 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Boosting Code-Switching ASR with Mixture of Experts Enhanced Speech-Conditioned LLM
Sep 24, 2024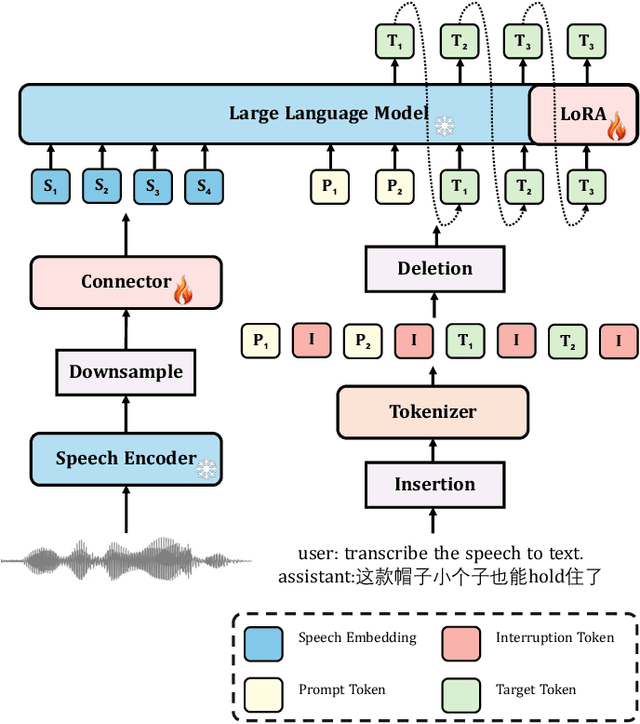
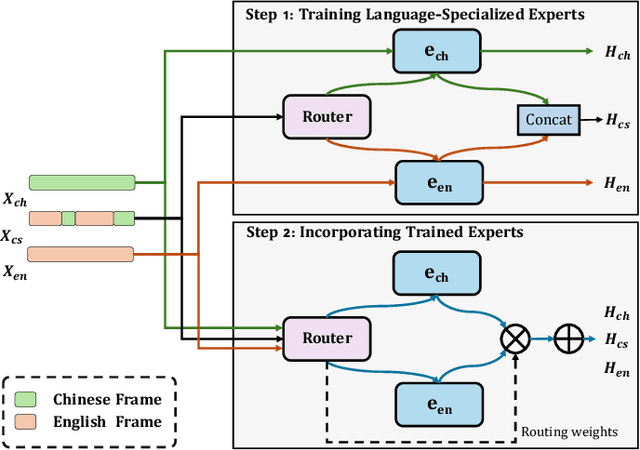
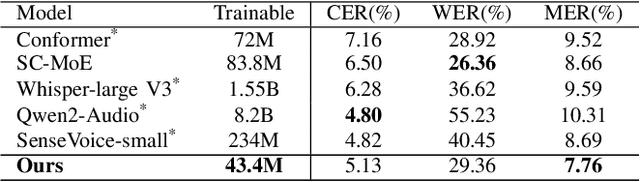

In this paper, we introduce a speech-conditioned Large Language Model (LLM) integrated with a Mixture of Experts (MoE) based connector to address the challenge of Code-Switching (CS) in Automatic Speech Recognition (ASR). Specifically, we propose an Insertion and Deletion of Interruption Token (IDIT) mechanism for better transfer text generation ability of LLM to speech recognition task. We also present a connecter with MoE architecture that manages multiple languages efficiently. To further enhance the collaboration of multiple experts and leverage the understanding capabilities of LLM, we propose a two-stage progressive training strategy: 1) The connector is unfrozen and trained with language-specialized experts to map speech representations to the text space. 2) The connector and LLM LoRA adaptor are trained with the proposed IDIT mechanism and all experts are activated to learn general representations. Experimental results demonstrate that our method significantly outperforms state-of-the-art models, including end-to-end and large-scale audio-language models.
