 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast, Unsupervised Framework for Registration Quality Assessment of Multi-stain Histological Whole Slide Pairs
Feb 03, 2026High-fidelity registration of histopathological whole slide images (WSIs), such as hematoxylin & eosin (H&E) and immunohistochemistry (IHC), is vital for integrated molecular analysis but challenging to evaluate without ground-truth (GT) annotations. Existing WSI-level assessments -- using annotated landmarks or intensity-based similarity metrics -- are often time-consuming, unreliable, and computationally intensive, limiting large-scale applicability. This study proposes a fast, unsupervised framework that jointly employs down-sampled tissue masks- and deformations-based metrics for registration quality assessment (RQA) of registered H&E and IHC WSI pairs. The masks-based metrics measure global structural correspondence, while the deformations-based metrics evaluate local smoothness, continuity, and transformation realism. Validation across multiple IHC markers and multi-expert assessments demonstrate a strong correlation between automated metrics and human evaluations. In the absence of GT, this framework offers reliable, real-time RQA with high fidelity and minimal computational resources, making it suitable for large-scale quality control in digital pathology.
Building Trust in Virtual Immunohistochemistry: Automated Assessment of Image Quality
Nov 06, 2025
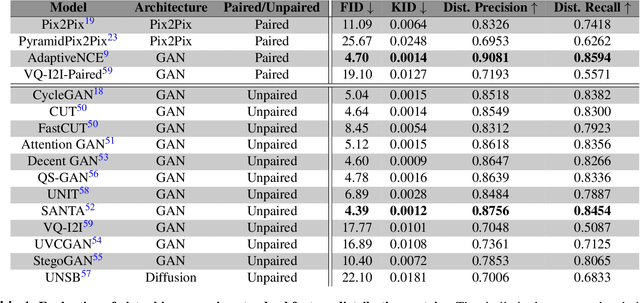
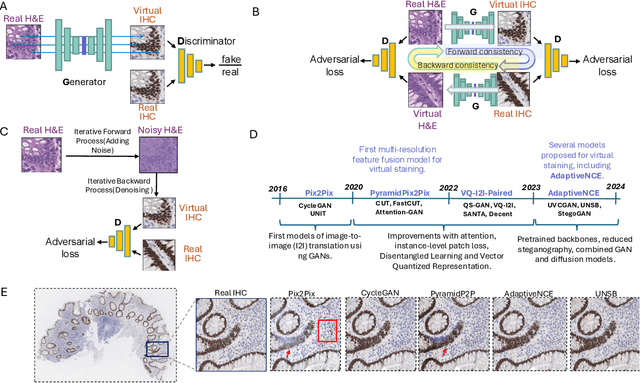

Deep learning models can generate virtual immunohistochemistry (IHC) stains from hematoxylin and eosin (H&E) images, offering a scalable and low-cost alternative to laboratory IHC. However, reliable evaluation of image quality remains a challenge as current texture- and distribution-based metrics quantify image fidelity rather than the accuracy of IHC staining. Here, we introduce an automated and accuracy grounded framework to determine image quality across sixteen paired or unpaired image translation models. Using color deconvolution, we generate masks of pixels stained brown (i.e., IHC-positive) as predicted by each virtual IHC model. We use the segmented masks of real and virtual IHC to compute stain accuracy metrics (Dice, IoU, Hausdorff distance) that directly quantify correct pixel - level labeling without needing expert manual annotations. Our results demonstrate that conventional image fidelity metrics, including Frechet Inception Distance (FID), peak signal-to-noise ratio (PSNR), and structural similarity (SSIM), correlate poorly with stain accuracy and pathologist assessment. Paired models such as PyramidPix2Pix and AdaptiveNCE achieve the highest stain accuracy, whereas unpaired diffusion- and GAN-based models are less reliable in providing accurate IHC positive pixel labels. Moreover, whole-slide images (WSI) reveal performance declines that are invisible in patch-based evaluations, emphasizing the need for WSI-level benchmarks. Together, this framework defines a reproducible approach for assessing the quality of virtual IHC models, a critical step to accelerate translation towards routine use by pathologists.
