 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Trust in Virtual Immunohistochemistry: Automated Assessment of Image Quality
Nov 06, 2025
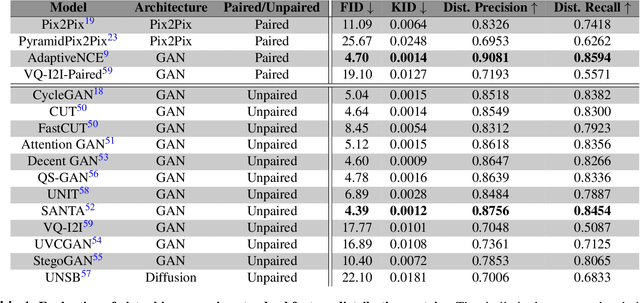

Deep learning models can generate virtual immunohistochemistry (IHC) stains from hematoxylin and eosin (H&E) images, offering a scalable and low-cost alternative to laboratory IHC. However, reliable evaluation of image quality remains a challenge as current texture- and distribution-based metrics quantify image fidelity rather than the accuracy of IHC staining. Here, we introduce an automated and accuracy grounded framework to determine image quality across sixteen paired or unpaired image translation models. Using color deconvolution, we generate masks of pixels stained brown (i.e., IHC-positive) as predicted by each virtual IHC model. We use the segmented masks of real and virtual IHC to compute stain accuracy metrics (Dice, IoU, Hausdorff distance) that directly quantify correct pixel - level labeling without needing expert manual annotations. Our results demonstrate that conventional image fidelity metrics, including Frechet Inception Distance (FID), peak signal-to-noise ratio (PSNR), and structural similarity (SSIM), correlate poorly with stain accuracy and pathologist assessment. Paired models such as PyramidPix2Pix and AdaptiveNCE achieve the highest stain accuracy, whereas unpaired diffusion- and GAN-based models are less reliable in providing accurate IHC positive pixel labels. Moreover, whole-slide images (WSI) reveal performance declines that are invisible in patch-based evaluations, emphasizing the need for WSI-level benchmarks. Together, this framework defines a reproducible approach for assessing the quality of virtual IHC models, a critical step to accelerate translation towards routine use by pathologists.
ImplicitStainer: Data-Efficient Medical Image Translation for Virtual Antibody-based Tissue Staining Using Local Implicit Functions
May 14, 2025Hematoxylin and eosin (H&E) staining is a gold standard for microscopic diagnosis in pathology. However, H&E staining does not capture all the diagnostic information that may be needed. To obtain additional molecular information, immunohistochemical (IHC) stains highlight proteins that mark specific cell types, such as CD3 for T-cells or CK8/18 for epithelial cells. While IHC stains are vital for prognosis and treatment guidance, they are typically only available at specialized centers and time consuming to acquire, leading to treatment delays for patients. Virtual staining, enabled by deep learning-based image translation models, provides a promising alternative by computationally generating IHC stains from H&E stained images. Although many GAN and diffusion based image to image (I2I) translation methods have been used for virtual staining, these models treat image patches as independent data points, which results in increased and more diverse data requirements for effective generation. We present ImplicitStainer, a novel approach that leverages local implicit functions to improve image translation, specifically virtual staining performance, by focusing on pixel-level predictions. This method enhances robustness to variations in dataset sizes, delivering high-quality results even with limited data. We validate our approach on two datasets using a comprehensive set of metrics and benchmark it against over fifteen state-of-the-art GAN- and diffusion based models. Full Code and models trained will be released publicly via Github upon acceptance.
BoundarySeg:An Embarrassingly Simple Method To Boost Medical Image Segmentation Performance for Low Data Regimes
May 14, 2025


