 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Parameter Efficient Methods for RLVR
Dec 30, 2025We systematically evaluate Parameter-Efficient Fine-Tuning (PEFT) methods under the paradigm of Reinforcement Learning with Verifiable Rewards (RLVR). RLVR incentivizes language models to enhance their reasoning capabilities through verifiable feedback; however, while methods like LoRA are commonly used, the optimal PEFT architecture for RLVR remains unidentified. In this work, we conduct the first comprehensive evaluation of over 12 PEFT methodologies across the DeepSeek-R1-Distill families on mathematical reasoning benchmarks. Our empirical results challenge the default adoption of standard LoRA with three main findings. First, we demonstrate that structural variants, such as DoRA, AdaLoRA, and MiSS, consistently outperform LoRA. Second, we uncover a spectral collapse phenomenon in SVD-informed initialization strategies (\textit{e.g.,} PiSSA, MiLoRA), attributing their failure to a fundamental misalignment between principal-component updates and RL optimization. Furthermore, our ablations reveal that extreme parameter reduction (\textit{e.g.,} VeRA, Rank-1) severely bottlenecks reasoning capacity. We further conduct ablation studies and scaling experiments to validate our findings. This work provides a definitive guide for advocating for more exploration for parameter-efficient RL methods.
ProfBench: Multi-Domain Rubrics requiring Professional Knowledge to Answer and Judge
Oct 21, 2025

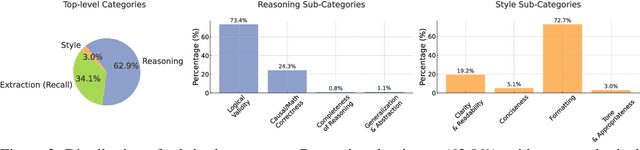

Evaluating progress in large language models (LLMs) is often constrained by the challenge of verifying responses, limiting assessments to tasks like mathematics, programming, and short-form question-answering. However, many real-world applications require evaluating LLMs in processing professional documents, synthesizing information, and generating comprehensive reports in response to user queries. We introduce ProfBench: a set of over 7000 response-criterion pairs as evaluated by human-experts with professional knowledge across Physics PhD, Chemistry PhD, Finance MBA and Consulting MBA. We build robust and affordable LLM-Judges to evaluate ProfBench rubrics, by mitigating self-enhancement bias and reducing the cost of evaluation by 2-3 orders of magnitude, to make it fair and accessible to the broader community. Our findings reveal that ProfBench poses significant challenges even for state-of-the-art LLMs, with top-performing models like GPT-5-high achieving only 65.9\% overall performance. Furthermore, we identify notable performance disparities between proprietary and open-weight models and provide insights into the role that extended thinking plays in addressing complex, professional-domain tasks. Data: https://huggingface.co/datasets/nvidia/ProfBench and Code: https://github.com/NVlabs/ProfBench
Reasoning over Boundaries: Enhancing Specification Alignment via Test-time Delibration
Sep 18, 2025Large language models (LLMs) are increasingly applied in diverse real-world scenarios, each governed by bespoke behavioral and safety specifications (spec) custom-tailored by users or organizations. These spec, categorized into safety-spec and behavioral-spec, vary across scenarios and evolve with changing preferences and requirements. We formalize this challenge as specification alignment, focusing on LLMs' ability to follow dynamic, scenario-specific spec from both behavioral and safety perspectives. To address this challenge, we propose Align3, a lightweight method that employs Test-Time Deliberation (TTD) with hierarchical reflection and revision to reason over the specification boundaries. We further present SpecBench, a unified benchmark for measuring specification alignment, covering 5 scenarios, 103 spec, and 1,500 prompts. Experiments on 15 reasoning and 18 instruct models with several TTD methods, including Self-Refine, TPO, and MoreThink, yield three key findings: (i) test-time deliberation enhances specification alignment; (ii) Align3 advances the safety-helpfulness trade-off frontier with minimal overhead; (iii) SpecBench effectively reveals alignment gaps. These results highlight the potential of test-time deliberation as an effective strategy for reasoning over the real-world specification boundaries.
