 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskAlign: Token-Subset Representation Alignment for Efficient Diffusion Training
Jun 07, 2026Representation alignment with pretrained vision models has recently shown strong potential for accelerating diffusion transformer training. By aligning intermediate diffusion features with clean-image representations from self-supervised vision encoders, existing methods improve convergence and generation quality. However, such alignment also introduces a non-trivial constraint: diffusion models operate on noisy inputs whose usable information varies across timesteps, while the reference features are extracted from clean images. In this paper, we revisit this mismatch from a token-level perspective. We find that, under full-token representation alignment, tokens with large alignment-gradient norms exhibit a stable spatial preference, suggesting that the alignment objective does not affect all tokens uniformly and may encourage the model to rely on the complete set of clean-image tokens. To address this issue, we propose MaskAlign, a token-subset representation alignment method that applies alignment to randomly sampled token subsets during training. By exposing the model to different token subsets across iterations, MaskAlign reduces the dependence of representation alignment on the complete token set and encourages alignment behavior that is more stable under token-subset perturbations. To mitigate the information loss caused by directly dropping tokens, we further introduce a lightweight pre-mask token mixing block that shares information across tokens before masking.
Tiny Model, Big Logic: Diversity-Driven Optimization Elicits Large-Model Reasoning Ability in VibeThinker-1.5B
Nov 09, 2025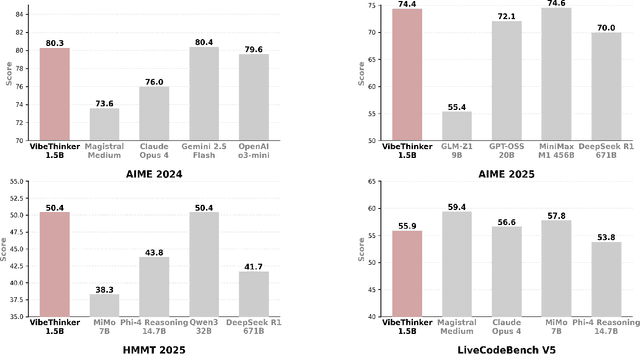

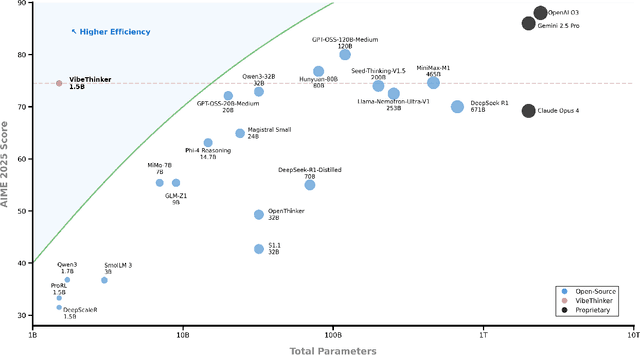
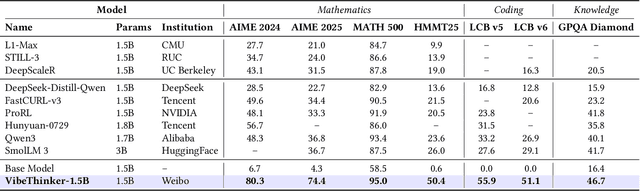
Challenging the prevailing consensus that small models inherently lack robust reasoning, this report introduces VibeThinker-1.5B, a 1.5B-parameter dense model developed via our Spectrum-to-Signal Principle (SSP). This challenges the prevailing approach of scaling model parameters to enhance capabilities, as seen in models like DeepSeek R1 (671B) and Kimi k2 (>1T). The SSP framework first employs a Two-Stage Diversity-Exploring Distillation (SFT) to generate a broad spectrum of solutions, followed by MaxEnt-Guided Policy Optimization (RL) to amplify the correct signal. With a total training cost of only $7,800, VibeThinker-1.5B demonstrates superior reasoning capabilities compared to closed-source models like Magistral Medium and Claude Opus 4, and performs on par with open-source models like GPT OSS-20B Medium. Remarkably, it surpasses the 400x larger DeepSeek R1 on three math benchmarks: AIME24 (80.3 vs. 79.8), AIME25 (74.4 vs. 70.0), and HMMT25 (50.4 vs. 41.7). This is a substantial improvement over its base model (6.7, 4.3, and 0.6, respectively). On LiveCodeBench V6, it scores 51.1, outperforming Magistral Medium's 50.3 and its base model's 0.0. These findings demonstrate that small models can achieve reasoning capabilities comparable to large models, drastically reducing training and inference costs and thereby democratizing advanced AI research.
