 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards robust and domain agnostic reinforcement learning competitions
Jun 07, 2021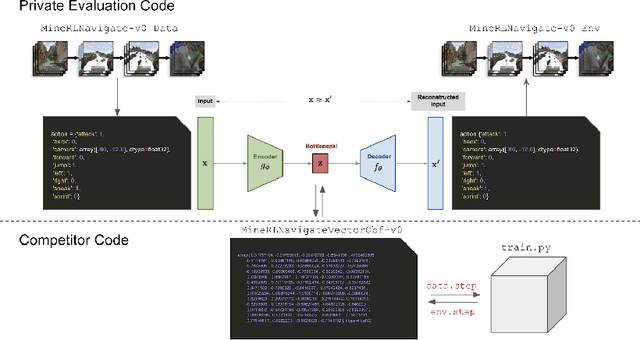

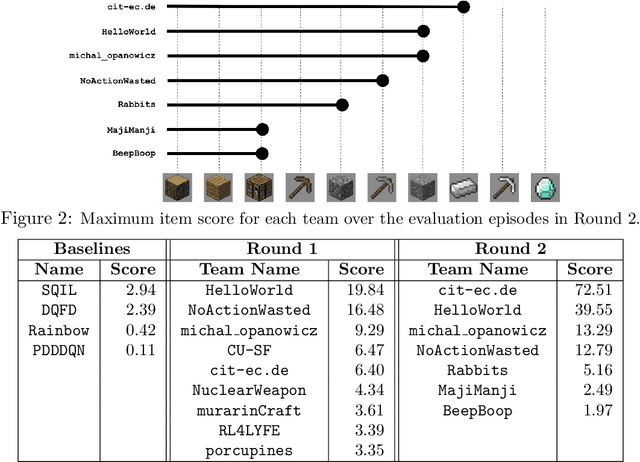
Reinforcement learning competitions have formed the basis for standard research benchmarks, galvanized advances in the state-of-the-art, and shaped the direction of the field. Despite this, a majority of challenges suffer from the same fundamental problems: participant solutions to the posed challenge are usually domain-specific, biased to maximally exploit compute resources, and not guaranteed to be reproducible. In this paper, we present a new framework of competition design that promotes the development of algorithms that overcome these barriers. We propose four central mechanisms for achieving this end: submission retraining, domain randomization, desemantization through domain obfuscation, and the limitation of competition compute and environment-sample budget. To demonstrate the efficacy of this design, we proposed, organized, and ran the MineRL 2020 Competition on Sample-Efficient Reinforcement Learning. In this work, we describe the organizational outcomes of the competition and show that the resulting participant submissions are reproducible, non-specific to the competition environment, and sample/resource efficient, despite the difficult competition task.
Discriminator Soft Actor Critic without Extrinsic Rewards
Jan 31, 2020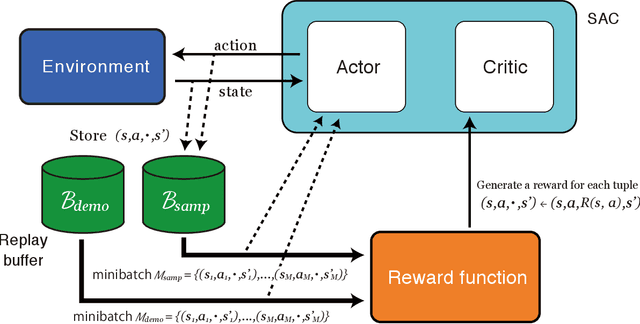

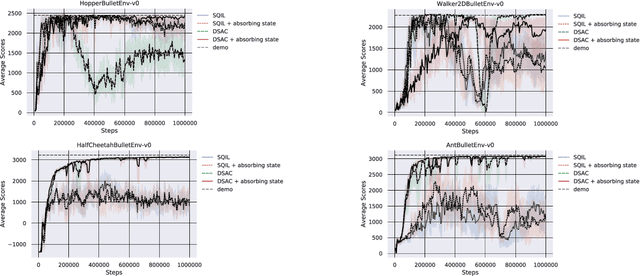
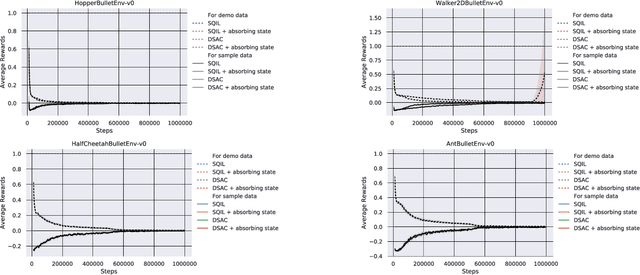
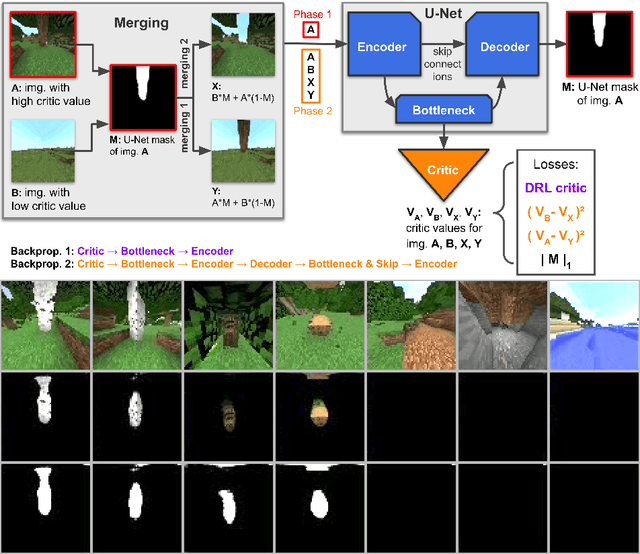
It is difficult to be able to imitate well in unknown states from a small amount of expert data and sampling data. Supervised learning methods such as Behavioral Cloning do not require sampling data, but usually suffer from distribution shift. The methods based on reinforcement learning, such as inverse reinforcement learning and generative adversarial imitation learning (GAIL), can learn from only a few expert data. However, they often need to interact with the environment. Soft Q imitation learning addressed the problems, and it was shown that it could learn efficiently by combining Behavioral Cloning and soft Q-learning with constant rewards. In order to make this algorithm more robust to distribution shift, we propose Discriminator Soft Actor Critic (DSAC). It uses a reward function based on adversarial inverse reinforcement learning instead of constant rewards. We evaluated it on PyBullet environments with only four expert trajectories.
Random Projection in Neural Episodic Control
Apr 14, 2019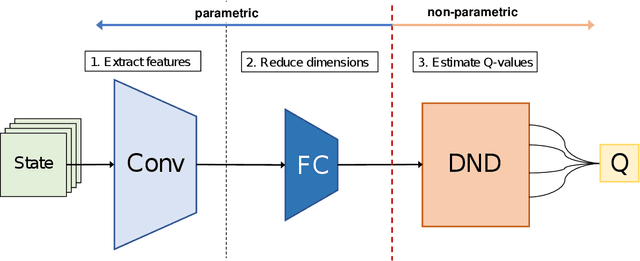

