 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines
Oct 16, 2024



Vision Language Models (VLMs) often struggle with culture-specific knowledge, particularly in languages other than English and in underrepresented cultural contexts. To evaluate their understanding of such knowledge, we introduce WorldCuisines, a massive-scale benchmark for multilingual and multicultural, visually grounded language understanding. This benchmark includes a visual question answering (VQA) dataset with text-image pairs across 30 languages and dialects, spanning 9 language families and featuring over 1 million data points, making it the largest multicultural VQA benchmark to date. It includes tasks for identifying dish names and their origins. We provide evaluation datasets in two sizes (12k and 60k instances) alongside a training dataset (1 million instances). Our findings show that while VLMs perform better with correct location context, they struggle with adversarial contexts and predicting specific regional cuisines and languages. To support future research, we release a knowledge base with annotated food entries and images along with the VQA data.
Investigating Role of Big Five Personality Traits in Audio-Visual Rapport Estimation
Oct 07, 2024Automatic rapport estimation in social interactions is a central component of affective computing. Recent reports have shown that the estimation performance of rapport in initial interactions can be improved by using the participant's personality traits as the model's input. In this study, we investigate whether this findings applies to interactions between friends by developing rapport estimation models that utilize nonverbal cues (audio and facial expressions) as inputs. Our experimental results show that adding Big Five features (BFFs) to nonverbal features can improve the estimation performance of self-reported rapport in dyadic interactions between friends. Next, we demystify how BFFs improve the estimation performance of rapport through a comparative analysis between models with and without BFFs. We decompose rapport ratings into perceiver effects (people's tendency to rate other people), target effects (people's tendency to be rated by other people), and relationship effects (people's unique ratings for a specific person) using the social relations model. We then analyze the extent to which BFFs contribute to capturing each effect. Our analysis demonstrates that the perceiver's and the target's BFFs lead estimation models to capture the perceiver and the target effects, respectively. Furthermore, our experimental results indicate that the combinations of facial expression features and BFFs achieve best estimation performances not only in estimating rapport ratings, but also in estimating three effects. Our study is the first step toward understanding why personality-aware estimation models of interpersonal perception accomplish high estimation performance.
BERP: A Blind Estimator of Room Acoustic and Physical Parameters for Single-Channel Noisy Speech Signals
May 07, 2024



Room acoustic parameters (RAPs) and room physical parameters ( RPPs) are essential metrics for parameterizing the room acoustical characteristics (RAC) of a sound field around a listener's local environment, offering comprehensive indications for various applications. The current RAPs and RPPs estimation methods either fall short of covering broad real-world acoustic environments in the context of real background noise or lack universal frameworks for blindly estimating RAPs and RPPs from noisy single-channel speech signals, particularly sound source distances, direction-of-arrival (DOA) of sound sources, and occupancy levels. On the other hand, in this paper, we propose a novel universal blind estimation framework called the blind estimator of room acoustical and physical parameters (BERP), by introducing a new stochastic room impulse response (RIR) model, namely, the sparse stochastic impulse response (SSIR) model, and endowing the BERP with a unified encoder and multiple separate predictors to estimate RPPs and SSIR parameters in parallel. This estimation framework enables the computationally efficient and universal estimation of room parameters by solely using noisy single-channel speech signals. Finally, all the RAPs can be simultaneously derived from the RIRs synthesized from SSIR model with the estimated parameters. To evaluate the effectiveness of the proposed BERP and SSIR models, we compile a task-specific dataset from several publicly available datasets. The results reveal that the BERP achieves state-of-the-art (SOTA) performance. Moreover, the evaluation results pertaining to the SSIR RIR model also demonstrated its efficacy. The code is available on GitHub.
FedCPC: An Effective Federated Contrastive Learning Method for Privacy Preserving Early-Stage Alzheimer's Speech Detection
Nov 21, 2023The early-stage Alzheimer's disease (AD) detection has been considered an important field of medical studies. Like traditional machine learning methods, speech-based automatic detection also suffers from data privacy risks because the data of specific patients are exclusive to each medical institution. A common practice is to use federated learning to protect the patients' data privacy. However, its distributed learning process also causes performance reduction. To alleviate this problem while protecting user privacy, we propose a federated contrastive pre-training (FedCPC) performed before federated training for AD speech detection, which can learn a better representation from raw data and enables different clients to share data in the pre-training and training stages. Experimental results demonstrate that the proposed methods can achieve satisfactory performance while preserving data privacy.
Interpretable multimodal sentiment analysis based on textual modality descriptions by using large-scale language models
May 12, 2023Multimodal sentiment analysis is an important area for understanding the user's internal states. Deep learning methods were effective, but the problem of poor interpretability has gradually gained attention. Previous works have attempted to use attention weights or vector distributions to provide interpretability. However, their explanations were not intuitive and can be influenced by different trained models. This study proposed a novel approach to provide interpretability by converting nonverbal modalities into text descriptions and by using large-scale language models for sentiment predictions. This provides an intuitive approach to directly interpret what models depend on with respect to making decisions from input texts, thus significantly improving interpretability. Specifically, we convert descriptions based on two feature patterns for the audio modality and discrete action units for the facial modality. Experimental results on two sentiment analysis tasks demonstrated that the proposed approach maintained, or even improved effectiveness for sentiment analysis compared to baselines using conventional features, with the highest improvement of 2.49% on the F1 score. The results also showed that multimodal descriptions have similar characteristics on fusing modalities as those of conventional fusion methods. The results demonstrated that the proposed approach is interpretable and effective for multimodal sentiment analysis.
Estimating Driver Personality Traits from On-Road Driving Data
Feb 09, 2023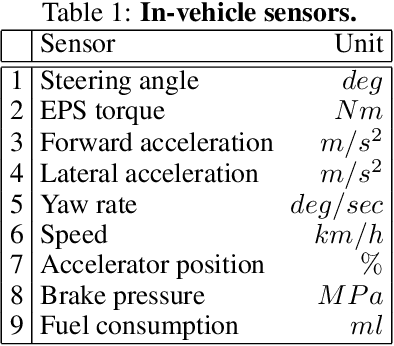
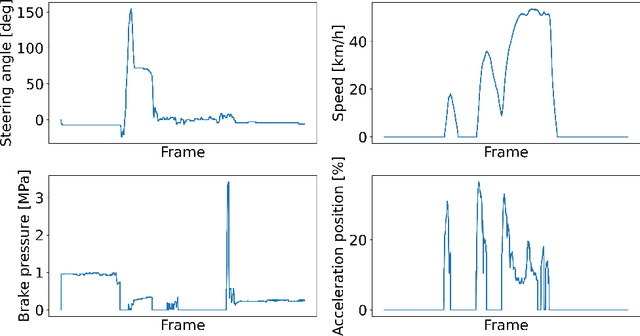

