 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF2FLDM: Latent Diffusion Models with Histopathology Pre-Trained Embeddings for Unpaired Frozen Section to FFPE Translation
Apr 19, 2024



The Frozen Section (FS) technique is a rapid and efficient method, taking only 15-30 minutes to prepare slides for pathologists' evaluation during surgery, enabling immediate decisions on further surgical interventions. However, FS process often introduces artifacts and distortions like folds and ice-crystal effects. In contrast, these artifacts and distortions are absent in the higher-quality formalin-fixed paraffin-embedded (FFPE) slides, which require 2-3 days to prepare. While Generative Adversarial Network (GAN)-based methods have been used to translate FS to FFPE images (F2F), they may leave morphological inaccuracies with remaining FS artifacts or introduce new artifacts, reducing the quality of these translations for clinical assessments. In this study, we benchmark recent generative models, focusing on GANs and Latent Diffusion Models (LDMs), to overcome these limitations. We introduce a novel approach that combines LDMs with Histopathology Pre-Trained Embeddings to enhance restoration of FS images. Our framework leverages LDMs conditioned by both text and pre-trained embeddings to learn meaningful features of FS and FFPE histopathology images. Through diffusion and denoising techniques, our approach not only preserves essential diagnostic attributes like color staining and tissue morphology but also proposes an embedding translation mechanism to better predict the targeted FFPE representation of input FS images. As a result, this work achieves a significant improvement in classification performance, with the Area Under the Curve rising from 81.99% to 94.64%, accompanied by an advantageous CaseFD. This work establishes a new benchmark for FS to FFPE image translation quality, promising enhanced reliability and accuracy in histopathology FS image analysis. Our work is available at https://minhmanho.github.io/f2f_ldm/.
DISC: Latent Diffusion Models with Self-Distillation from Separated Conditions for Prostate Cancer Grading
Apr 19, 2024Latent Diffusion Models (LDMs) can generate high-fidelity images from noise, offering a promising approach for augmenting histopathology images for training cancer grading models. While previous works successfully generated high-fidelity histopathology images using LDMs, the generation of image tiles to improve prostate cancer grading has not yet been explored. Additionally, LDMs face challenges in accurately generating admixtures of multiple cancer grades in a tile when conditioned by a tile mask. In this study, we train specific LDMs to generate synthetic tiles that contain multiple Gleason Grades (GGs) by leveraging pixel-wise annotations in input tiles. We introduce a novel framework named Self-Distillation from Separated Conditions (DISC) that generates GG patterns guided by GG masks. Finally, we deploy a training framework for pixel-level and slide-level prostate cancer grading, where synthetic tiles are effectively utilized to improve the cancer grading performance of existing models. As a result, this work surpasses previous works in two domains: 1) our LDMs enhanced with DISC produce more accurate tiles in terms of GG patterns, and 2) our training scheme, incorporating synthetic data, significantly improves the generalization of the baseline model for prostate cancer grading, particularly in challenging cases of rare GG5, demonstrating the potential of generative models to enhance cancer grading when data is limited.
Interactive Image Manipulation with Complex Text Instructions
Nov 25, 2022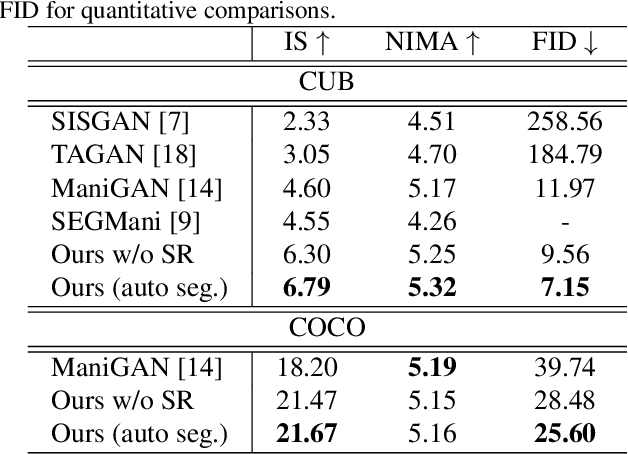
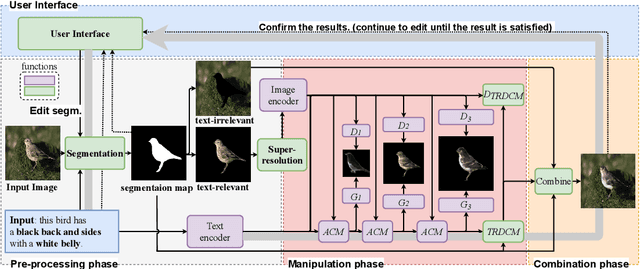
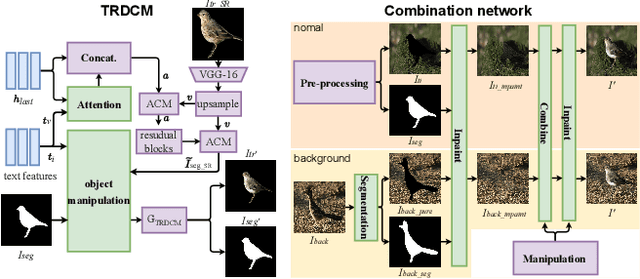

