 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Transfer Learning for Low-resource Spoken Language Understanding
Aug 13, 2020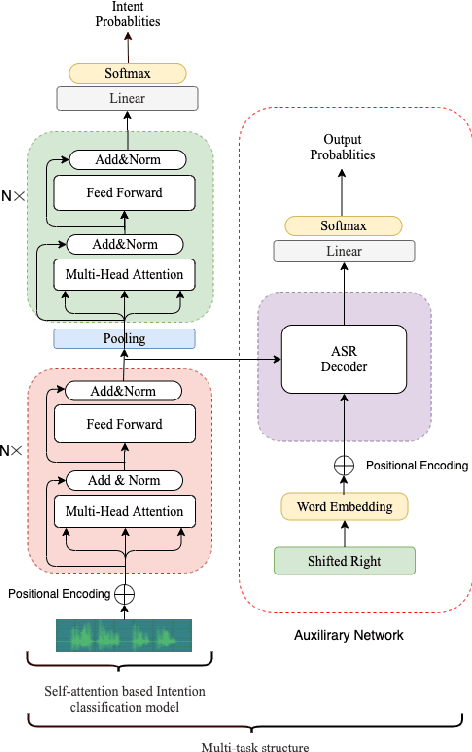
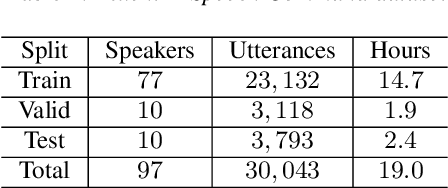
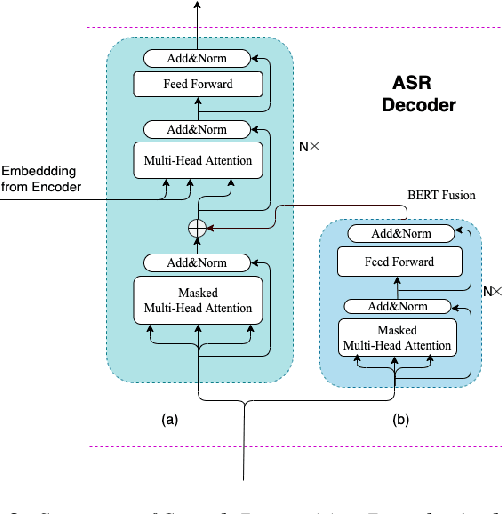
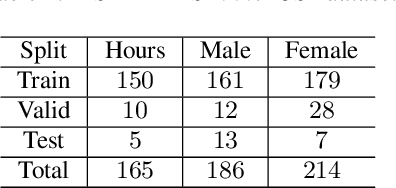
End-to-end Spoken Language Understanding (SLU) models are made increasingly large and complex to achieve the state-ofthe-art accuracy. However, the increased complexity of a model can also introduce high risk of over-fitting, which is a major challenge in SLU tasks due to the limitation of available data. In this paper, we propose an attention-based SLU model together with three encoder enhancement strategies to overcome data sparsity challenge. The first strategy focuses on the transferlearning approach to improve feature extraction capability of the encoder. It is implemented by pre-training the encoder component with a quantity of Automatic Speech Recognition annotated data relying on the standard Transformer architecture and then fine-tuning the SLU model with a small amount of target labelled data. The second strategy adopts multitask learning strategy, the SLU model integrates the speech recognition model by sharing the same underlying encoder, such that improving robustness and generalization ability. The third strategy, learning from Component Fusion (CF) idea, involves a Bidirectional Encoder Representation from Transformer (BERT) model and aims to boost the capability of the decoder with an auxiliary network. It hence reduces the risk of over-fitting and augments the ability of the underlying encoder, indirectly. Experiments on the FluentAI dataset show that cross-language transfer learning and multi-task strategies have been improved by up to 4:52% and 3:89% respectively, compared to the baseline.
A Comparison of Label-Synchronous and Frame-Synchronous End-to-End Models for Speech Recognition
May 25, 2020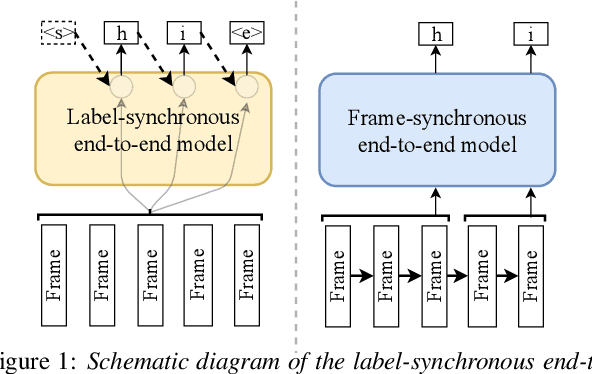

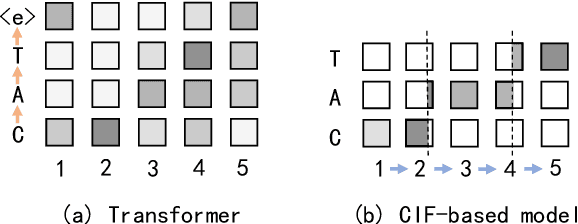
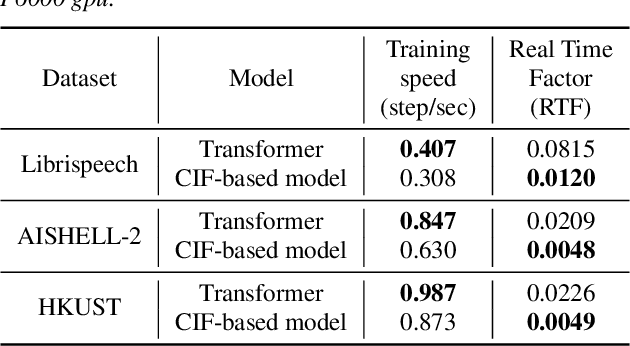
End-to-end models are gaining wider attention in the field of automatic speech recognition (ASR). One of their advantages is the simplicity of building that directly recognizes the speech frame sequence into the text label sequence by neural networks. According to the driving end in the recognition process, end-to-end ASR models could be categorized into two types: label-synchronous and frame-synchronous, each of which has unique model behaviour and characteristic. In this work, we make a detailed comparison on a representative label-synchronous model (transformer) and a soft frame-synchronous model (continuous integrate-and-fire (CIF) based model). The results on three public dataset and a large-scale dataset with 12000 hours of training data show that the two types of models have respective advantages that are consistent with their synchronous mode.