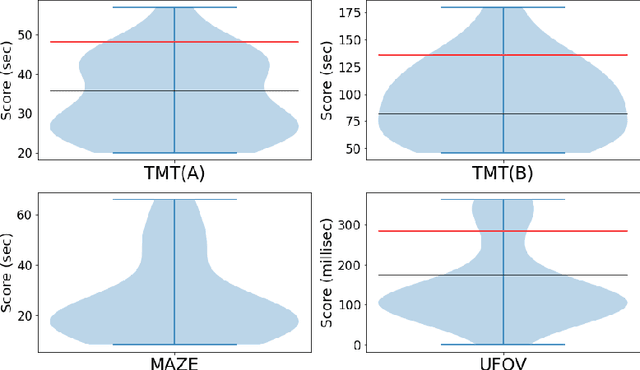
Driving assistance systems that support drivers by adapting individual psychological characteristics can provide appropriate feedback and prevent traffic accidents. As a first step toward implementing such adaptive assistance systems, this research aims to develop a model to estimate drivers' psychological characteristics, such as cognitive function, psychological driving style, and workload sensitivity, from on-road driving behavioral data using machine learning and deep learning techniques. We also investigated the relationship between driving behavior and various cognitive functions including the Trail Making test and Useful Field of View test through regression modeling. The proposed method focuses on road type information and captures various durations of time-series data observed from driving behaviors. First, we segment the driving time-series data into two road types, namely, arterial roads and intersections, to consider driving situations. Second, we further segment data into many sequences of various durations. Third, statistics are calculated from each sequence. Finally, these statistics are used as input features of machine learning models to predict psychological characteristics. The experimental results show that our model can predict a driver's cognitive function, namely, the Trail Making Test version B and Useful Field of View test scores, with Pearson correlation coefficients $r$ of 0.579 and 0.557, respectively. Some characteristics, such as psychological driving style and workload sensitivity, are predicted with high accuracy, but whether various duration segmentation improves accuracy depends on the characteristics, and it is not effective for all characteristics. Additionally, we reveal important sensor and road types for the estimation of cognitive function.
IDPS Signature Classification with a Reject Option and the Incorporation of Expert Knowledge
Jul 19, 2022

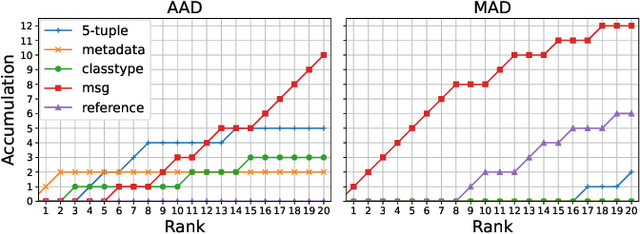
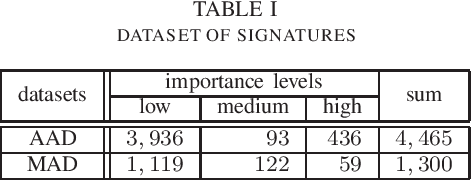
As the importance of intrusion detection and prevention systems (IDPSs) increases, great costs are incurred to manage the signatures that are generated by malicious communication pattern files. Experts in network security need to classify signatures by importance for an IDPS to work. We propose and evaluate a machine learning signature classification model with a reject option (RO) to reduce the cost of setting up an IDPS. To train the proposed model, it is essential to design features that are effective for signature classification. Experts classify signatures with predefined if-then rules. An if-then rule returns a label of low, medium, high, or unknown importance based on keyword matching of the elements in the signature. Therefore, we first design two types of features, symbolic features (SFs) and keyword features (KFs), which are used in keyword matching for the if-then rules. Next, we design web information and message features (WMFs) to capture the properties of signatures that do not match the if-then rules. The WMFs are extracted as term frequency-inverse document frequency (TF-IDF) features of the message text in the signatures. The features are obtained by web scraping from the referenced external attack identification systems described in the signature. Because failure needs to be minimized in the classification of IDPS signatures, as in the medical field, we consider introducing a RO in our proposed model. The effectiveness of the proposed classification model is evaluated in experiments with two real datasets composed of signatures labeled by experts: a dataset that can be classified with if-then rules and a dataset with elements that do not match an if-then rule. In the experiment, the proposed model is evaluated. In both cases, the combined SFs and WMFs performed better than the combined SFs and KFs. In addition, we also performed feature analysis.