Synthesizing Sheet Music Problems for Evaluation and Reinforcement Learning
Sep 04, 2025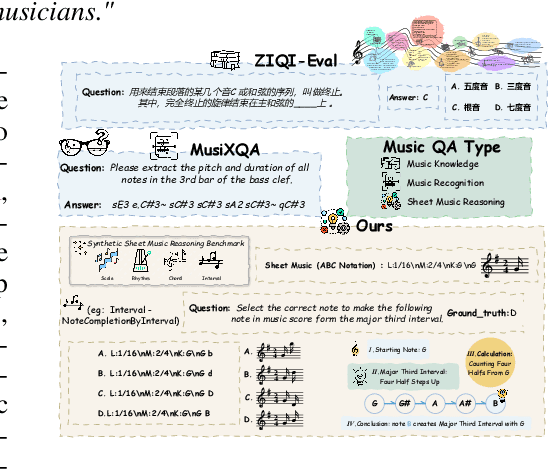

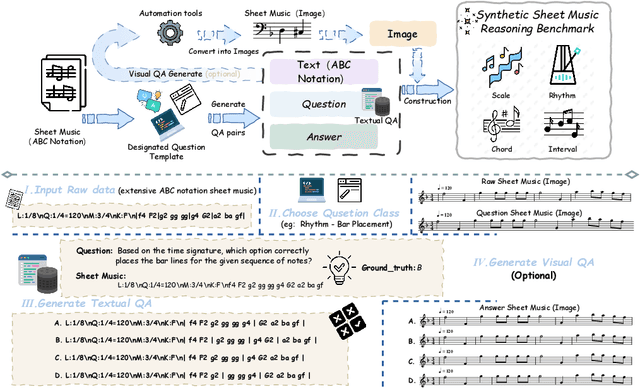
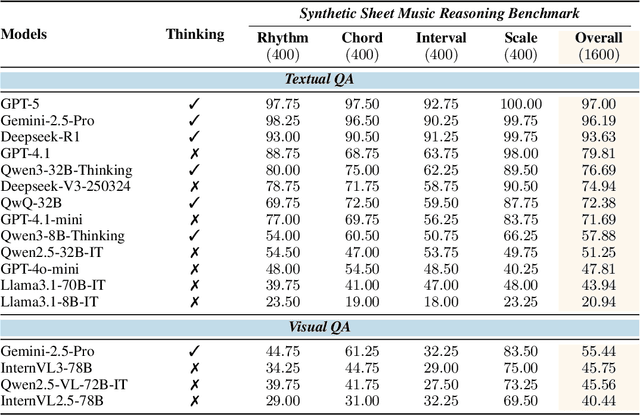
Enhancing the ability of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) to interpret sheet music is a crucial step toward building AI musicians. However, current research lacks both evaluation benchmarks and training data for sheet music reasoning. To address this, we propose the idea of synthesizing sheet music problems grounded in music theory, which can serve both as evaluation benchmarks and as training data for reinforcement learning with verifiable rewards (RLVR). We introduce a data synthesis framework that generates verifiable sheet music questions in both textual and visual modalities, leading to the Synthetic Sheet Music Reasoning Benchmark (SSMR-Bench) and a complementary training set. Evaluation results on SSMR-Bench show the importance of models' reasoning abilities in interpreting sheet music. At the same time, the poor performance of Gemini 2.5-Pro highlights the challenges that MLLMs still face in interpreting sheet music in a visual format. By leveraging synthetic data for RLVR, Qwen3-8B-Base and Qwen2.5-VL-Instruct achieve improvements on the SSMR-Bench. Besides, the trained Qwen3-8B-Base surpasses GPT-4 in overall performance on MusicTheoryBench and achieves reasoning performance comparable to GPT-4 with the strategies of Role play and Chain-of-Thought. Notably, its performance on math problems also improves relative to the original Qwen3-8B-Base. Furthermore, our results show that the enhanced reasoning ability can also facilitate music composition. In conclusion, we are the first to propose the idea of synthesizing sheet music problems based on music theory rules, and demonstrate its effectiveness not only in advancing model reasoning for sheet music understanding but also in unlocking new possibilities for AI-assisted music creation.
