 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Convolutional with Attention for Action Recognition
Jun 05, 2022Human action recognition is one of the challenging tasks in computer vision. The current action recognition methods use computationally expensive models for learning spatio-temporal dependencies of the action. Models utilizing RGB channels and optical flow separately, models using a two-stream fusion technique, and models consisting of both convolutional neural network (CNN) and long-short term memory (LSTM) network are few examples of such complex models. Moreover, fine-tuning such complex models is computationally expensive as well. This paper proposes a deep neural network architecture for learning such dependencies consisting of a 3D convolutional layer, fully connected (FC) layers, and attention layer, which is simpler to implement and gives a competitive performance on the UCF-101 dataset. The proposed method first learns spatial and temporal features of actions through 3D-CNN, and then the attention mechanism helps the model to locate attention to essential features for recognition.
Label-Attention Transformer with Geometrically Coherent Objects for Image Captioning
Sep 16, 2021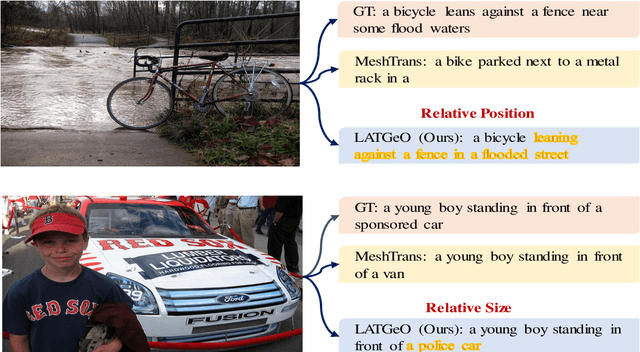

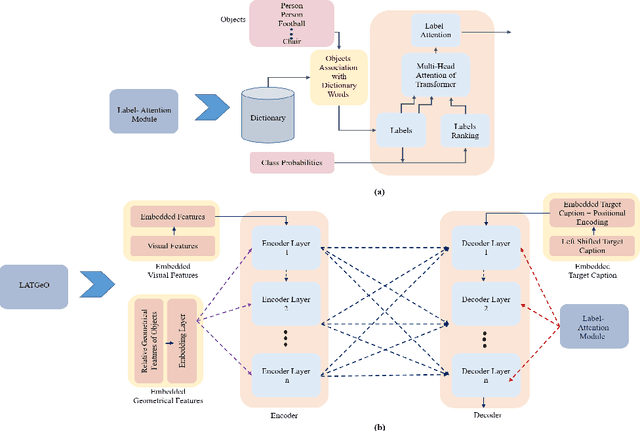
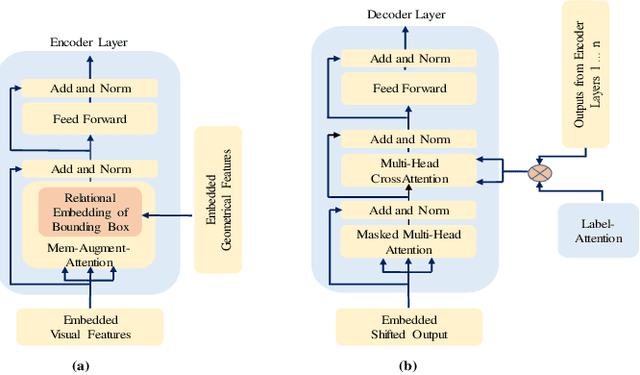
Automatic transcription of scene understanding in images and videos is a step towards artificial general intelligence. Image captioning is a nomenclature for describing meaningful information in an image using computer vision techniques. Automated image captioning techniques utilize encoder and decoder architecture, where the encoder extracts features from an image and the decoder generates a transcript. In this work, we investigate two unexplored ideas for image captioning using transformers: First, we demonstrate the enforcement of using objects' relevance in the surrounding environment. Second, learning an explicit association between labels and language constructs. We propose label-attention Transformer with geometrically coherent objects (LATGeO). The proposed technique acquires a proposal of geometrically coherent objects using a deep neural network (DNN) and generates captions by investigating their relationships using a label-attention module. Object coherence is defined using the localized ratio of the geometrical properties of the proposals. The label-attention module associates the extracted objects classes to the available dictionary using self-attention layers. The experimentation results show that objects' relevance in surroundings and binding of their visual feature with their geometrically localized ratios combined with its associated labels help in defining meaningful captions. The proposed framework is tested on the MSCOCO dataset, and a thorough evaluation resulting in overall better quantitative scores pronounces its superiority.
Image Captioning using Multiple Transformers for Self-Attention Mechanism
Feb 14, 2021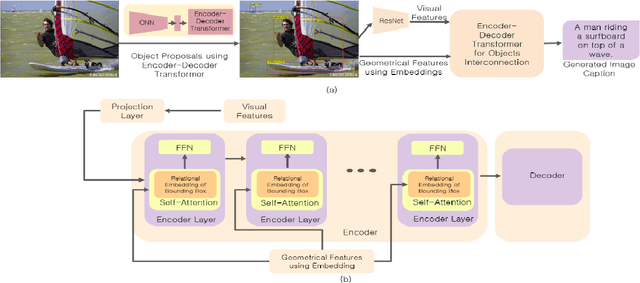

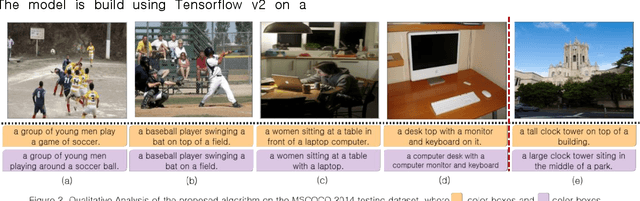

Real-time image captioning, along with adequate precision, is the main challenge of this research field. The present work, Multiple Transformers for Self-Attention Mechanism (MTSM), utilizes multiple transformers to address these problems. The proposed algorithm, MTSM, acquires region proposals using a transformer detector (DETR). Consequently, MTSM achieves the self-attention mechanism by transferring these region proposals and their visual and geometrical features through another transformer and learns the objects' local and global interconnections. The qualitative and quantitative results of the proposed algorithm, MTSM, are shown on the MSCOCO dataset.