 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHKJudge: A Legal Discourse-Annotated Corpus for Interpreting What Courts Find, How They Reason, and What They Rule
Jun 04, 2026Court judgments are central to legal practice and jurisprudence, yet discourse analysis of Hong Kong judgments has received limited attention, owing largely to the absence of expert-annotated corpora. We introduce the Hong Kong Judgment Discourse Dataset (HKJudge), the first sentence-level expert-annotated legal discourse corpus. HKJudge includes criminal judgments across all five levels of HK's court hierarchy, comprising $\sim$290k sentences and $\sim$6.5 million tokens, fully annotated by legal linguistics experts. We design a two-tier discourse schema that captures what facts a court finds, how it reasons, and what it rules. At the sentence level, each sentence is assigned one of 26 rhetorical roles. At the span level, sentences are further annotated with three sentencing elements (charge, imprisonment term, fine). Ten legal linguistics annotators produced the annotations with an inter-annotator agreement of $κ= 0.8$. We formulate two tasks on HKJudge, termed rhetorical role classification and legal element extraction, and provide the first benchmark evaluation of four BERT-based models, two open-source LLMs under zero-shot and fine-tuning settings, and four commercial LLMs on both tasks. Our work demonstrates the value of sentence-level discourse annotation for modeling the structure of HK judgments and provides a rich data foundation for future work on legal judgment prediction. The HKJudge dataset and code are available at https://github.com/xuanxixi/HKJudge.
Hierarchical Multi-Scale Graph Learning with Knowledge-Guided Attention for Whole-Slide Image Survival Analysis
Mar 02, 2026We propose a Hierarchical Multi-scale Knowledge-aware Graph Network (HMKGN) that models multi-scale interactions and spatially hierarchical relationships within whole-slide images (WSIs) for cancer prognostication. Unlike conventional attention-based MIL, which ignores spatial organization, or graph-based MIL, which relies on static handcrafted graphs, HMKGN enforces a hierarchical structure with spatial locality constraints, wherein local cellular-level dynamic graphs aggregate spatially proximate patches within each region of interest (ROI) and a global slide-level dynamic graph integrates ROI-level features into WSI-level representations. Moreover, multi-scale integration at the ROI level combines coarse contextual features from broader views with fine-grained structural representations from local patch-graph aggregation. We evaluate HMKGN on four TCGA cohorts (KIRC, LGG, PAAD, and STAD; N=513, 487, 138, and 370) for survival prediction. It consistently outperforms existing MIL-based models, yielding improved concordance indices (10.85% better) and statistically significant stratification of patient survival risk (log-rank p < 0.05).
TransLaw: Benchmarking Large Language Models in Multi-Agent Simulation of the Collaborative Translation
Jul 01, 2025Multi-agent systems empowered by large language models (LLMs) have demonstrated remarkable capabilities in a wide range of downstream applications, including machine translation. However, the potential of LLMs in translating Hong Kong legal judgments remains uncertain due to challenges such as intricate legal terminology, culturally embedded nuances, and strict linguistic structures. In this work, we introduce TransLaw, a novel multi-agent framework implemented for real-world Hong Kong case law translation. It employs three specialized agents, namely, Translator, Annotator, and Proofreader, to collaboratively produce translations for high accuracy in legal meaning, appropriateness in style, and adequate coherence and cohesion in structure. This framework supports customizable LLM configurations and achieves tremendous cost reduction compared to professional human translation services. We evaluated its performance using 13 open-source and commercial LLMs as agents and obtained interesting findings, including that it surpasses GPT-4o in legal semantic accuracy, structural coherence, and stylistic fidelity, yet trails human experts in contextualizing complex terminology and stylistic naturalness. Our platform website is available at CityUHK, and our bilingual judgment corpus used for the evaluation is available at Hugging Face.
Efficient Privacy-Preserving KAN Inference Using Homomorphic Encryption
Sep 12, 2024



The recently proposed Kolmogorov-Arnold Networks (KANs) offer enhanced interpretability and greater model expressiveness. However, KANs also present challenges related to privacy leakage during inference. Homomorphic encryption (HE) facilitates privacy-preserving inference for deep learning models, enabling resource-limited users to benefit from deep learning services while ensuring data security. Yet, the complex structure of KANs, incorporating nonlinear elements like the SiLU activation function and B-spline functions, renders existing privacy-preserving inference techniques inadequate. To address this issue, we propose an accurate and efficient privacy-preserving inference scheme tailored for KANs. Our approach introduces a task-specific polynomial approximation for the SiLU activation function, dynamically adjusting the approximation range to ensure high accuracy on real-world datasets. Additionally, we develop an efficient method for computing B-spline functions within the HE domain, leveraging techniques such as repeat packing, lazy combination, and comparison functions. We evaluate the effectiveness of our privacy-preserving KAN inference scheme on both symbolic formula evaluation and image classification. The experimental results show that our model achieves accuracy comparable to plaintext KANs across various datasets and outperforms plaintext MLPs. Additionally, on the CIFAR-10 dataset, our inference latency achieves over 7 times speedup compared to the naive method.