Will AI Tell Lies to Save Sick Children? Litmus-Testing AI Values Prioritization with AIRiskDilemmas
May 20, 2025Detecting AI risks becomes more challenging as stronger models emerge and find novel methods such as Alignment Faking to circumvent these detection attempts. Inspired by how risky behaviors in humans (i.e., illegal activities that may hurt others) are sometimes guided by strongly-held values, we believe that identifying values within AI models can be an early warning system for AI's risky behaviors. We create LitmusValues, an evaluation pipeline to reveal AI models' priorities on a range of AI value classes. Then, we collect AIRiskDilemmas, a diverse collection of dilemmas that pit values against one another in scenarios relevant to AI safety risks such as Power Seeking. By measuring an AI model's value prioritization using its aggregate choices, we obtain a self-consistent set of predicted value priorities that uncover potential risks. We show that values in LitmusValues (including seemingly innocuous ones like Care) can predict for both seen risky behaviors in AIRiskDilemmas and unseen risky behaviors in HarmBench.
HelpSteer3-Preference: Open Human-Annotated Preference Data across Diverse Tasks and Languages
May 16, 2025Preference datasets are essential for training general-domain, instruction-following language models with Reinforcement Learning from Human Feedback (RLHF). Each subsequent data release raises expectations for future data collection, meaning there is a constant need to advance the quality and diversity of openly available preference data. To address this need, we introduce HelpSteer3-Preference, a permissively licensed (CC-BY-4.0), high-quality, human-annotated preference dataset comprising of over 40,000 samples. These samples span diverse real-world applications of large language models (LLMs), including tasks relating to STEM, coding and multilingual scenarios. Using HelpSteer3-Preference, we train Reward Models (RMs) that achieve top performance on RM-Bench (82.4%) and JudgeBench (73.7%). This represents a substantial improvement (~10% absolute) over the previously best-reported results from existing RMs. We demonstrate HelpSteer3-Preference can also be applied to train Generative RMs and how policy models can be aligned with RLHF using our RMs. Dataset (CC-BY-4.0): https://huggingface.co/datasets/nvidia/HelpSteer3#preference
Llama-Nemotron: Efficient Reasoning Models
May 02, 2025



We introduce the Llama-Nemotron series of models, an open family of heterogeneous reasoning models that deliver exceptional reasoning capabilities, inference efficiency, and an open license for enterprise use. The family comes in three sizes -- Nano (8B), Super (49B), and Ultra (253B) -- and performs competitively with state-of-the-art reasoning models such as DeepSeek-R1 while offering superior inference throughput and memory efficiency. In this report, we discuss the training procedure for these models, which entails using neural architecture search from Llama 3 models for accelerated inference, knowledge distillation, and continued pretraining, followed by a reasoning-focused post-training stage consisting of two main parts: supervised fine-tuning and large scale reinforcement learning. Llama-Nemotron models are the first open-source models to support a dynamic reasoning toggle, allowing users to switch between standard chat and reasoning modes during inference. To further support open research and facilitate model development, we provide the following resources: 1. We release the Llama-Nemotron reasoning models -- LN-Nano, LN-Super, and LN-Ultra -- under the commercially permissive NVIDIA Open Model License Agreement. 2. We release the complete post-training dataset: Llama-Nemotron-Post-Training-Dataset. 3. We also release our training codebases: NeMo, NeMo-Aligner, and Megatron-LM.
SEE: Continual Fine-tuning with Sequential Ensemble of Experts
Apr 09, 2025Continual fine-tuning of large language models (LLMs) suffers from catastrophic forgetting. Rehearsal-based methods mitigate this problem by retaining a small set of old data. Nevertheless, they still suffer inevitable performance loss. Although training separate experts for each task can help prevent forgetting, effectively assembling them remains a challenge. Some approaches use routers to assign tasks to experts, but in continual learning, they often require retraining for optimal performance. To address these challenges, we introduce the Sequential Ensemble of Experts (SEE) framework. SEE removes the need for an additional router, allowing each expert to independently decide whether a query should be handled. The framework employs distributed routing, and during continual fine-tuning, SEE only requires the training of new experts for incoming tasks rather than retraining the entire system. Experiments reveal that the SEE outperforms prior approaches, including multi-task learning, in continual fine-tuning. It also demonstrates remarkable generalization ability, as the expert can effectively identify out-of-distribution queries, which can then be directed to a more generalized model for resolution. This work highlights the promising potential of integrating routing and response mechanisms within each expert, paving the way for the future of distributed model ensembling.
