 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegional Attention-Enhanced Swin Transformer for Clinically Relevant Medical Image Captioning
Nov 13, 2025Automated medical image captioning translates complex radiological images into diagnostic narratives that can support reporting workflows. We present a Swin-BART encoder-decoder system with a lightweight regional attention module that amplifies diagnostically salient regions before cross-attention. Trained and evaluated on ROCO, our model achieves state-of-the-art semantic fidelity while remaining compact and interpretable. We report results as mean$\pm$std over three seeds and include $95\%$ confidence intervals. Compared with baselines, our approach improves ROUGE (proposed 0.603, ResNet-CNN 0.356, BLIP2-OPT 0.255) and BERTScore (proposed 0.807, BLIP2-OPT 0.645, ResNet-CNN 0.623), with competitive BLEU, CIDEr, and METEOR. We further provide ablations (regional attention on/off and token-count sweep), per-modality analysis (CT/MRI/X-ray), paired significance tests, and qualitative heatmaps that visualize the regions driving each description. Decoding uses beam search (beam size $=4$), length penalty $=1.1$, $no\_repeat\_ngram\_size$ $=3$, and max length $=128$. The proposed design yields accurate, clinically phrased captions and transparent regional attributions, supporting safe research use with a human in the loop.
3D Convolutional with Attention for Action Recognition
Jun 05, 2022Human action recognition is one of the challenging tasks in computer vision. The current action recognition methods use computationally expensive models for learning spatio-temporal dependencies of the action. Models utilizing RGB channels and optical flow separately, models using a two-stream fusion technique, and models consisting of both convolutional neural network (CNN) and long-short term memory (LSTM) network are few examples of such complex models. Moreover, fine-tuning such complex models is computationally expensive as well. This paper proposes a deep neural network architecture for learning such dependencies consisting of a 3D convolutional layer, fully connected (FC) layers, and attention layer, which is simpler to implement and gives a competitive performance on the UCF-101 dataset. The proposed method first learns spatial and temporal features of actions through 3D-CNN, and then the attention mechanism helps the model to locate attention to essential features for recognition.
Label-Attention Transformer with Geometrically Coherent Objects for Image Captioning
Sep 16, 2021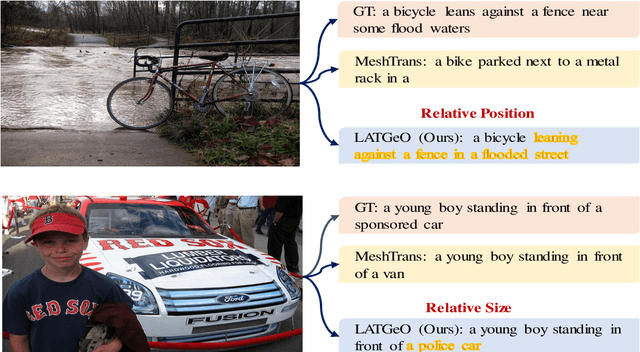

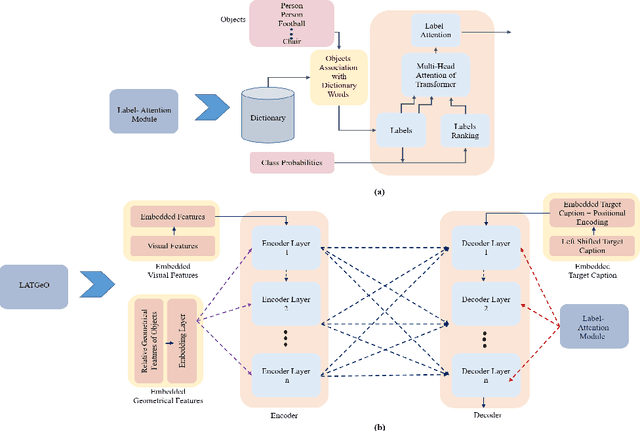
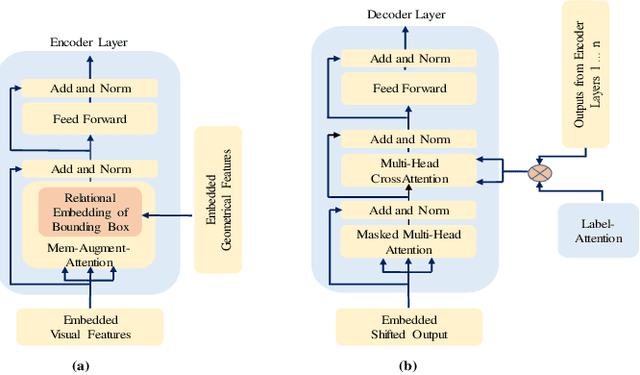
Automatic transcription of scene understanding in images and videos is a step towards artificial general intelligence. Image captioning is a nomenclature for describing meaningful information in an image using computer vision techniques. Automated image captioning techniques utilize encoder and decoder architecture, where the encoder extracts features from an image and the decoder generates a transcript. In this work, we investigate two unexplored ideas for image captioning using transformers: First, we demonstrate the enforcement of using objects' relevance in the surrounding environment. Second, learning an explicit association between labels and language constructs. We propose label-attention Transformer with geometrically coherent objects (LATGeO). The proposed technique acquires a proposal of geometrically coherent objects using a deep neural network (DNN) and generates captions by investigating their relationships using a label-attention module. Object coherence is defined using the localized ratio of the geometrical properties of the proposals. The label-attention module associates the extracted objects classes to the available dictionary using self-attention layers. The experimentation results show that objects' relevance in surroundings and binding of their visual feature with their geometrically localized ratios combined with its associated labels help in defining meaningful captions. The proposed framework is tested on the MSCOCO dataset, and a thorough evaluation resulting in overall better quantitative scores pronounces its superiority.
RVMDE: Radar Validated Monocular Depth Estimation for Robotics
Sep 11, 2021