Recently, text-guided image manipulation has received increasing attention in the research field of multimedia processing and computer vision due to its high flexibility and controllability. Its goal is to semantically manipulate parts of an input reference image according to the text descriptions. However, most of the existing works have the following problems: (1) text-irrelevant content cannot always be maintained but randomly changed, (2) the performance of image manipulation still needs to be further improved, (3) only can manipulate descriptive attributes. To solve these problems, we propose a novel image manipulation method that interactively edits an image using complex text instructions. It allows users to not only improve the accuracy of image manipulation but also achieve complex tasks such as enlarging, dwindling, or removing objects and replacing the background with the input image. To make these tasks possible, we apply three strategies. First, the given image is divided into text-relevant content and text-irrelevant content. Only the text-relevant content is manipulated and the text-irrelevant content can be maintained. Second, a super-resolution method is used to enlarge the manipulation region to further improve the operability and to help manipulate the object itself. Third, a user interface is introduced for editing the segmentation map interactively to re-modify the generated image according to the user's desires. Extensive experiments on the Caltech-UCSD Birds-200-2011 (CUB) dataset and Microsoft Common Objects in Context (MS COCO) datasets demonstrate our proposed method can enable interactive, flexible, and accurate image manipulation in real-time. Through qualitative and quantitative evaluations, we show that the proposed model outperforms other state-of-the-art methods.
Deep Photo Scan: Semi-supervised learning for dealing with the real-world degradation in smartphone photo scanning
Feb 11, 2021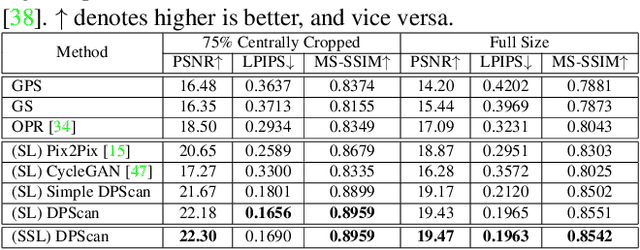
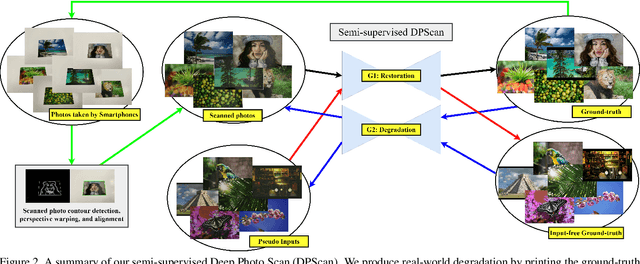
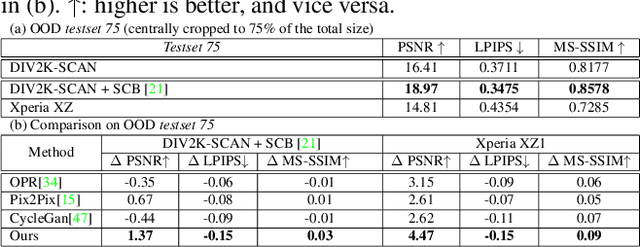