Parameter-Efficient Conformers via Sharing Sparsely-Gated Experts for End-to-End Speech Recognition
Sep 17, 2022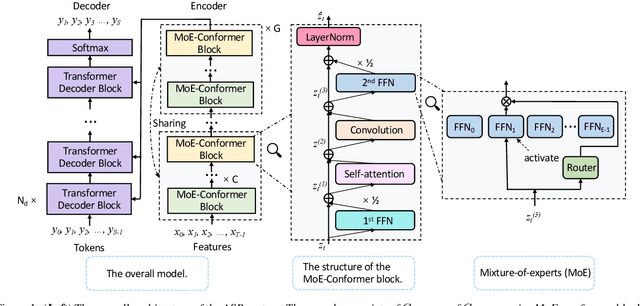
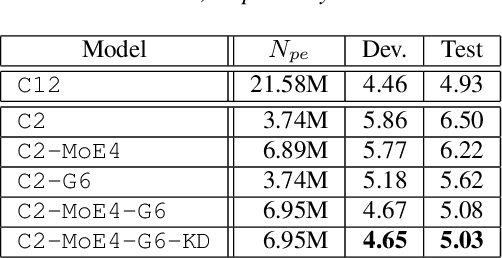

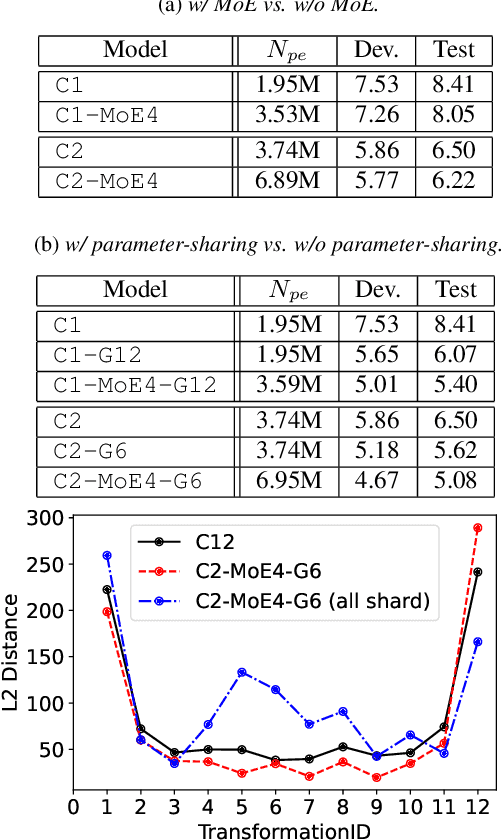
While transformers and their variant conformers show promising performance in speech recognition, the parameterized property leads to much memory cost during training and inference. Some works use cross-layer weight-sharing to reduce the parameters of the model. However, the inevitable loss of capacity harms the model performance. To address this issue, this paper proposes a parameter-efficient conformer via sharing sparsely-gated experts. Specifically, we use sparsely-gated mixture-of-experts (MoE) to extend the capacity of a conformer block without increasing computation. Then, the parameters of the grouped conformer blocks are shared so that the number of parameters is reduced. Next, to ensure the shared blocks with the flexibility of adapting representations at different levels, we design the MoE routers and normalization individually. Moreover, we use knowledge distillation to further improve the performance. Experimental results show that the proposed model achieves competitive performance with 1/3 of the parameters of the encoder, compared with the full-parameter model.
Efficiently Fusing Pretrained Acoustic and Linguistic Encoders for Low-resource Speech Recognition
Jan 24, 2021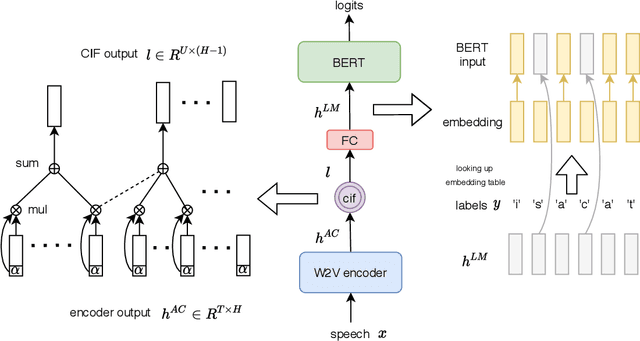
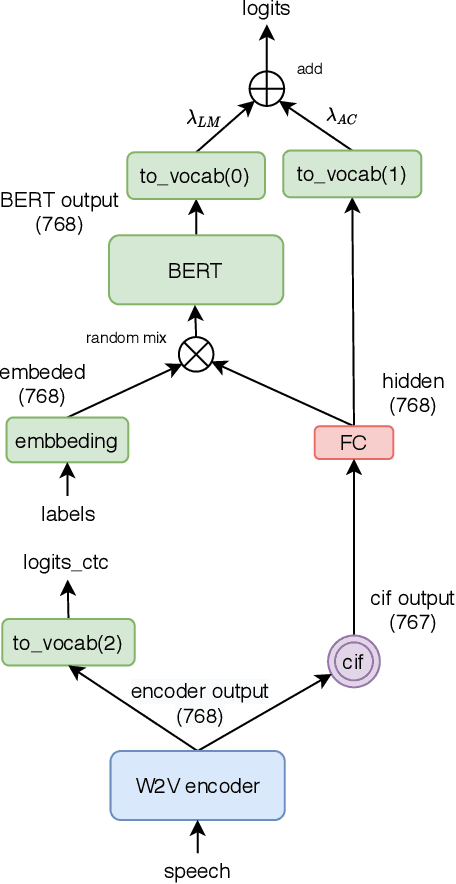
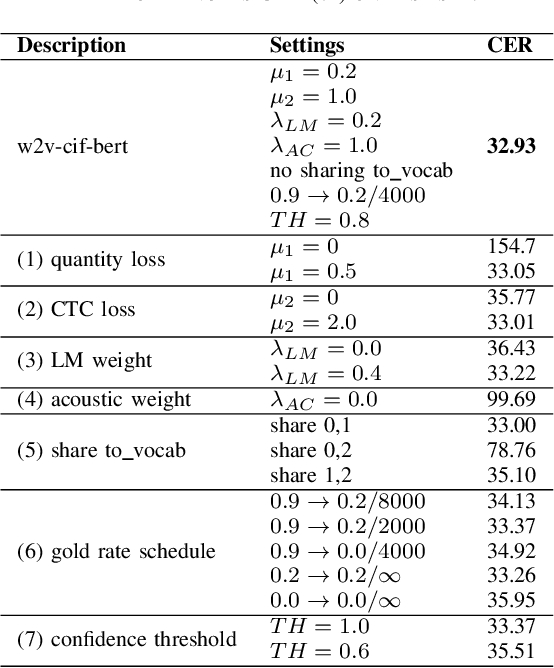
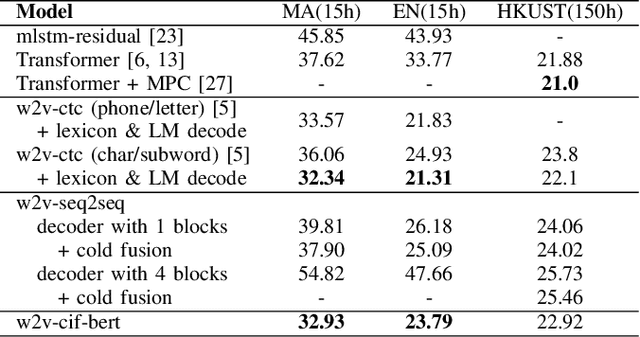