Obtaining large-scale medical data, annotated or unannotated, is challenging due to stringent privacy regulations and data protection policies. In addition, annotating medical images requires that domain experts manually delineate anatomical structures, making the process both time-consuming and costly. As a result, semi-supervised methods have gained popularity for reducing annotation costs. However, the performance of semi-supervised methods is heavily dependent on the availability of unannotated data, and their effectiveness declines when such data are scarce or absent. To overcome this limitation, we propose a simple, yet effective and computationally efficient approach for medical image segmentation that leverages only existing annotations. We propose BoundarySeg , a multi-task framework that incorporates organ boundary prediction as an auxiliary task to full organ segmentation, leveraging consistency between the two task predictions to provide additional supervision. This strategy improves segmentation accuracy, especially in low data regimes, allowing our method to achieve performance comparable to or exceeding state-of-the-art semi supervised approaches all without relying on unannotated data or increasing computational demands. Code will be released upon acceptance.
Leveraging LLM For Synchronizing Information Across Multilingual Tables
Apr 03, 2025The vast amount of online information today poses challenges for non-English speakers, as much of it is concentrated in high-resource languages such as English and French. Wikipedia reflects this imbalance, with content in low-resource languages frequently outdated or incomplete. Recent research has sought to improve cross-language synchronization of Wikipedia tables using rule-based methods. These approaches can be effective, but they struggle with complexity and generalization. This paper explores large language models (LLMs) for multilingual information synchronization, using zero-shot prompting as a scalable solution. We introduce the Information Updation dataset, simulating the real-world process of updating outdated Wikipedia tables, and evaluate LLM performance. Our findings reveal that single-prompt approaches often produce suboptimal results, prompting us to introduce a task decomposition strategy that enhances coherence and accuracy. Our proposed method outperforms existing baselines, particularly in Information Updation (1.79%) and Information Addition (20.58%), highlighting the model strength in dynamically updating and enriching data across architectures
TransientTables: Evaluating LLMs' Reasoning on Temporally Evolving Semi-structured Tables
Apr 02, 2025Humans continuously make new discoveries, and understanding temporal sequence of events leading to these breakthroughs is essential for advancing science and society. This ability to reason over time allows us to identify future steps and understand the effects of financial and political decisions on our lives. However, large language models (LLMs) are typically trained on static datasets, limiting their ability to perform effective temporal reasoning. To assess the temporal reasoning capabilities of LLMs, we present the TRANSIENTTABLES dataset, which comprises 3,971 questions derived from over 14,000 tables, spanning 1,238 entities across multiple time periods. We introduce a template-based question-generation pipeline that harnesses LLMs to refine both templates and questions. Additionally, we establish baseline results using state-of-the-art LLMs to create a benchmark. We also introduce novel modeling strategies centered around task decomposition, enhancing LLM performance.
Weakly SSM : On the Viability of Weakly Supervised Segmentations for Statistical Shape Modeling
Jul 21, 2024Statistical Shape Models (SSMs) excel at identifying population level anatomical variations, which is at the core of various clinical and biomedical applications, including morphology-based diagnostics and surgical planning. However, the effectiveness of SSM is often constrained by the necessity for expert-driven manual segmentation, a process that is both time-intensive and expensive, thereby restricting their broader application and utility. Recent deep learning approaches enable the direct estimation of Statistical Shape Models (SSMs) from unsegmented images. While these models can predict SSMs without segmentation during deployment, they do not address the challenge of acquiring the manual annotations needed for training, particularly in resource-limited settings. Semi-supervised and foundation models for anatomy segmentation can mitigate the annotation burden. Yet, despite the abundance of available approaches, there are no established guidelines to inform end-users on their effectiveness for the downstream task of constructing SSMs. In this study, we systematically evaluate the potential of weakly supervised methods as viable alternatives to manual segmentation's for building SSMs. We establish a new performance benchmark by employing various semi-supervised and foundational model methods for anatomy segmentation under low annotation settings, utilizing the predicted segmentation's for the task of SSM. We compare the modes of shape variation and use quantitative metrics to compare against a shape model derived from a manually annotated dataset. Our results indicate that some methods produce noisy segmentation, which is very unfavorable for SSM tasks, while others can capture the correct modes of variations in the population cohort with 60-80\% reduction in required manual annotation.
NTSEBENCH: Cognitive Reasoning Benchmark for Vision Language Models
Jul 15, 2024



Cognitive textual and visual reasoning tasks, such as puzzles, series, and analogies, demand the ability to quickly reason, decipher, and evaluate patterns both textually and spatially. While LLMs and VLMs, through extensive training on large amounts of human-curated data, have attained a high level of pseudo-human intelligence in some common sense reasoning tasks, they still struggle with more complex reasoning tasks that require cognitive understanding. In this work, we introduce a new dataset, NTSEBench, designed to evaluate the cognitive multi-modal reasoning and problem-solving skills of large models. The dataset comprises 2,728 multiple-choice questions comprising of a total of 4,642 images across 26 categories sampled from the NTSE examination conducted nationwide in India, featuring both visual and textual general aptitude questions that do not rely on rote learning. We establish baselines on the dataset using state-of-the-art LLMs and VLMs. To facilitate a comparison between open source and propriety models, we propose four distinct modeling strategies to handle different modalities (text and images) in the dataset instances.
Estimation and Analysis of Slice Propagation Uncertainty in 3D Anatomy Segmentation
Mar 18, 2024



