across a wide range of planning problems. Experimental results demonstrate that the proposed unified pushing policy not only outperforms existing baselines but also effectively serves as a low-level primitive within a VLM-guided planning framework to solve table-cleaning tasks efficiently.
HMAFlow: Learning More Accurate Optical Flow via Hierarchical Motion Field Alignment
Sep 09, 2024



Optical flow estimation is a fundamental and long-standing visual task. In this work, we present a novel method, dubbed HMAFlow, to improve optical flow estimation in these tough scenes, especially with small objects. The proposed model mainly consists of two core components: a Hierarchical Motion Field Alignment (HMA) module and a Correlation Self-Attention (CSA) module. In addition, we rebuild 4D cost volumes by employing a Multi-Scale Correlation Search (MCS) layer and replacing average pooling in common cost volumes with an search strategy using multiple search ranges. Experimental results demonstrate that our model achieves the best generalization performance in comparison to other state-of-the-art methods. Specifically, compared with RAFT, our method achieves relative error reductions of 14.2% and 3.4% on the clean pass and final pass of the Sintel online benchmark, respectively. On the KITTI test benchmark, HMAFlow surpasses RAFT and GMA in the Fl-all metric by a relative margin of 6.8% and 7.7%, respectively. To facilitate future research, our code will be made available at https://github.com/BooTurbo/HMAFlow.
SMART: Scalable Multi-agent Real-time Simulation via Next-token Prediction
May 24, 2024
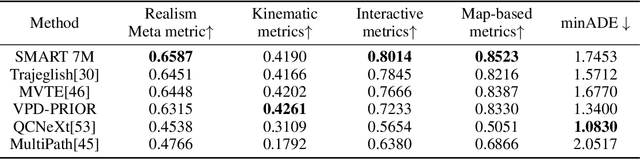

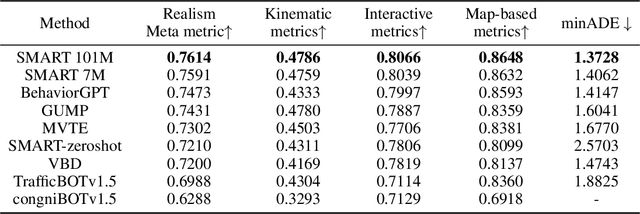
Data-driven autonomous driving motion generation tasks are frequently impacted by the limitations of dataset size and the domain gap between datasets, which precludes their extensive application in real-world scenarios. To address this issue, we introduce SMART, a novel autonomous driving motion generation paradigm that models vectorized map and agent trajectory data into discrete sequence tokens. These tokens are then processed through a decoder-only transformer architecture to train for the next token prediction task across spatial-temporal series. This GPT-style method allows the model to learn the motion distribution in real driving scenarios. SMART achieves state-of-the-art performance across most of the metrics on the generative Sim Agents challenge, ranking 1st on the leaderboards of Waymo Open Motion Dataset (WOMD), demonstrating remarkable inference speed. Moreover, SMART represents the generative model in the autonomous driving motion domain, exhibiting zero-shot generalization capabilities: Using only the NuPlan dataset for training and WOMD for validation, SMART achieved a competitive score of 0.71 on the Sim Agents challenge. Lastly, we have collected over 1 billion motion tokens from multiple datasets, validating the model's scalability. These results suggest that SMART has initially emulated two important properties: scalability and zero-shot generalization, and preliminarily meets the needs of large-scale real-time simulation applications. We have released all the code to promote the exploration of models for motion generation in the autonomous driving field.
BERP: A Blind Estimator of Room Acoustic and Physical Parameters for Single-Channel Noisy Speech Signals
May 07, 2024



Room acoustic parameters (RAPs) and room physical parameters ( RPPs) are essential metrics for parameterizing the room acoustical characteristics (RAC) of a sound field around a listener's local environment, offering comprehensive indications for various applications. The current RAPs and RPPs estimation methods either fall short of covering broad real-world acoustic environments in the context of real background noise or lack universal frameworks for blindly estimating RAPs and RPPs from noisy single-channel speech signals, particularly sound source distances, direction-of-arrival (DOA) of sound sources, and occupancy levels. On the other hand, in this paper, we propose a novel universal blind estimation framework called the blind estimator of room acoustical and physical parameters (BERP), by introducing a new stochastic room impulse response (RIR) model, namely, the sparse stochastic impulse response (SSIR) model, and endowing the BERP with a unified encoder and multiple separate predictors to estimate RPPs and SSIR parameters in parallel. This estimation framework enables the computationally efficient and universal estimation of room parameters by solely using noisy single-channel speech signals. Finally, all the RAPs can be simultaneously derived from the RIRs synthesized from SSIR model with the estimated parameters. To evaluate the effectiveness of the proposed BERP and SSIR models, we compile a task-specific dataset from several publicly available datasets. The results reveal that the BERP achieves state-of-the-art (SOTA) performance. Moreover, the evaluation results pertaining to the SSIR RIR model also demonstrated its efficacy. The code is available on GitHub.
Staged Depthwise Correlation and Feature Fusion for Siamese Object Tracking
Oct 15, 2023



In this work, we propose a novel staged depthwise correlation and feature fusion network, named DCFFNet, to further optimize the feature extraction for visual tracking. We build our deep tracker upon a siamese network architecture, which is offline trained from scratch on multiple large-scale datasets in an end-to-end manner. The model contains a core component, that is, depthwise correlation and feature fusion module (correlation-fusion module), which facilitates model to learn a set of optimal weights for a specific object by utilizing ensembles of multi-level features from lower and higher layers and multi-channel semantics on the same layer. We combine the modified ResNet-50 with the proposed correlation-fusion layer to constitute the feature extractor of our model. In training process, we find the training of model become more stable, that benifits from the correlation-fusion module. For comprehensive evaluations of performance, we implement our tracker on the popular benchmarks, including OTB100, VOT2018 and LaSOT. Extensive experiment results demonstrate that our proposed method achieves favorably competitive performance against many leading trackers in terms of accuracy and precision, while satisfying the real-time requirements of applications.