 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHMAFlow: Learning More Accurate Optical Flow via Hierarchical Motion Field Alignment
Sep 09, 2024



Optical flow estimation is a fundamental and long-standing visual task. In this work, we present a novel method, dubbed HMAFlow, to improve optical flow estimation in these tough scenes, especially with small objects. The proposed model mainly consists of two core components: a Hierarchical Motion Field Alignment (HMA) module and a Correlation Self-Attention (CSA) module. In addition, we rebuild 4D cost volumes by employing a Multi-Scale Correlation Search (MCS) layer and replacing average pooling in common cost volumes with an search strategy using multiple search ranges. Experimental results demonstrate that our model achieves the best generalization performance in comparison to other state-of-the-art methods. Specifically, compared with RAFT, our method achieves relative error reductions of 14.2% and 3.4% on the clean pass and final pass of the Sintel online benchmark, respectively. On the KITTI test benchmark, HMAFlow surpasses RAFT and GMA in the Fl-all metric by a relative margin of 6.8% and 7.7%, respectively. To facilitate future research, our code will be made available at https://github.com/BooTurbo/HMAFlow.
Extrinsicaly Rewarded Soft Q Imitation Learning with Discriminator
Jan 30, 2024Imitation learning is often used in addition to reinforcement learning in environments where reward design is difficult or where the reward is sparse, but it is difficult to be able to imitate well in unknown states from a small amount of expert data and sampling data. Supervised learning methods such as Behavioral Cloning do not require sampling data, but usually suffer from distribution shift. The methods based on reinforcement learning, such as inverse reinforcement learning and Generative Adversarial imitation learning (GAIL), can learn from only a few expert data. However, they often need to interact with the environment. Soft Q imitation learning (SQIL) addressed the problems, and it was shown that it could learn efficiently by combining Behavioral Cloning and soft Q-learning with constant rewards. In order to make this algorithm more robust to distribution shift, we propose more efficient and robust algorithm by adding to this method a reward function based on adversarial inverse reinforcement learning that rewards the agent for performing actions in status similar to the demo. We call this algorithm Discriminator Soft Q Imitation Learning (DSQIL). We evaluated it on MuJoCo environments.
Staged Depthwise Correlation and Feature Fusion for Siamese Object Tracking
Oct 15, 2023



In this work, we propose a novel staged depthwise correlation and feature fusion network, named DCFFNet, to further optimize the feature extraction for visual tracking. We build our deep tracker upon a siamese network architecture, which is offline trained from scratch on multiple large-scale datasets in an end-to-end manner. The model contains a core component, that is, depthwise correlation and feature fusion module (correlation-fusion module), which facilitates model to learn a set of optimal weights for a specific object by utilizing ensembles of multi-level features from lower and higher layers and multi-channel semantics on the same layer. We combine the modified ResNet-50 with the proposed correlation-fusion layer to constitute the feature extractor of our model. In training process, we find the training of model become more stable, that benifits from the correlation-fusion module. For comprehensive evaluations of performance, we implement our tracker on the popular benchmarks, including OTB100, VOT2018 and LaSOT. Extensive experiment results demonstrate that our proposed method achieves favorably competitive performance against many leading trackers in terms of accuracy and precision, while satisfying the real-time requirements of applications.
Discriminator Soft Actor Critic without Extrinsic Rewards
Jan 31, 2020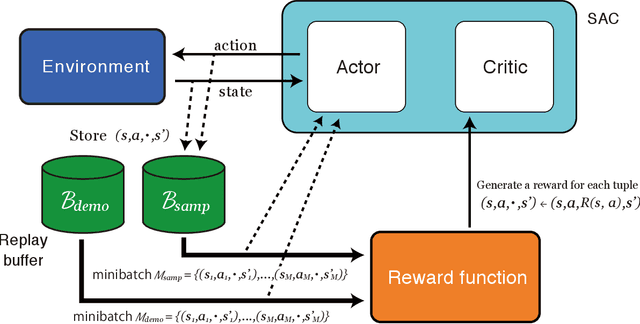