VIMs: Virtual Immunohistochemistry Multiplex staining via Text-to-Stain Diffusion Trained on Uniplex Stains
Jul 26, 2024
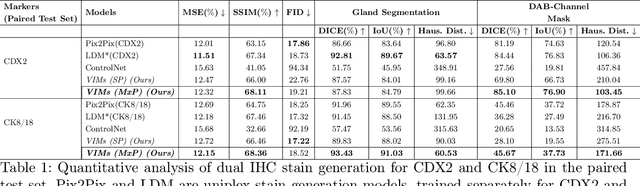

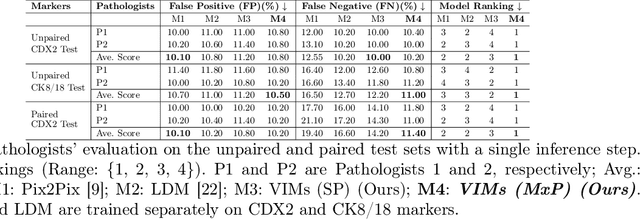
This paper introduces a Virtual Immunohistochemistry Multiplex staining (VIMs) model designed to generate multiple immunohistochemistry (IHC) stains from a single hematoxylin and eosin (H&E) stained tissue section. IHC stains are crucial in pathology practice for resolving complex diagnostic questions and guiding patient treatment decisions. While commercial laboratories offer a wide array of up to 400 different antibody-based IHC stains, small biopsies often lack sufficient tissue for multiple stains while preserving material for subsequent molecular testing. This highlights the need for virtual IHC staining. Notably, VIMs is the first model to address this need, leveraging a large vision-language single-step diffusion model for virtual IHC multiplexing through text prompts for each IHC marker. VIMs is trained on uniplex paired H&E and IHC images, employing an adversarial training module. Testing of VIMs includes both paired and unpaired image sets. To enhance computational efficiency, VIMs utilizes a pre-trained large latent diffusion model fine-tuned with small, trainable weights through the Low-Rank Adapter (LoRA) approach. Experiments on nuclear and cytoplasmic IHC markers demonstrate that VIMs outperforms the base diffusion model and achieves performance comparable to Pix2Pix, a standard generative model for paired image translation. Multiple evaluation methods, including assessments by two pathologists, are used to determine the performance of VIMs. Additionally, experiments with different prompts highlight the impact of text conditioning. This paper represents the first attempt to accelerate histopathology research by demonstrating the generation of multiple IHC stains from a single H&E input using a single model trained solely on uniplex data.
F2FLDM: Latent Diffusion Models with Histopathology Pre-Trained Embeddings for Unpaired Frozen Section to FFPE Translation
Apr 19, 2024



The Frozen Section (FS) technique is a rapid and efficient method, taking only 15-30 minutes to prepare slides for pathologists' evaluation during surgery, enabling immediate decisions on further surgical interventions. However, FS process often introduces artifacts and distortions like folds and ice-crystal effects. In contrast, these artifacts and distortions are absent in the higher-quality formalin-fixed paraffin-embedded (FFPE) slides, which require 2-3 days to prepare. While Generative Adversarial Network (GAN)-based methods have been used to translate FS to FFPE images (F2F), they may leave morphological inaccuracies with remaining FS artifacts or introduce new artifacts, reducing the quality of these translations for clinical assessments. In this study, we benchmark recent generative models, focusing on GANs and Latent Diffusion Models (LDMs), to overcome these limitations. We introduce a novel approach that combines LDMs with Histopathology Pre-Trained Embeddings to enhance restoration of FS images. Our framework leverages LDMs conditioned by both text and pre-trained embeddings to learn meaningful features of FS and FFPE histopathology images. Through diffusion and denoising techniques, our approach not only preserves essential diagnostic attributes like color staining and tissue morphology but also proposes an embedding translation mechanism to better predict the targeted FFPE representation of input FS images. As a result, this work achieves a significant improvement in classification performance, with the Area Under the Curve rising from 81.99% to 94.64%, accompanied by an advantageous CaseFD. This work establishes a new benchmark for FS to FFPE image translation quality, promising enhanced reliability and accuracy in histopathology FS image analysis. Our work is available at https://minhmanho.github.io/f2f_ldm/.
