 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByteScience: Bridging Unstructured Scientific Literature and Structured Data with Auto Fine-tuned Large Language Model in Token Granularity
Nov 18, 2024



Natural Language Processing (NLP) is widely used to supply summarization ability from long context to structured information. However, extracting structured knowledge from scientific text by NLP models remains a challenge because of its domain-specific nature to complex data preprocessing and the granularity of multi-layered device-level information. To address this, we introduce ByteScience, a non-profit cloud-based auto fine-tuned Large Language Model (LLM) platform, which is designed to extract structured scientific data and synthesize new scientific knowledge from vast scientific corpora. The platform capitalizes on DARWIN, an open-source, fine-tuned LLM dedicated to natural science. The platform was built on Amazon Web Services (AWS) and provides an automated, user-friendly workflow for custom model development and data extraction. The platform achieves remarkable accuracy with only a small amount of well-annotated articles. This innovative tool streamlines the transition from the science literature to structured knowledge and data and benefits the advancements in natural informatics.
Construction of Functional Materials Knowledge Graph in Multidisciplinary Materials Science via Large Language Model
Apr 03, 2024



The convergence of materials science and artificial intelligence has unlocked new opportunities for gathering, analyzing, and generating novel materials sourced from extensive scientific literature. Despite the potential benefits, persistent challenges such as manual annotation, precise extraction, and traceability issues remain. Large language models have emerged as promising solutions to address these obstacles. This paper introduces Functional Materials Knowledge Graph (FMKG), a multidisciplinary materials science knowledge graph. Through the utilization of advanced natural language processing techniques, extracting millions of entities to form triples from a corpus comprising all high-quality research papers published in the last decade. It organizes unstructured information into nine distinct labels, covering Name, Formula, Acronym, Structure/Phase, Properties, Descriptor, Synthesis, Characterization Method, Application, and Domain, seamlessly integrating papers' Digital Object Identifiers. As the latest structured database for functional materials, FMKG acts as a powerful catalyst for expediting the development of functional materials and a fundation for building a more comprehensive material knowledge graph using full paper text. Furthermore, our research lays the groundwork for practical text-mining-based knowledge management systems, not only in intricate materials systems but also applicable to other specialized domains.
DARWIN Series: Domain Specific Large Language Models for Natural Science
Aug 25, 2023Emerging tools bring forth fresh approaches to work, and the field of natural science is no different. In natural science, traditional manual, serial, and labour-intensive work is being augmented by automated, parallel, and iterative processes driven by artificial intelligence-based experimental automation and more. To add new capabilities in natural science, enabling the acceleration and enrichment of automation of the discovery process, we present DARWIN, a series of tailored LLMs for natural science, mainly in physics, chemistry, and material science. This series relies on open-source LLM, incorporating structured and unstructured scientific knowledge from public datasets and literature. We fine-tuned the models using over 60,000 instruction data points, emphasizing factual correctness. During the fine-tuning, we introduce the Scientific Instruction Generation (SIG) model, automating instruction generation from scientific texts. This eliminates the need for manual extraction or domain-specific knowledge graphs and efficiently injects scientific knowledge into the model. We also explore multi-task training strategies, revealing interconnections between scientific tasks. DARWIN series not only achieves state-of-the-art results on various scientific tasks but also diminishes reliance on closed-source AI models. Our research showcases the ability of LLM in the scientific domain, with the overarching goal of fostering prosperity within the broader AI for science community.
Large Language Models as Master Key: Unlocking the Secrets of Materials Science with GPT
Apr 12, 2023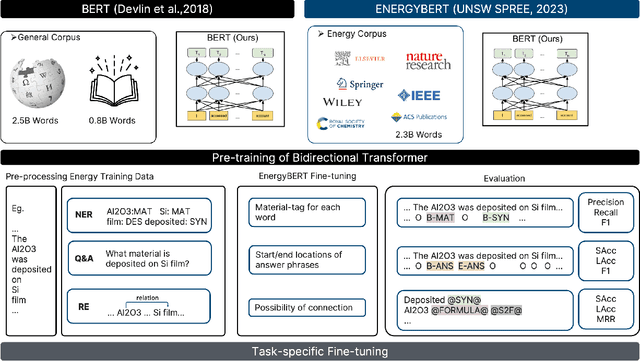