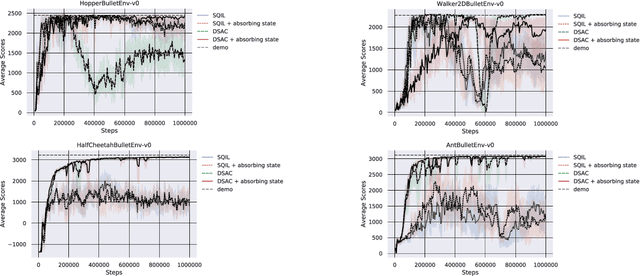
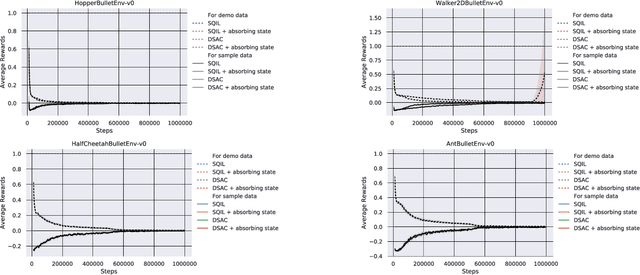
It is difficult to be able to imitate well in unknown states from a small amount of expert data and sampling data. Supervised learning methods such as Behavioral Cloning do not require sampling data, but usually suffer from distribution shift. The methods based on reinforcement learning, such as inverse reinforcement learning and generative adversarial imitation learning (GAIL), can learn from only a few expert data. However, they often need to interact with the environment. Soft Q imitation learning addressed the problems, and it was shown that it could learn efficiently by combining Behavioral Cloning and soft Q-learning with constant rewards. In order to make this algorithm more robust to distribution shift, we propose Discriminator Soft Actor Critic (DSAC). It uses a reward function based on adversarial inverse reinforcement learning instead of constant rewards. We evaluated it on PyBullet environments with only four expert trajectories.
Improving Minimal Gated Unit for Sequential Data
May 21, 2019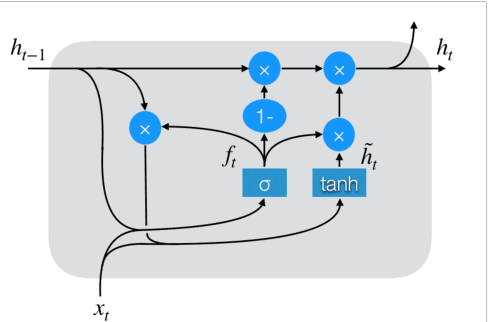

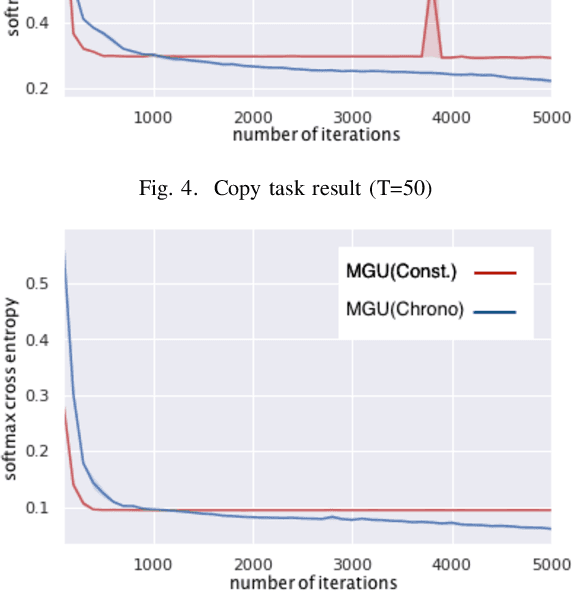
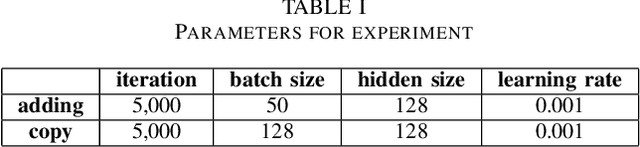
In order to obtain a model which can process sequential data related to machine translation and speech recognition faster and more accurately, we propose adopting Chrono Initializer as the initialization method of Minimal Gated Unit. We evaluated the method with two tasks: adding task and copy task. As a result of the experiment, the effectiveness of the proposed method was confirmed.
Random Projection in Neural Episodic Control
Apr 14, 2019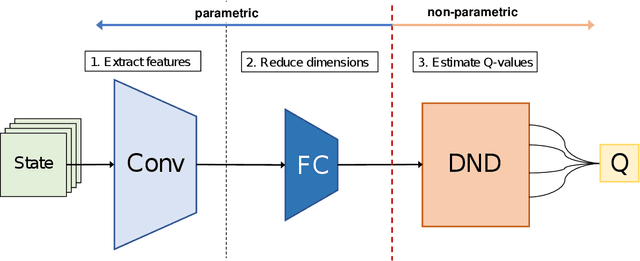