End-to-end models have achieved impressive results on the task of automatic speech recognition (ASR). For low-resource ASR tasks, however, labeled data can hardly satisfy the demand of end-to-end models. Self-supervised acoustic pre-training has already shown its amazing ASR performance, while the transcription is still inadequate for language modeling in end-to-end models. In this work, we fuse a pre-trained acoustic encoder (wav2vec2.0) and a pre-trained linguistic encoder (BERT) into an end-to-end ASR model. The fused model only needs to learn the transfer from speech to language during fine-tuning on limited labeled data. The length of the two modalities is matched by a monotonic attention mechanism without additional parameters. Besides, a fully connected layer is introduced for the hidden mapping between modalities. We further propose a scheduled fine-tuning strategy to preserve and utilize the text context modeling ability of the pre-trained linguistic encoder. Experiments show our effective utilizing of pre-trained modules. Our model achieves better recognition performance on CALLHOME corpus (15 hours) than other end-to-end models.
Applying Wav2vec2.0 to Speech Recognition in Various Low-resource Languages
Jan 17, 2021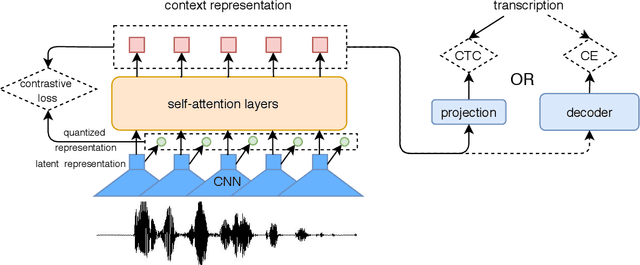
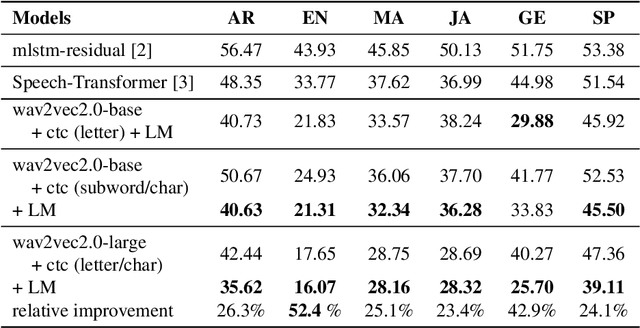
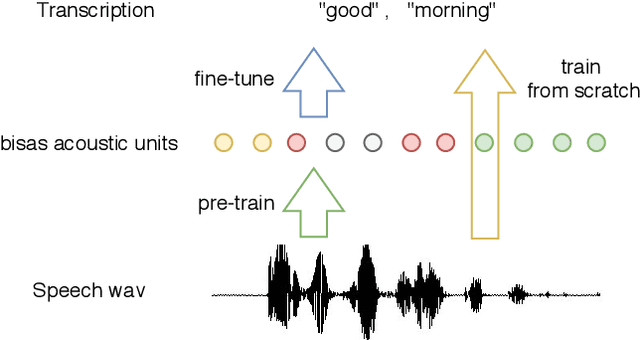
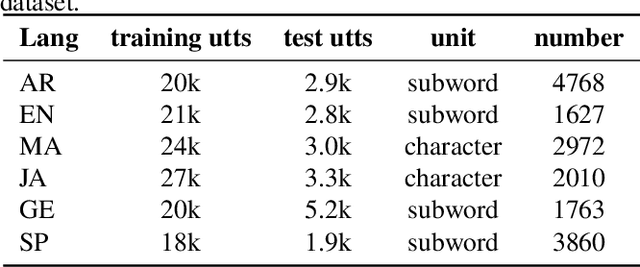
There are several domains that own corresponding widely used feature extractors, such as ResNet, BERT, and GPT-x. These models are usually pre-trained on large amounts of unlabeled data by self-supervision and can be effectively applied to downstream tasks. In the speech domain, wav2vec2.0 starts to show its powerful representation ability and feasibility of ultra-low resource speech recognition on the