 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Conformers via Sharing Sparsely-Gated Experts for End-to-End Speech Recognition
Sep 17, 2022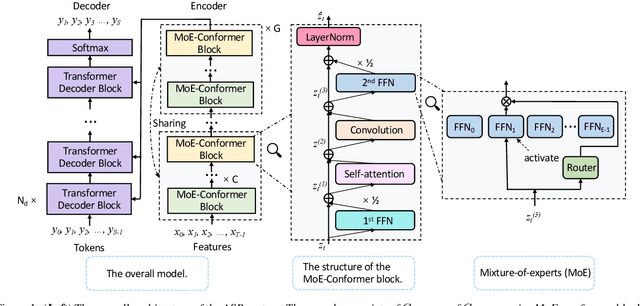
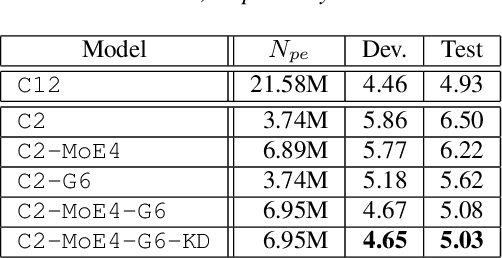

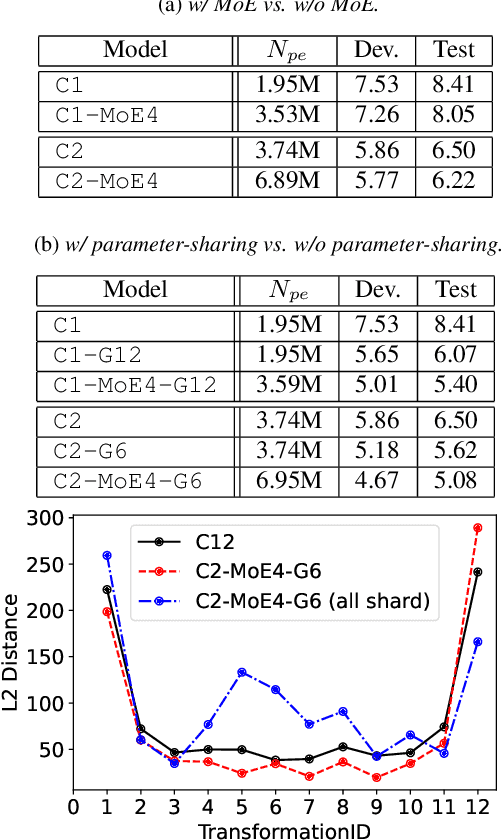
While transformers and their variant conformers show promising performance in speech recognition, the parameterized property leads to much memory cost during training and inference. Some works use cross-layer weight-sharing to reduce the parameters of the model. However, the inevitable loss of capacity harms the model performance. To address this issue, this paper proposes a parameter-efficient conformer via sharing sparsely-gated experts. Specifically, we use sparsely-gated mixture-of-experts (MoE) to extend the capacity of a conformer block without increasing computation. Then, the parameters of the grouped conformer blocks are shared so that the number of parameters is reduced. Next, to ensure the shared blocks with the flexibility of adapting representations at different levels, we design the MoE routers and normalization individually. Moreover, we use knowledge distillation to further improve the performance. Experimental results show that the proposed model achieves competitive performance with 1/3 of the parameters of the encoder, compared with the full-parameter model.