CoRe: Context-Regularized Text Embedding Learning for Text-to-Image Personalization
Aug 28, 2024
Recent advances in text-to-image personalization have enabled high-quality and controllable image synthesis for user-provided concepts. However, existing methods still struggle to balance identity preservation with text alignment. Our approach is based on the fact that generating prompt-aligned images requires a precise semantic understanding of the prompt, which involves accurately processing the interactions between the new concept and its surrounding context tokens within the CLIP text encoder. To address this, we aim to embed the new concept properly into the input embedding space of the text encoder, allowing for seamless integration with existing tokens. We introduce Context Regularization (CoRe), which enhances the learning of the new concept's text embedding by regularizing its context tokens in the prompt. This is based on the insight that appropriate output vectors of the text encoder for the context tokens can only be achieved if the new concept's text embedding is correctly learned. CoRe can be applied to arbitrary prompts without requiring the generation of corresponding images, thus improving the generalization of the learned text embedding. Additionally, CoRe can serve as a test-time optimization technique to further enhance the generations for specific prompts. Comprehensive experiments demonstrate that our method outperforms several baseline methods in both identity preservation and text alignment. Code will be made publicly available.
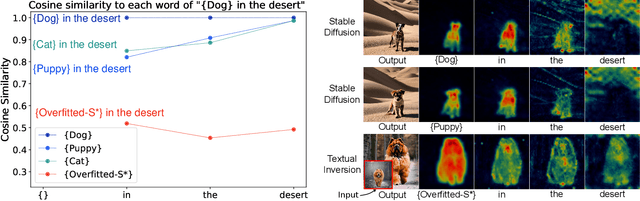
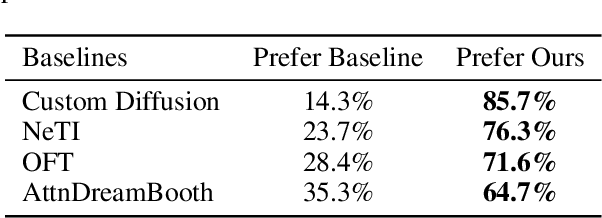
AttnDreamBooth: Towards Text-Aligned Personalized Text-to-Image Generation
Jun 07, 2024


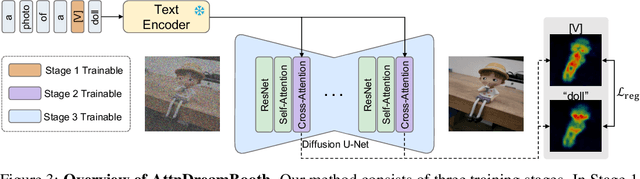
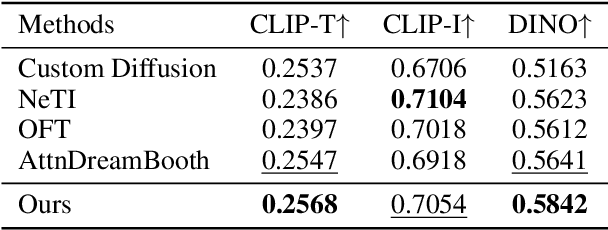
Recent advances in text-to-image models have enabled high-quality personalized image synthesis of user-provided concepts with flexible textual control. In this work, we analyze the limitations of two primary techniques in text-to-image personalization: Textual Inversion and DreamBooth. When integrating the learned concept into new prompts, Textual Inversion tends to overfit the concept, while DreamBooth often overlooks it. We attribute these issues to the incorrect learning of the embedding alignment for the concept. We introduce AttnDreamBooth, a novel approach that addresses these issues by separately learning the embedding alignment, the attention map, and the subject identity in different training stages. We also introduce a cross-attention map regularization term to enhance the learning of the attention map. Our method demonstrates significant improvements in identity preservation and text alignment compared to the baseline methods.
Cross Initialization for Personalized Text-to-Image Generation
Dec 26, 2023Recently, there has been a surge in face personalization techniques, benefiting from the advanced capabilities of pretrained text-to-image diffusion models. Among these, a notable method is Textual Inversion, which generates personalized images by inverting given images into textual embeddings. However, methods based on Textual Inversion still struggle with balancing the trade-off between reconstruction quality and editability. In this study, we examine this issue through the lens of initialization. Upon closely examining traditional initialization methods, we identified a significant disparity between the initial and learned embeddings in terms of both scale and orientation. The scale of the learned embedding can be up to 100 times greater than that of the initial embedding. Such a significant change in the embedding could increase the risk of overfitting, thereby compromising the editability. Driven by this observation, we introduce a novel initialization method, termed Cross Initialization, that significantly narrows the gap between the initial and learned embeddings. This method not only improves both reconstruction and editability but also reduces the optimization steps from 5000 to 320. Furthermore, we apply a regularization term to keep the learned embedding close to the initial embedding. We show that when combined with Cross Initialization, this regularization term can effectively improve editability. We provide comprehensive empirical evidence to demonstrate the superior performance of our method compared to the baseline methods. Notably, in our experiments, Cross Initialization is the only method that successfully edits an individual's facial expression. Additionally, a fast version of our method allows for capturing an input image in roughly 26 seconds, while surpassing the baseline methods in terms of both reconstruction and editability. Code will be made publicly available.