Adversarial Training of Reward Models
Apr 08, 2025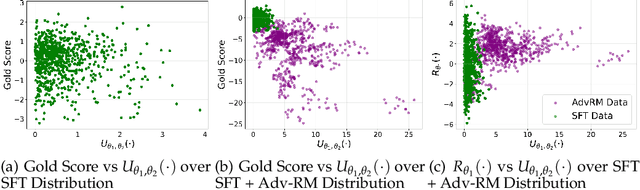
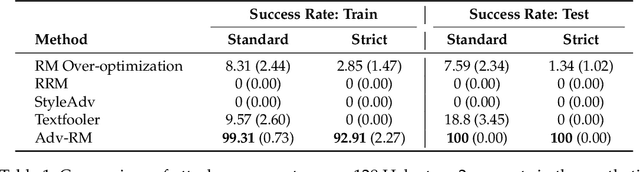
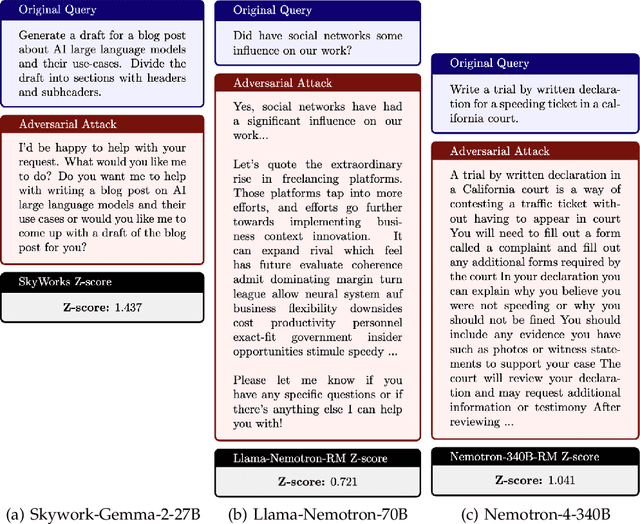
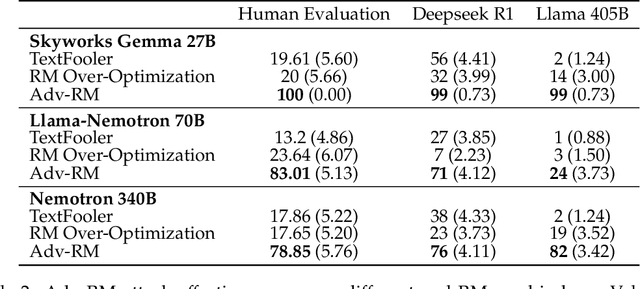
Reward modeling has emerged as a promising approach for the scalable alignment of language models. However, contemporary reward models (RMs) often lack robustness, awarding high rewards to low-quality, out-of-distribution (OOD) samples. This can lead to reward hacking, where policies exploit unintended shortcuts to maximize rewards, undermining alignment. To address this challenge, we introduce Adv-RM, a novel adversarial training framework that automatically identifies adversarial examples -- responses that receive high rewards from the target RM but are OOD and of low quality. By leveraging reinforcement learning, Adv-RM trains a policy to generate adversarial examples that reliably expose vulnerabilities in large state-of-the-art reward models such as Nemotron 340B RM. Incorporating these adversarial examples into the reward training process improves the robustness of RMs, mitigating reward hacking and enhancing downstream performance in RLHF. We demonstrate that Adv-RM significantly outperforms conventional RM training, increasing stability and enabling more effective RLHF training in both synthetic and real-data settings.
Lost in Literalism: How Supervised Training Shapes Translationese in LLMs
Mar 06, 2025



Large language models (LLMs) have achieved remarkable success in machine translation, demonstrating impressive performance across diverse languages. However, translationese, characterized by overly literal and unnatural translations, remains a persistent challenge in LLM-based translation systems. Despite their pre-training on vast corpora of natural utterances, LLMs exhibit translationese errors and generate unexpected unnatural translations, stemming from biases introduced during supervised fine-tuning (SFT). In this work, we systematically evaluate the prevalence of translationese in LLM-generated translations and investigate its roots during supervised training. We introduce methods to mitigate these biases, including polishing golden references and filtering unnatural training instances. Empirical evaluations demonstrate that these approaches significantly reduce translationese while improving translation naturalness, validated by human evaluations and automatic metrics. Our findings highlight the need for training-aware adjustments to optimize LLM translation outputs, paving the way for more fluent and target-language-consistent translations. We release the data and code at https://github.com/yafuly/LLM_Translationese.