Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Deep Q-learning using Neural Episodic Control
Paper and Code
Jun 03, 2018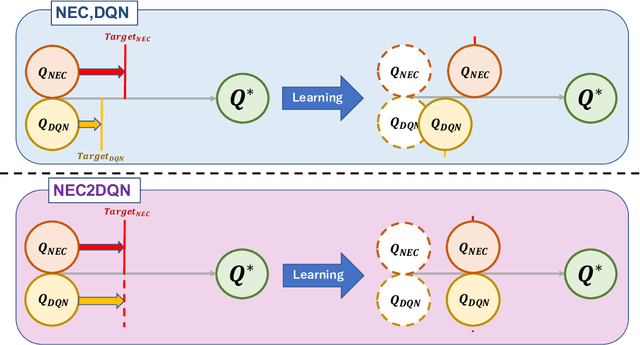
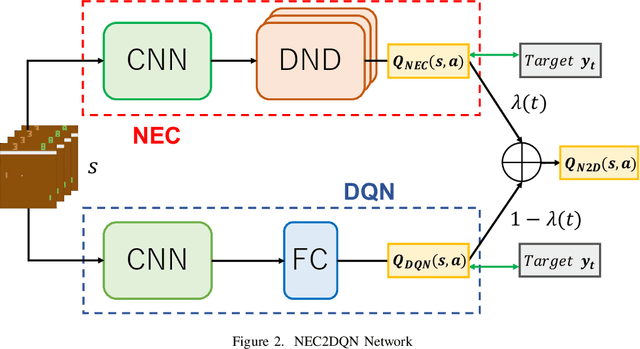

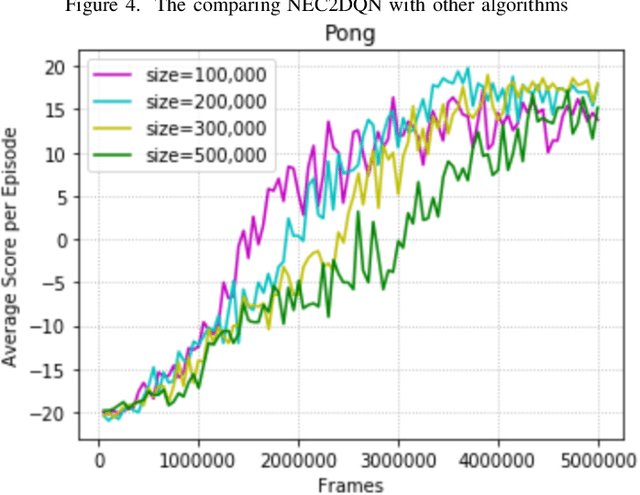
The research on deep reinforcement learning which estimates Q-value by deep learning has been attracted the interest of researchers recently. In deep reinforcement learning, it is important to efficiently learn the experiences that an agent has collected by exploring environment. We propose NEC2DQN that improves learning speed of a poor sample efficiency algorithm such as DQN by using good one such as NEC at the beginning of learning. We show it is able to learn faster than Double DQN or N-step DQN in the experiments of Pong.
* 6 pages, 6 figures, COMPSAC2018 short paper
View paper on