 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDedicated Feedback and Edit Models Empower Inference-Time Scaling for Open-Ended General-Domain Tasks
Mar 06, 2025



Inference-Time Scaling has been critical to the success of recent models such as OpenAI o1 and DeepSeek R1. However, many techniques used to train models for inference-time scaling require tasks to have answers that can be verified, limiting their application to domains such as math, coding and logical reasoning. We take inspiration from how humans make first attempts, ask for detailed feedback from others and make improvements based on such feedback across a wide spectrum of open-ended endeavors. To this end, we collect data for and train dedicated Feedback and Edit Models that are capable of performing inference-time scaling for open-ended general-domain tasks. In our setup, one model generates an initial response, which are given feedback by a second model, that are then used by a third model to edit the response. We show that performance on Arena Hard, a benchmark strongly predictive of Chatbot Arena Elo can be boosted by scaling the number of initial response drafts, effective feedback and edited responses. When scaled optimally, our setup based on 70B models from the Llama 3 family can reach SoTA performance on Arena Hard at 92.7 as of 5 Mar 2025, surpassing OpenAI o1-preview-2024-09-12 with 90.4 and DeepSeek R1 with 92.3.
HelpSteer2-Preference: Complementing Ratings with Preferences
Oct 02, 2024Reward models are critical for aligning models to follow instructions, and are typically trained following one of two popular paradigms: Bradley-Terry style or Regression style. However, there is a lack of evidence that either approach is better than the other, when adequately matched for data. This is primarily because these approaches require data collected in different (but incompatible) formats, meaning that adequately matched data is not available in existing public datasets. To tackle this problem, we release preference annotations (designed for Bradley-Terry training) to complement existing ratings (designed for Regression style training) in the HelpSteer2 dataset. To improve data interpretability, preference annotations are accompanied with human-written justifications. Using this data, we conduct the first head-to-head comparison of Bradley-Terry and Regression models when adequately matched for data. Based on insights derived from such a comparison, we propose a novel approach to combine Bradley-Terry and Regression reward modeling. A Llama-3.1-70B-Instruct model tuned with this approach scores 94.1 on RewardBench, emerging top of more than 140 reward models as of 1 Oct 2024. We also demonstrate the effectiveness of this reward model at aligning models to follow instructions in RLHF. We open-source this dataset (CC-BY-4.0 license) at https://huggingface.co/datasets/nvidia/HelpSteer2 and openly release the trained Reward Model at https://huggingface.co/nvidia/Llama-3.1-Nemotron-70B-Reward
Nemotron-4 340B Technical Report
Jun 17, 2024



We release the Nemotron-4 340B model family, including Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward. Our models are open access under the NVIDIA Open Model License Agreement, a permissive model license that allows distribution, modification, and use of the models and its outputs. These models perform competitively to open access models on a wide range of evaluation benchmarks, and were sized to fit on a single DGX H100 with 8 GPUs when deployed in FP8 precision. We believe that the community can benefit from these models in various research studies and commercial applications, especially for generating synthetic data to train smaller language models. Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.
HelpSteer2: Open-source dataset for training top-performing reward models
Jun 12, 2024High-quality preference datasets are essential for training reward models that can effectively guide large language models (LLMs) in generating high-quality responses aligned with human preferences. As LLMs become stronger and better aligned, permissively licensed preference datasets, such as Open Assistant, HH-RLHF, and HelpSteer need to be updated to remain effective for reward modeling. Methods that distil preference data from proprietary LLMs such as GPT-4 have restrictions on commercial usage imposed by model providers. To improve upon both generated responses and attribute labeling quality, we release HelpSteer2, a permissively licensed preference dataset (CC-BY-4.0). Using a powerful internal base model trained on HelpSteer2, we are able to achieve the SOTA score (92.0%) on Reward-Bench's primary dataset, outperforming currently listed open and proprietary models, as of June 12th, 2024. Notably, HelpSteer2 consists of only ten thousand response pairs, an order of magnitude fewer than existing preference datasets (e.g., HH-RLHF), which makes it highly efficient for training reward models. Our extensive experiments demonstrate that reward models trained with HelpSteer2 are effective in aligning LLMs. In particular, we propose SteerLM 2.0, a model alignment approach that can effectively make use of the rich multi-attribute score predicted by our reward models. HelpSteer2 is available at https://huggingface.co/datasets/nvidia/HelpSteer2 and code is available at https://github.com/NVIDIA/NeMo-Aligner
NeMo-Aligner: Scalable Toolkit for Efficient Model Alignment
May 02, 2024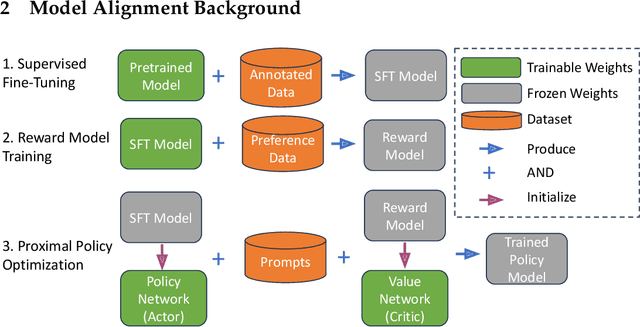
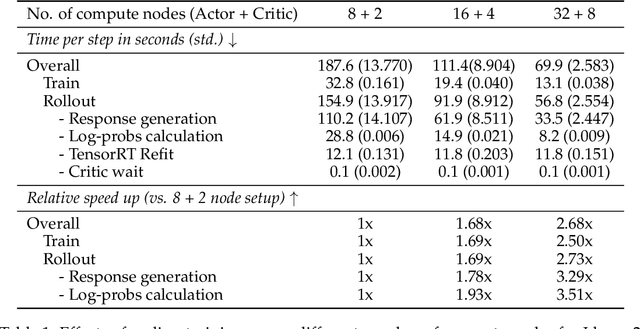