Structural Cycle GAN for Virtual Immunohistochemistry Staining of Gland Markers in the Colon
Aug 25, 2023



With the advent of digital scanners and deep learning, diagnostic operations may move from a microscope to a desktop. Hematoxylin and Eosin (H&E) staining is one of the most frequently used stains for disease analysis, diagnosis, and grading, but pathologists do need different immunohistochemical (IHC) stains to analyze specific structures or cells. Obtaining all of these stains (H&E and different IHCs) on a single specimen is a tedious and time-consuming task. Consequently, virtual staining has emerged as an essential research direction. Here, we propose a novel generative model, Structural Cycle-GAN (SC-GAN), for synthesizing IHC stains from H&E images, and vice versa. Our method expressly incorporates structural information in the form of edges (in addition to color data) and employs attention modules exclusively in the decoder of the proposed generator model. This integration enhances feature localization and preserves contextual information during the generation process. In addition, a structural loss is incorporated to ensure accurate structure alignment between the generated and input markers. To demonstrate the efficacy of the proposed model, experiments are conducted with two IHC markers emphasizing distinct structures of glands in the colon: the nucleus of epithelial cells (CDX2) and the cytoplasm (CK818). Quantitative metrics such as FID and SSIM are frequently used for the analysis of generative models, but they do not correlate explicitly with higher-quality virtual staining results. Therefore, we propose two new quantitative metrics that correlate directly with the virtual staining specificity of IHC markers.
3D Convolutional with Attention for Action Recognition
Jun 05, 2022Human action recognition is one of the challenging tasks in computer vision. The current action recognition methods use computationally expensive models for learning spatio-temporal dependencies of the action. Models utilizing RGB channels and optical flow separately, models using a two-stream fusion technique, and models consisting of both convolutional neural network (CNN) and long-short term memory (LSTM) network are few examples of such complex models. Moreover, fine-tuning such complex models is computationally expensive as well. This paper proposes a deep neural network architecture for learning such dependencies consisting of a 3D convolutional layer, fully connected (FC) layers, and attention layer, which is simpler to implement and gives a competitive performance on the UCF-101 dataset. The proposed method first learns spatial and temporal features of actions through 3D-CNN, and then the attention mechanism helps the model to locate attention to essential features for recognition.