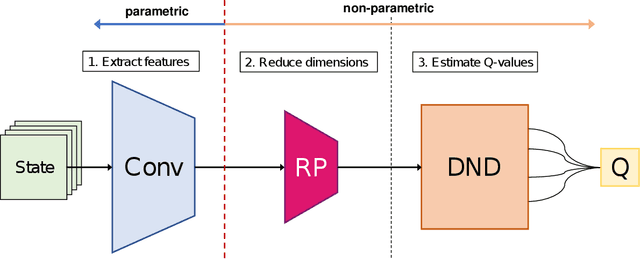

End-to-end deep reinforcement learning has enabled agents to learn with little preprocessing by humans. However, it is still difficult to learn stably and efficiently because the learning method usually uses a nonlinear function approximation. Neural Episodic Control (NEC), which has been proposed in order to improve sample efficiency, is able to learn stably by estimating action values using a non-parametric method. In this paper, we propose an architecture that incorporates random projection into NEC to train with more stability. In addition, we verify the effectiveness of our architecture by Atari's five games. The main idea is to reduce the number of parameters that have to learn by replacing neural networks with random projection in order to reduce dimensions while keeping the learning end-to-end.
Machine translation considering context information using Encoder-Decoder model
Mar 30, 2019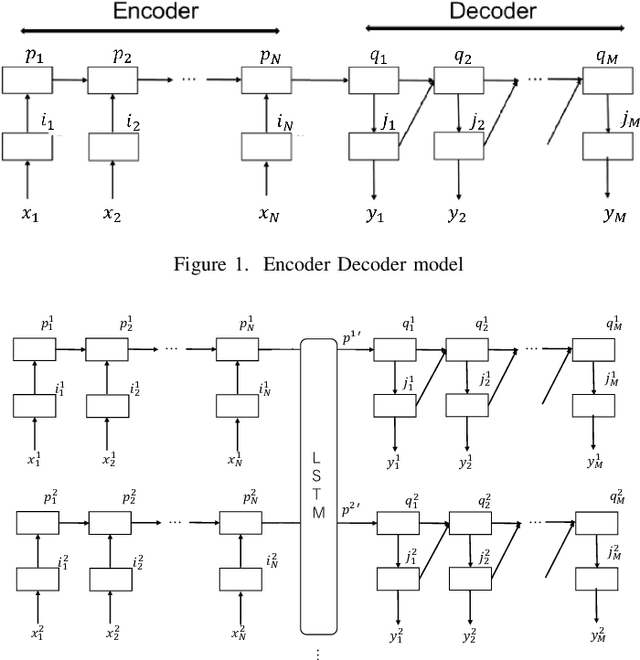