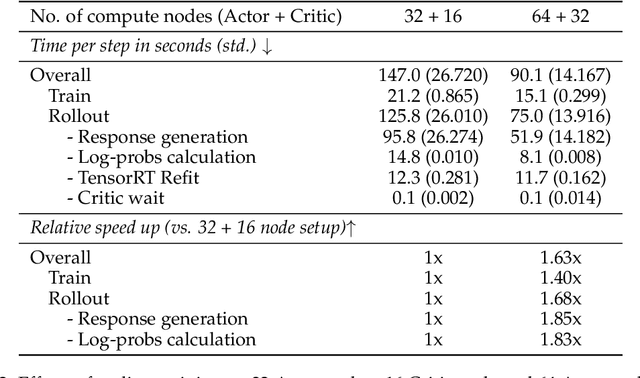
Aligning Large Language Models (LLMs) with human values and preferences is essential for making them helpful and safe. However, building efficient tools to perform alignment can be challenging, especially for the largest and most competent LLMs which often contain tens or hundreds of billions of parameters. We create NeMo-Aligner, a toolkit for model alignment that can efficiently scale to using hundreds of GPUs for training. NeMo-Aligner comes with highly optimized and scalable implementations for major paradigms of model alignment such as: Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO), SteerLM, and Self-Play Fine-Tuning (SPIN). Additionally, our toolkit supports running most of the alignment techniques in a Parameter Efficient Fine-Tuning (PEFT) setting. NeMo-Aligner is designed for extensibility, allowing support for other alignment techniques with minimal effort. It is open-sourced with Apache 2.0 License and we invite community contributions at https://github.com/NVIDIA/NeMo-Aligner
HelpSteer: Multi-attribute Helpfulness Dataset for SteerLM
Nov 16, 2023

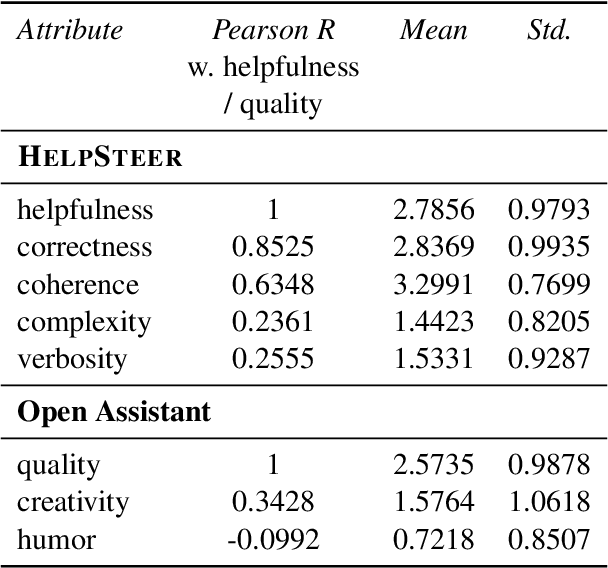
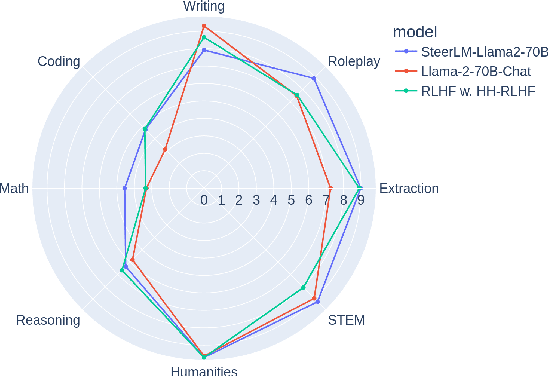
Existing open-source helpfulness preference datasets do not specify what makes some responses more helpful and others less so. Models trained on these datasets can incidentally learn to model dataset artifacts (e.g. preferring longer but unhelpful responses only due to their length). To alleviate this problem, we collect HelpSteer, a multi-attribute helpfulness dataset annotated for the various aspects that make responses helpful. Specifically, our 37k-sample dataset has annotations for correctness, coherence, complexity, and verbosity in addition to overall helpfulness of responses. Training Llama 2 70B using the HelpSteer dataset with SteerLM technique produces a model that scores 7.54 on MT Bench, which is currently the highest score for open models that do not require training data from more powerful models (e.g. GPT4). We release this dataset with CC-BY-4.0 license at https://huggingface.co/datasets/nvidia/HelpSteer