Label-Attention Transformer with Geometrically Coherent Objects for Image Captioning
Sep 16, 2021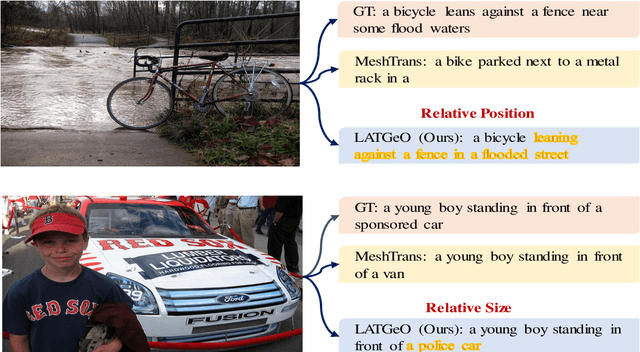

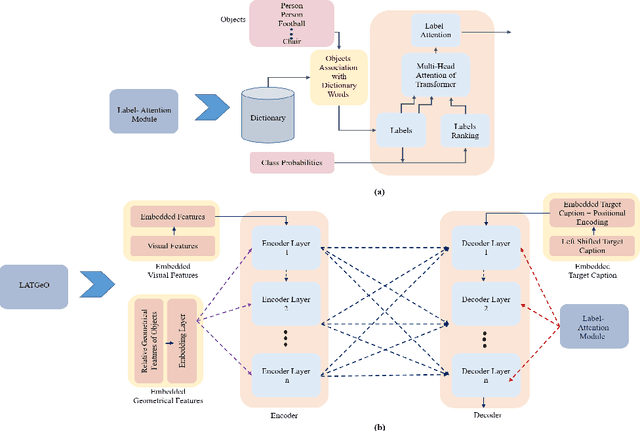
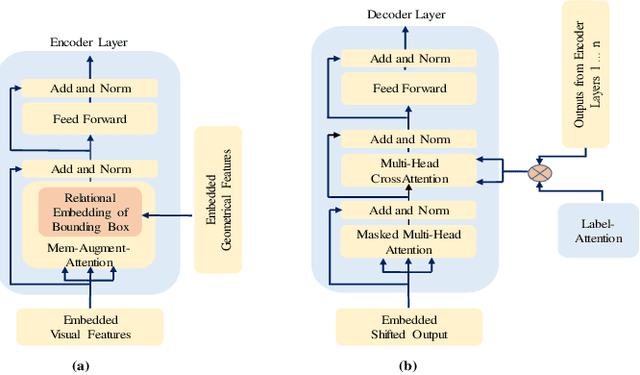
Automatic transcription of scene understanding in images and videos is a step towards artificial general intelligence. Image captioning is a nomenclature for describing meaningful information in an image using computer vision techniques. Automated image captioning techniques utilize encoder and decoder architecture, where the encoder extracts features from an image and the decoder generates a transcript. In this work, we investigate two unexplored ideas for image captioning using transformers: First, we demonstrate the enforcement of using objects' relevance in the surrounding environment. Second, learning an explicit association between labels and language constructs. We propose label-attention Transformer with geometrically coherent objects (LATGeO). The proposed technique acquires a proposal of geometrically coherent objects using a deep neural network (DNN) and generates captions by investigating their relationships using a label-attention module. Object coherence is defined using the localized ratio of the geometrical properties of the proposals. The label-attention module associates the extracted objects classes to the available dictionary using self-attention layers. The experimentation results show that objects' relevance in surroundings and binding of their visual feature with their geometrically localized ratios combined with its associated labels help in defining meaningful captions. The proposed framework is tested on the MSCOCO dataset, and a thorough evaluation resulting in overall better quantitative scores pronounces its superiority.
Image Captioning using Multiple Transformers for Self-Attention Mechanism
Feb 14, 2021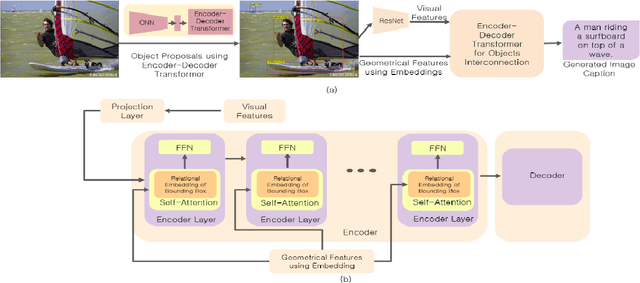

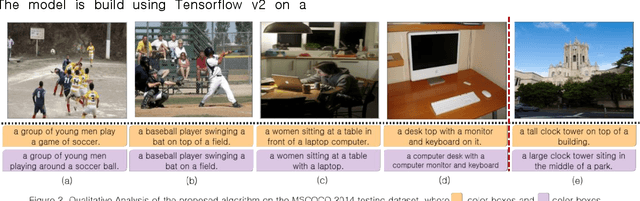

Real-time image captioning, along with adequate precision, is the main challenge of this research field. The present work, Multiple Transformers for Self-Attention Mechanism (MTSM), utilizes multiple transformers to address these problems. The proposed algorithm, MTSM, acquires region proposals using a transformer detector (DETR). Consequently, MTSM achieves the self-attention mechanism by transferring these region proposals and their visual and geometrical features through another transformer and learns the objects' local and global interconnections. The qualitative and quantitative results of the proposed algorithm, MTSM, are shown on the MSCOCO dataset.