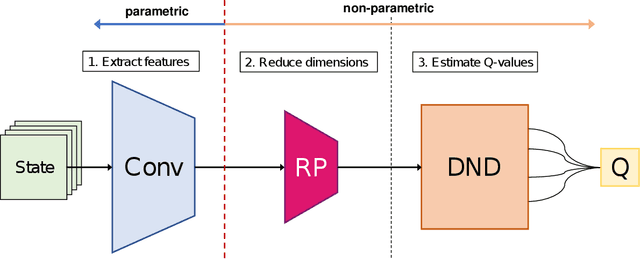

End-to-end deep reinforcement learning has enabled agents to learn with little preprocessing by humans. However, it is still difficult to learn stably and efficiently because the learning method usually uses a nonlinear function approximation. Neural Episodic Control (NEC), which has been proposed in order to improve sample efficiency, is able to learn stably by estimating action values using a non-parametric method. In this paper, we propose an architecture that incorporates random projection into NEC to train with more stability. In addition, we verify the effectiveness of our architecture by Atari's five games. The main idea is to reduce the number of parameters that have to learn by replacing neural networks with random projection in order to reduce dimensions while keeping the learning end-to-end.
Faster Deep Q-learning using Neural Episodic Control
Jun 03, 2018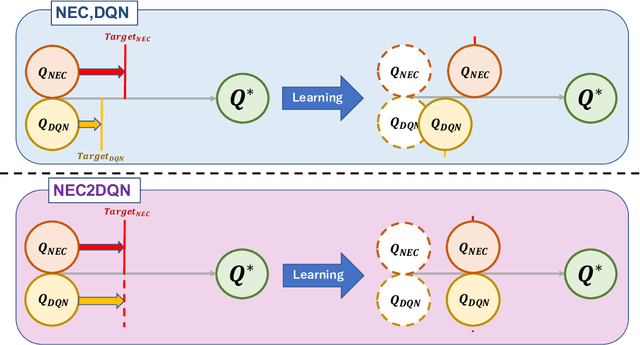
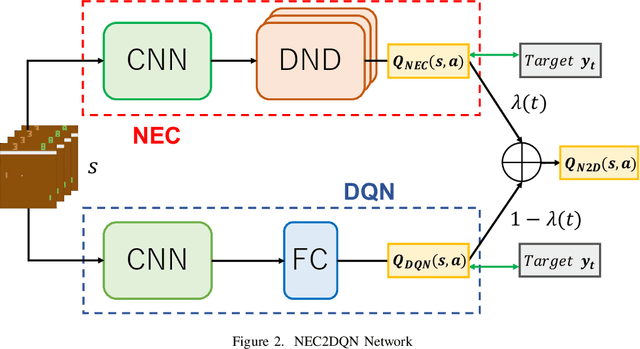

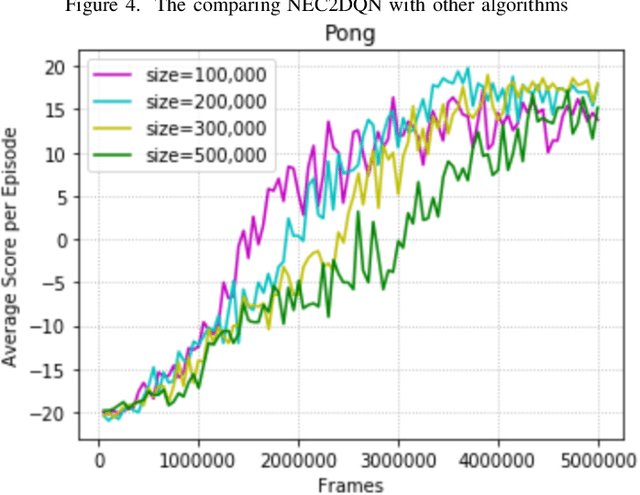
The research on deep reinforcement learning which estimates Q-value by deep learning has been attracted the interest of researchers recently. In deep reinforcement learning, it is important to efficiently learn the experiences that an agent has collected by exploring environment. We propose NEC2DQN that improves learning speed of a poor sample efficiency algorithm such as DQN by using good one such as NEC at the beginning of learning. We show it is able to learn faster than Double DQN or N-step DQN in the experiments of Pong.