DS-ViT: Dual-Stream Vision Transformer for Cross-Task Distillation in Alzheimer's Early Diagnosis
Sep 11, 2024



In the field of Alzheimer's disease diagnosis, segmentation and classification tasks are inherently interconnected. Sharing knowledge between models for these tasks can significantly improve training efficiency, particularly when training data is scarce. However, traditional knowledge distillation techniques often struggle to bridge the gap between segmentation and classification due to the distinct nature of tasks and different model architectures. To address this challenge, we propose a dual-stream pipeline that facilitates cross-task and cross-architecture knowledge sharing. Our approach introduces a dual-stream embedding module that unifies feature representations from segmentation and classification models, enabling dimensional integration of these features to guide the classification model. We validated our method on multiple 3D datasets for Alzheimer's disease diagnosis, demonstrating significant improvements in classification performance, especially on small datasets. Furthermore, we extended our pipeline with a residual temporal attention mechanism for early diagnosis, utilizing images taken before the atrophy of patients' brain mass. This advancement shows promise in enabling diagnosis approximately six months earlier in mild and asymptomatic stages, offering critical time for intervention.
DISC: Latent Diffusion Models with Self-Distillation from Separated Conditions for Prostate Cancer Grading
Apr 19, 2024Latent Diffusion Models (LDMs) can generate high-fidelity images from noise, offering a promising approach for augmenting histopathology images for training cancer grading models. While previous works successfully generated high-fidelity histopathology images using LDMs, the generation of image tiles to improve prostate cancer grading has not yet been explored. Additionally, LDMs face challenges in accurately generating admixtures of multiple cancer grades in a tile when conditioned by a tile mask. In this study, we train specific LDMs to generate synthetic tiles that contain multiple Gleason Grades (GGs) by leveraging pixel-wise annotations in input tiles. We introduce a novel framework named Self-Distillation from Separated Conditions (DISC) that generates GG patterns guided by GG masks. Finally, we deploy a training framework for pixel-level and slide-level prostate cancer grading, where synthetic tiles are effectively utilized to improve the cancer grading performance of existing models. As a result, this work surpasses previous works in two domains: 1) our LDMs enhanced with DISC produce more accurate tiles in terms of GG patterns, and 2) our training scheme, incorporating synthetic data, significantly improves the generalization of the baseline model for prostate cancer grading, particularly in challenging cases of rare GG5, demonstrating the potential of generative models to enhance cancer grading when data is limited.
Peer-aided Repairer: Empowering Large Language Models to Repair Advanced Student Assignments
Apr 02, 2024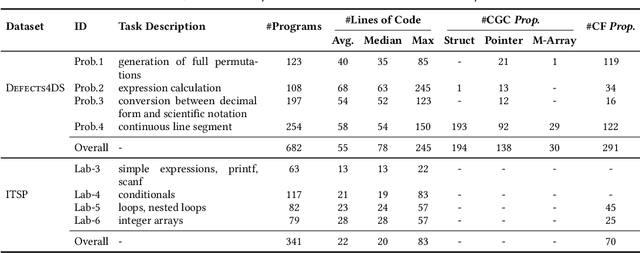
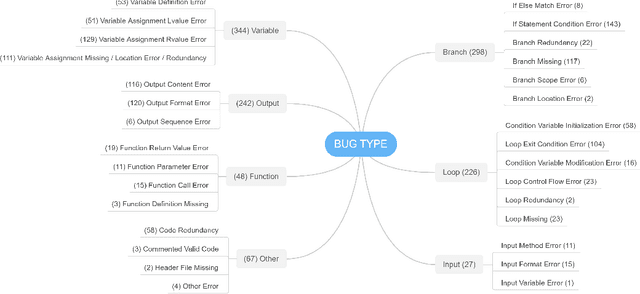
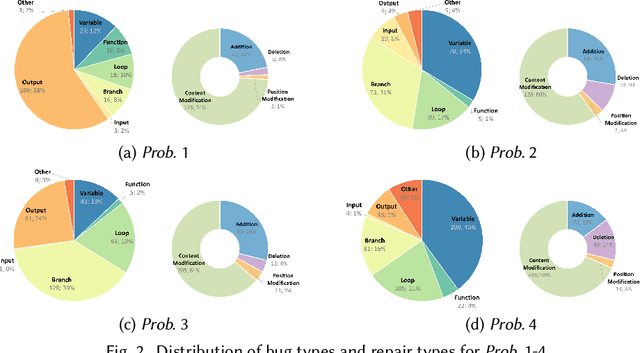