Librispeech corpus, which belongs to the audiobook domain. However, wav2vec2.0 has not been examined on real spoken scenarios and languages other than English. To verify its universality over languages, we apply pre-trained models to solve low-resource speech recognition tasks in various spoken languages. We achieve more than 20% relative improvements in six languages compared with previous work. Among these languages, English achieves a gain of 52.4%. Moreover, using coarse-grained modeling units, such as subword or character, achieves better results than fine-grained modeling units, such as phone or letter.
A Comparison of Label-Synchronous and Frame-Synchronous End-to-End Models for Speech Recognition
May 25, 2020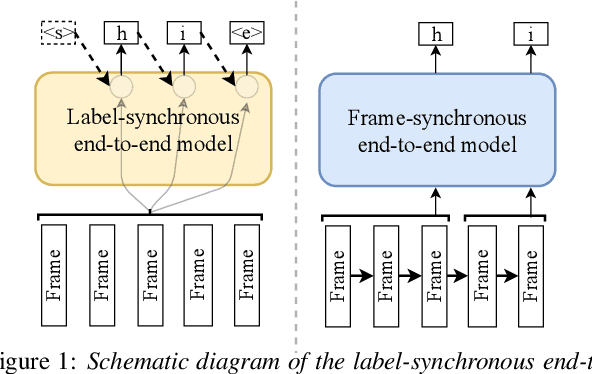

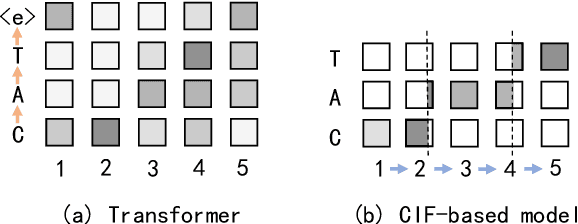
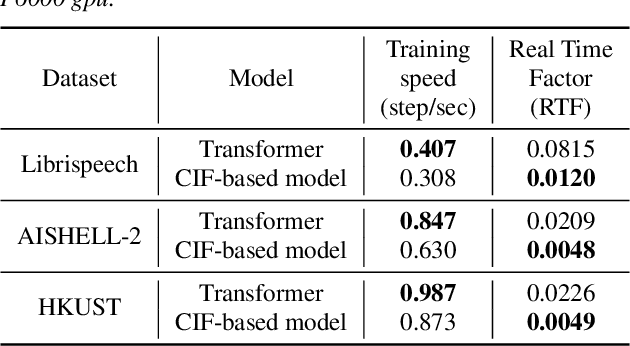
End-to-end models are gaining wider attention in the field of automatic speech recognition (ASR). One of their advantages is the simplicity of building that directly recognizes the speech frame sequence into the text label sequence by neural networks. According to the driving end in the recognition process, end-to-end ASR models could be categorized into two types: label-synchronous and frame-synchronous, each of which has unique model behaviour and characteristic. In this work, we make a detailed comparison on a representative label-synchronous model (transformer) and a soft frame-synchronous model (continuous integrate-and-fire (CIF) based model). The results on three public dataset and a large-scale dataset with 12000 hours of training data show that the two types of models have respective advantages that are consistent with their synchronous mode.