Physical photographs now can be conveniently scanned by smartphones and stored forever as a digital version, but the scanned photos are not restored well. One solution is to train a supervised deep neural network on many digital photos and the corresponding scanned photos. However, human annotation costs a huge resource leading to limited training data. Previous works create training pairs by simulating degradation using image processing techniques. Their synthetic images are formed with perfectly scanned photos in latent space. Even so, the real-world degradation in smartphone photo scanning remains unsolved since it is more complicated due to real lens defocus, lighting conditions, losing details via printing, various photo materials, and more. To solve these problems, we propose a Deep Photo Scan (DPScan) based on semi-supervised learning. First, we present the way to produce real-world degradation and provide the DIV2K-SCAN dataset for smartphone-scanned photo restoration. Second, by using DIV2K-SCAN, we adopt the concept of Generative Adversarial Networks to learn how to degrade a high-quality image as if it were scanned by a real smartphone, then generate pseudo-scanned photos for unscanned photos. Finally, we propose to train on the scanned and pseudo-scanned photos representing a semi-supervised approach with a cycle process as: high-quality images --> real-/pseudo-scanned photos --> reconstructed images. The proposed semi-supervised scheme can balance between supervised and unsupervised errors while optimizing to limit imperfect pseudo inputs but still enhance restoration. As a result, the proposed DPScan quantitatively and qualitatively outperforms its baseline architecture, state-of-the-art academic research, and industrial products in smartphone photo scanning.
Deep Preset: Blending and Retouching Photos with Color Style Transfer
Jul 21, 2020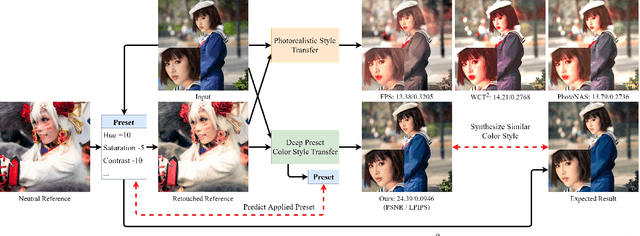
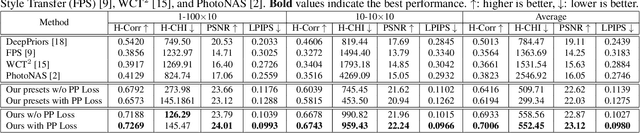

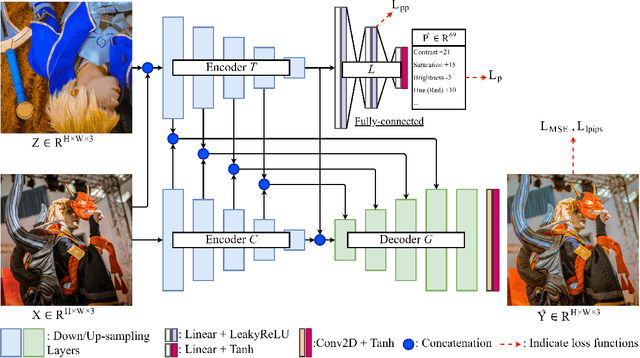
End-users, without knowledge in photography, desire to beautify their photos to have a similar color style as a well-retouched reference. However, recent works in image style transfer are overused. They usually synthesize undesirable results due to transferring exact colors to the wrong destination. It becomes even worse in sensitive cases such as portraits. In this work, we concentrate on learning low-level image transformation, especially color-shifting methods, rather than mixing contextual features, then present a novel scheme to train color style transfer with ground-truth. Furthermore, we propose a color style transfer named Deep Preset. It is designed to 1) generalize the features representing the color transformation from content with natural colors to retouched reference, then blend it into the contextual features of content, 2) predict hyper-parameters (settings or preset) of the applied low-level color transformation methods, 3) stylize content to have a similar color style as reference. We script Lightroom, a powerful tool in editing photos, to generate 600,000 training samples using 1,200 images from the Flick2K dataset and 500 user-generated presets with 69 settings. Experimental results show that our Deep Preset outperforms the previous works in color style transfer quantitatively and qualitatively.
Semantic-driven Colorization
Jun 18, 2020
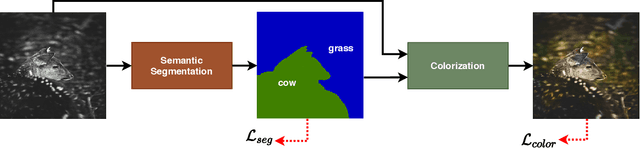


Recent deep colorization works predict the semantic information implicitly while learning to colorize black-and-white photographic images. As a consequence, the generated color is easier to be overflowed, and the semantic faults are invisible. As human experience in coloring, the human first recognize which objects and their location in the photo, imagine which color is plausible for the objects as in real life, then colorize it. In this study, we simulate that human-like action to firstly let our network learn to segment what is in the photo, then colorize it. Therefore, our network can choose a plausible color under semantic constraint for specific objects, and give discriminative colors between them. Moreover, the segmentation map becomes understandable and interactable for the user. Our models are trained on PASCAL-Context and evaluated on selected images from the public domain and COCO-Stuff, which has several unseen categories compared to training data. As seen from the experimental results, our colorization system can provide plausible colors for specific objects and generate harmonious colors competitive with state-of-the-art methods.