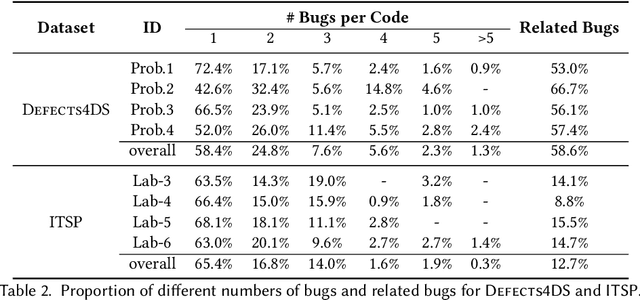
Automated generation of feedback on programming assignments holds significant benefits for programming education, especially when it comes to advanced assignments. Automated Program Repair techniques, especially Large Language Model based approaches, have gained notable recognition for their potential to fix introductory assignments. However, the programs used for evaluation are relatively simple. It remains unclear how existing approaches perform in repairing programs from higher-level programming courses. To address these limitations, we curate a new advanced student assignment dataset named Defects4DS from a higher-level programming course. Subsequently, we identify the challenges related to fixing bugs in advanced assignments. Based on the analysis, we develop a framework called PaR that is powered by the LLM. PaR works in three phases: Peer Solution Selection, Multi-Source Prompt Generation, and Program Repair. Peer Solution Selection identifies the closely related peer programs based on lexical, semantic, and syntactic criteria. Then Multi-Source Prompt Generation adeptly combines multiple sources of information to create a comprehensive and informative prompt for the last Program Repair stage. The evaluation on Defects4DS and another well-investigated ITSP dataset reveals that PaR achieves a new state-of-the-art performance, demonstrating impressive improvements of 19.94% and 15.2% in repair rate compared to prior state-of-the-art LLM- and symbolic-based approaches, respectively
Large Language Models as Master Key: Unlocking the Secrets of Materials Science with GPT
Apr 12, 2023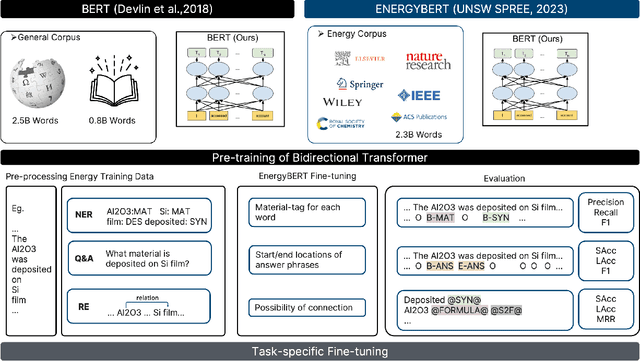

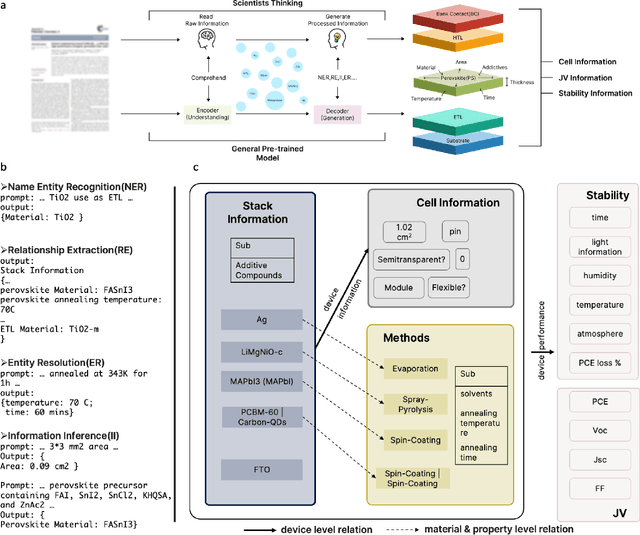

The amount of data has growing significance in exploring cutting-edge materials and a number of datasets have been generated either by hand or automated approaches. However, the materials science field struggles to effectively utilize the abundance of data, especially in applied disciplines where materials are evaluated based on device performance rather than their properties. This article presents a new natural language processing (NLP) task called structured information inference (SII) to address the complexities of information extraction at the device level in materials science. We accomplished this task by tuning GPT-3 on an existing perovskite solar cell FAIR (Findable, Accessible, Interoperable, Reusable) dataset with 91.8% F1-score and extended the dataset with data published since its release. The produced data is formatted and normalized, enabling its direct utilization as input in subsequent data analysis. This feature empowers materials scientists to develop models by selecting high-quality review articles within their domain. Additionally, we designed experiments to predict the electrical performance of solar cells and design materials or devices with targeted parameters using large language models (LLMs). Our results demonstrate comparable performance to traditional machine learning methods without feature selection, highlighting the potential of LLMs to acquire scientific knowledge and design new materials akin to materials scientists.