3D ResNet with Ranking Loss Function for Abnormal Activity Detection in Videos
Feb 04, 2020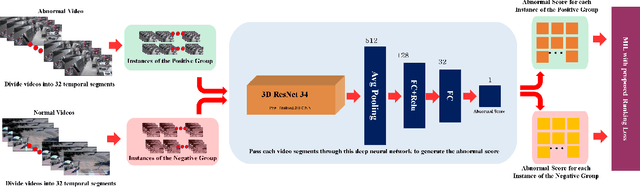
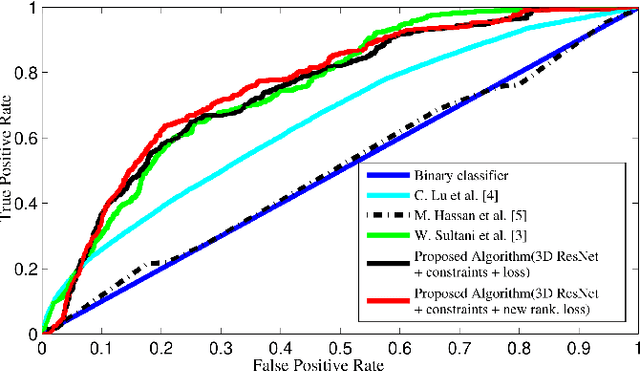
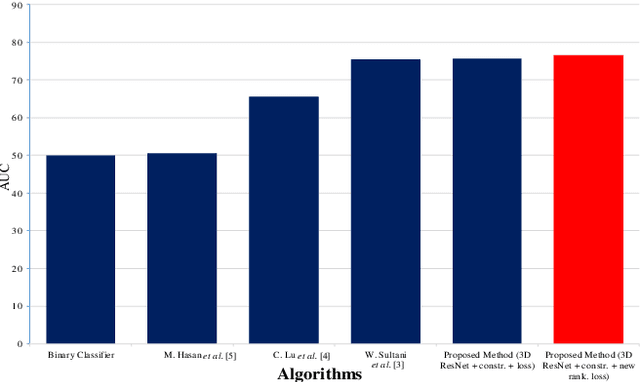
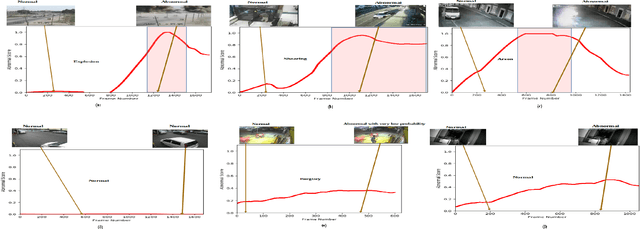
Abnormal activity detection is one of the most challenging tasks in the field of computer vision. This study is motivated by the recent state-of-art work of abnormal activity detection, which utilizes both abnormal and normal videos in learning abnormalities with the help of multiple instance learning by providing the data with video-level information. In the absence of temporal-annotations, such a model is prone to give a false alarm while detecting the abnormalities. For this reason, in this paper, we focus on the task of minimizing the false alarm rate while performing an abnormal activity detection task. The mitigation of these false alarms and recent advancement of 3D deep neural network in video action recognition task collectively give us motivation to exploit the 3D ResNet in our proposed method, which helps to extract spatial-temporal features from the videos. Afterwards, using these features and deep multiple instance learning along with the proposed ranking loss, our model learns to predict the abnormality score at the video segment level. Therefore, our proposed method 3D deep Multiple Instance Learning with ResNet (MILR) along with the new proposed ranking loss function achieves the best performance on the UCF-Crime benchmark dataset, as compared to other state-of-art methods. The effectiveness of our proposed method is demonstrated on the UCF-Crime dataset.