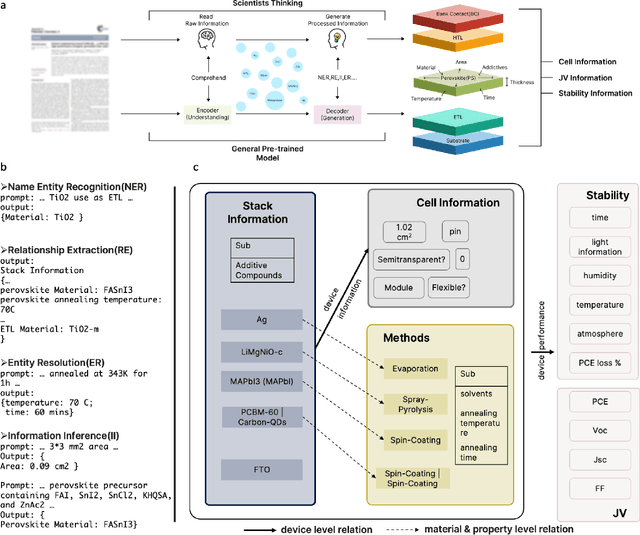

The amount of data has growing significance in exploring cutting-edge materials and a number of datasets have been generated either by hand or automated approaches. However, the materials science field struggles to effectively utilize the abundance of data, especially in applied disciplines where materials are evaluated based on device performance rather than their properties. This article presents a new natural language processing (NLP) task called structured information inference (SII) to address the complexities of information extraction at the device level in materials science. We accomplished this task by tuning GPT-3 on an existing perovskite solar cell FAIR (Findable, Accessible, Interoperable, Reusable) dataset with 91.8% F1-score and extended the dataset with data published since its release. The produced data is formatted and normalized, enabling its direct utilization as input in subsequent data analysis. This feature empowers materials scientists to develop models by selecting high-quality review articles within their domain. Additionally, we designed experiments to predict the electrical performance of solar cells and design materials or devices with targeted parameters using large language models (LLMs). Our results demonstrate comparable performance to traditional machine learning methods without feature selection, highlighting the potential of LLMs to acquire scientific knowledge and design new materials akin to materials scientists.
Interdisciplinary Discovery of Nanomaterials Based on Convolutional Neural Networks
Dec 06, 2022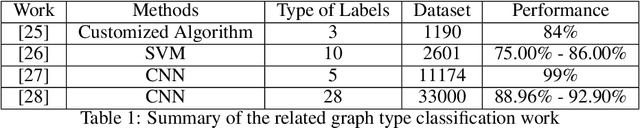
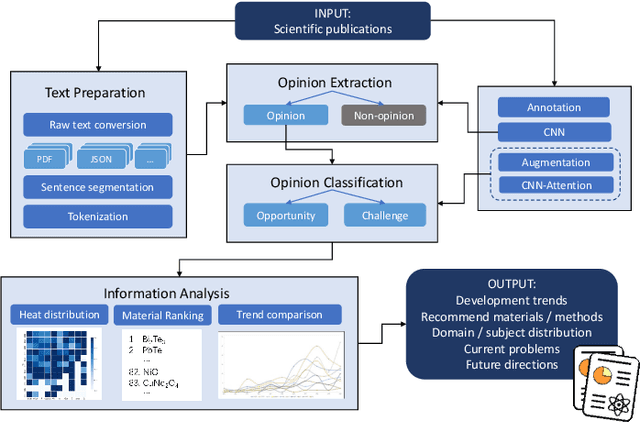
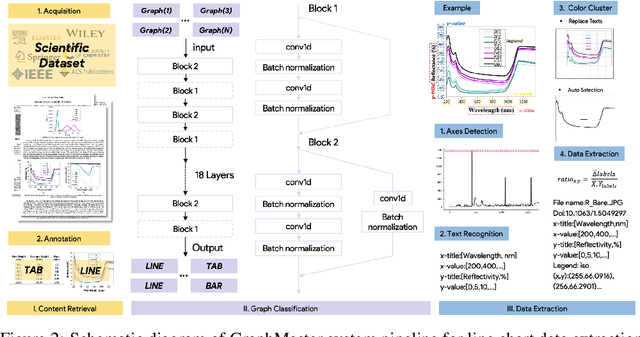
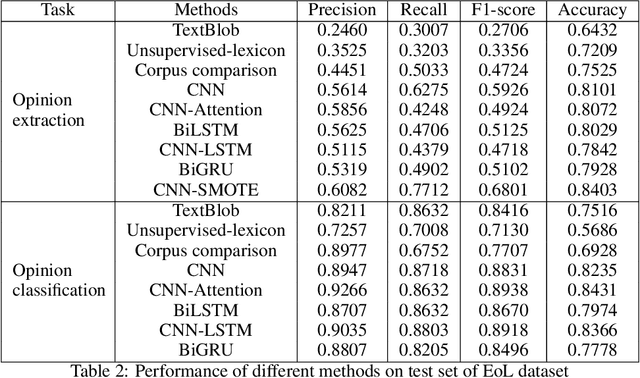
The material science literature contains up-to-date and comprehensive scientific knowledge of materials. However, their content is unstructured and diverse, resulting in a significant gap in providing sufficient information for material design and synthesis. To this end, we used natural language processing (NLP) and computer vision (CV) techniques based on convolutional neural networks (CNN) to discover valuable experimental-based information about nanomaterials and synthesis methods in energy-material-related publications. Our first system, TextMaster, extracts opinions from texts and classifies them into challenges and opportunities, achieving 94% and 92% accuracy, respectively. Our second system, GraphMaster, realizes data extraction of tables and figures from publications with 98.3\% classification accuracy and 4.3% data extraction mean square error. Our results show that these systems could assess the suitability of materials for a certain application by evaluation of synthesis insights and case analysis with detailed references. This work offers a fresh perspective on mining knowledge from scientific literature, providing a wide swatch to accelerate nanomaterial research through CNN.