Stereoscopy exposits a natural perception of distance in a scene, and its manifestation in 3D world understanding is an intuitive phenomenon. However, an innate rigid calibration of binocular vision sensors is crucial for accurate depth estimation. Alternatively, a monocular camera alleviates the limitation at the expense of accuracy in estimating depth, and the challenge exacerbates in harsh environmental conditions. Moreover, an optical sensor often fails to acquire vital signals in harsh environments, and radar is used instead, which gives coarse but more accurate signals. This work explores the utility of coarse signals from radar when fused with fine-grained data from a monocular camera for depth estimation in harsh environmental conditions. A variant of feature pyramid network (FPN) extensively operates on fine-grained image features at multiple scales with a fewer number of parameters. FPN feature maps are fused with sparse radar features extracted with a Convolutional neural network. The concatenated hierarchical features are used to predict the depth with ordinal regression. We performed experiments on the nuScenes dataset, and the proposed architecture stays on top in quantitative evaluations with reduced parameters and faster inference. The depth estimation results suggest that the proposed techniques can be used as an alternative to stereo depth estimation in critical applications in robotics and self-driving cars. The source code will be available in the following: \url{https://github.com/MI-Hussain/RVMDE}.
Thermal Object Detection using Domain Adaptation through Style Consistency
Jun 01, 2020

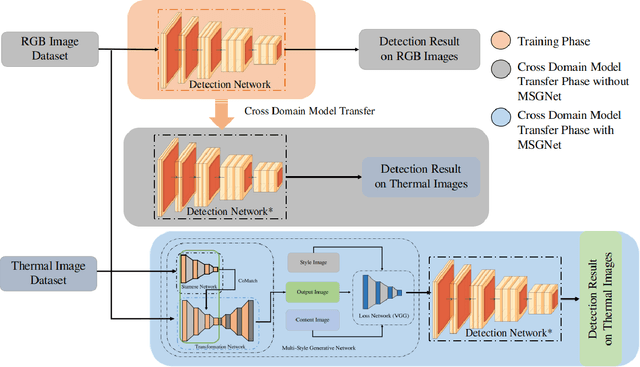

A recent fatal accident of an autonomous vehicle opens a debate about the use of infrared technology in the sensor suite for autonomous driving to increase visibility for robust object detection. Thermal imaging has an advantage over lidar, radar, and camera because it can detect the heat difference emitted by objects in the infrared spectrum. In contrast, lidar and camera capture in the visible spectrum, and adverse weather conditions can impact their accuracy. The limitations of object detection in images from conventional imaging sensors can be catered to by thermal images. This paper presents a domain adaptation method for object detection in thermal images. We explore multiple ideas of domain adaption. First, a generative adversarial network is used to transfer the low-level features from the visible spectrum to the infrared spectrum domain through style consistency. Second, a cross-domain model with style consistency is used for object detection in the infrared spectrum by transferring the trained visible spectrum model. The proposed strategies are evaluated on publicly available thermal image datasets (FLIR ADAS and KAIST Multi-Spectral). We find that adapting the low-level features from the source domain to the target domain through domain adaptation increases in mean average precision by approximately 10%.