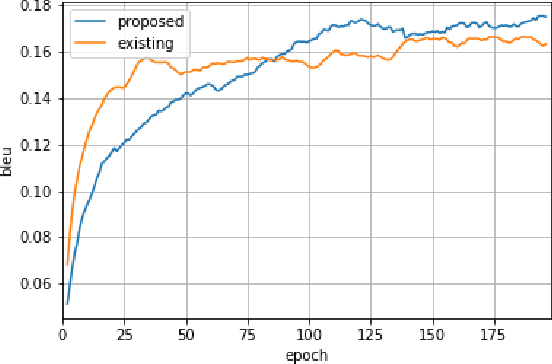
In the task of machine translation, context information is one of the important factor. But considering the context information model dose not proposed. The paper propose a new model which can integrate context information and make translation. In this paper, we create a new model based Encoder Decoder model. When translating current sentence, the model integrates output from preceding encoder with current encoder. The model can consider context information and the result score is higher than existing model.
Faster Deep Q-learning using Neural Episodic Control
Jun 03, 2018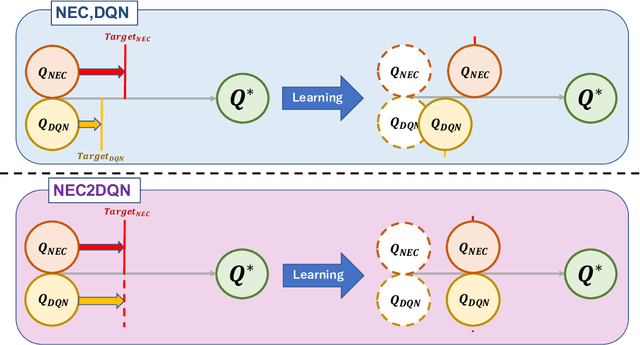
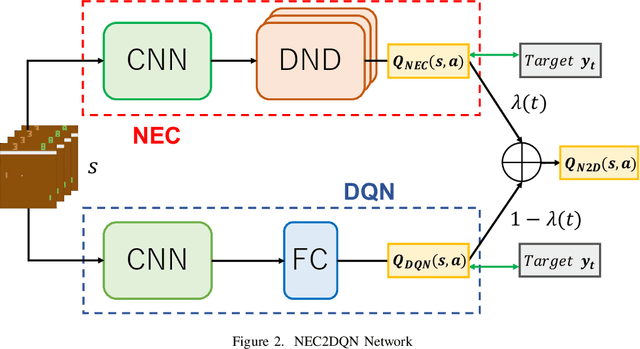

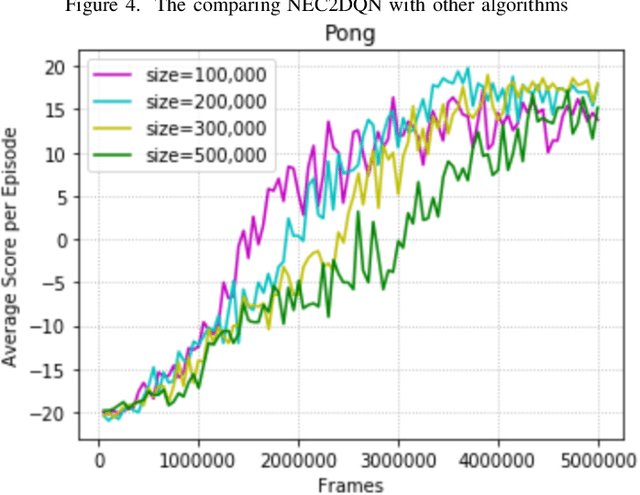
The research on deep reinforcement learning which estimates Q-value by deep learning has been attracted the interest of researchers recently. In deep reinforcement learning, it is important to efficiently learn the experiences that an agent has collected by exploring environment. We propose NEC2DQN that improves learning speed of a poor sample efficiency algorithm such as DQN by using good one such as NEC at the beginning of learning. We show it is able to learn faster than Double DQN or N-step DQN in the experiments of Pong.