 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-LGM: Leveraging Object-Context Relation for Context-Aware Object Recognition
Paper and Code
Oct 08, 2021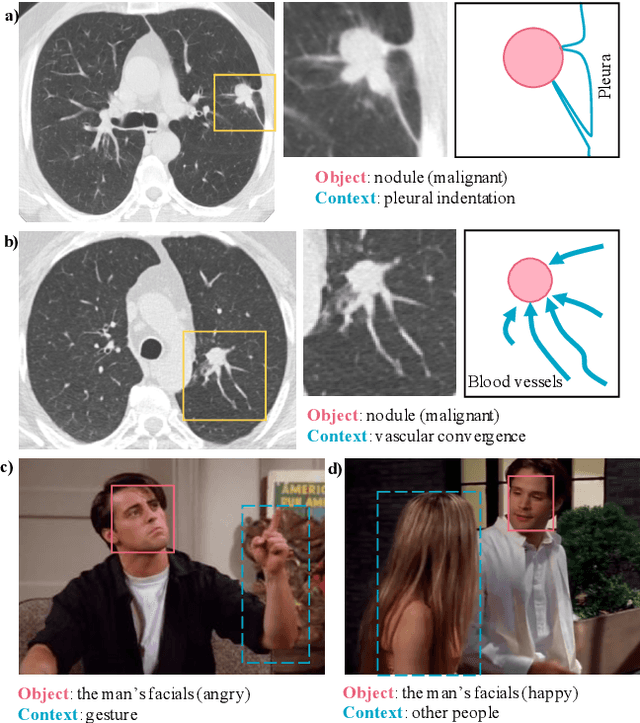
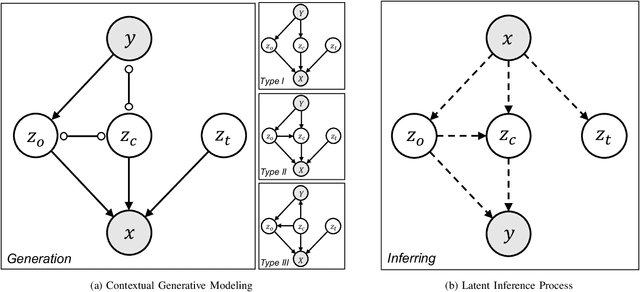
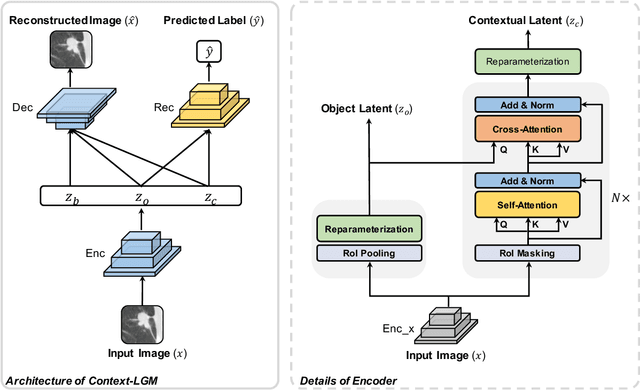
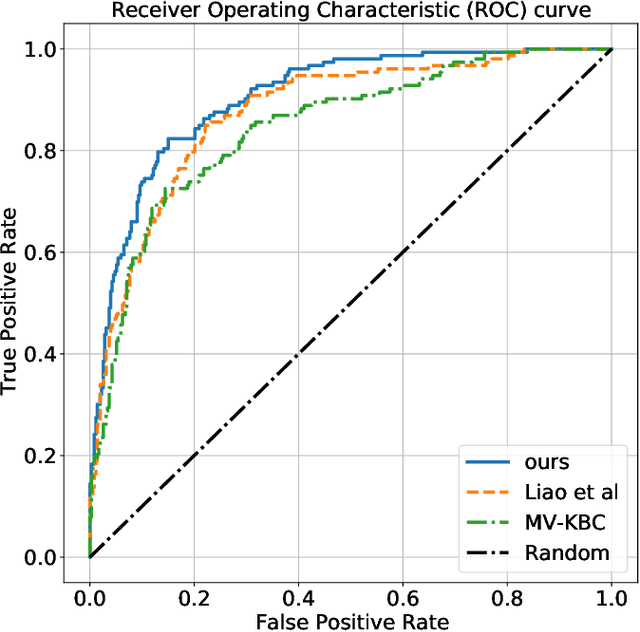
Context, as referred to situational factors related to the object of interest, can help infer the object's states or properties in visual recognition. As such contextual features are too diverse (across instances) to be annotated, existing attempts simply exploit image labels as supervision to learn them, resulting in various contextual tricks, such as features pyramid, context attention, etc. However, without carefully modeling the context's properties, especially its relation to the object, their estimated context can suffer from large inaccuracy. To amend this problem, we propose a novel Contextual Latent Generative Model (Context-LGM), which considers the object-context relation and models it in a hierarchical manner. Specifically, we firstly introduce a latent generative model with a pair of correlated latent variables to respectively model the object and context, and embed their correlation via the generative process. Then, to infer contextual features, we reformulate the objective function of Variational Auto-Encoder (VAE), where contextual features are learned as a posterior distribution conditioned on the object. Finally, to implement this contextual posterior, we introduce a Transformer that takes the object's information as a reference and locates correlated contextual factors. The effectiveness of our method is verified by state-of-the-art performance on two context-aware object recognition tasks, i.e. lung cancer prediction and emotion recognition.