Supervised methods for 3D anatomy segmentation demonstrate superior performance but are often limited by the availability of annotated data. This limitation has led to a growing interest in self-supervised approaches in tandem with the abundance of available un-annotated data. Slice propagation has emerged as an self-supervised approach that leverages slice registration as a self-supervised task to achieve full anatomy segmentation with minimal supervision. This approach significantly reduces the need for domain expertise, time, and the cost associated with building fully annotated datasets required for training segmentation networks. However, this shift toward reduced supervision via deterministic networks raises concerns about the trustworthiness and reliability of predictions, especially when compared with more accurate supervised approaches. To address this concern, we propose the integration of calibrated uncertainty quantification (UQ) into slice propagation methods, providing insights into the model's predictive reliability and confidence levels. Incorporating uncertainty measures enhances user confidence in self-supervised approaches, thereby improving their practical applicability. We conducted experiments on three datasets for 3D abdominal segmentation using five UQ methods. The results illustrate that incorporating UQ improves not only model trustworthiness, but also segmentation accuracy. Furthermore, our analysis reveals various failure modes of slice propagation methods that might not be immediately apparent to end-users. This study opens up new research avenues to improve the accuracy and trustworthiness of slice propagation methods.
StainDiffuser: MultiTask Dual Diffusion Model for Virtual Staining
Mar 17, 2024Hematoxylin and Eosin (H&E) staining is the most commonly used for disease diagnosis and tumor recurrence tracking. Hematoxylin excels at highlighting nuclei, whereas eosin stains the cytoplasm. However, H&E stain lacks details for differentiating different types of cells relevant to identifying the grade of the disease or response to specific treatment variations. Pathologists require special immunohistochemical (IHC) stains that highlight different cell types. These stains help in accurately identifying different regions of disease growth and their interactions with the cell's microenvironment. The advent of deep learning models has made Image-to-Image (I2I) translation a key research area, reducing the need for expensive physical staining processes. Pix2Pix and CycleGAN are still the most commonly used methods for virtual staining applications. However, both suffer from hallucinations or staining irregularities when H&E stain has less discriminate information about the underlying cells IHC needs to highlight (e.g.,CD3 lymphocytes). Diffusion models are currently the state-of-the-art models for image generation and conditional generation tasks. However, they require extensive and diverse datasets (millions of samples) to converge, which is less feasible for virtual staining applications.Inspired by the success of multitask deep learning models for limited dataset size, we propose StainDiffuser, a novel multitask dual diffusion architecture for virtual staining that converges under a limited training budget. StainDiffuser trains two diffusion processes simultaneously: (a) generation of cell-specific IHC stain from H&E and (b) H&E-based cell segmentation using coarse segmentation only during training. Our results show that StainDiffuser produces high-quality results for easier (CK8/18,epithelial marker) and difficult stains(CD3, Lymphocytes).
EfficientMorph: Parameter-Efficient Transformer-Based Architecture for 3D Image Registration
Mar 16, 2024



Transformers have emerged as the state-of-the-art architecture in medical image registration, outperforming convolutional neural networks (CNNs) by addressing their limited receptive fields and overcoming gradient instability in deeper models. Despite their success, transformer-based models require substantial resources for training, including data, memory, and computational power, which may restrict their applicability for end users with limited resources. In particular, existing transformer-based 3D image registration architectures face three critical gaps that challenge their efficiency and effectiveness. Firstly, while mitigating the quadratic complexity of full attention by focusing on local regions, window-based attention mechanisms often fail to adequately integrate local and global information. Secondly, feature similarities across attention heads that were recently found in multi-head attention architectures indicate a significant computational redundancy, suggesting that the capacity of the network could be better utilized to enhance performance. Lastly, the granularity of tokenization, a key factor in registration accuracy, presents a trade-off; smaller tokens improve detail capture at the cost of higher computational complexity, increased memory demands, and a risk of overfitting. Here, we propose EfficientMorph, a transformer-based architecture for unsupervised 3D image registration. It optimizes the balance between local and global attention through a plane-based attention mechanism, reduces computational redundancy via cascaded group attention, and captures fine details without compromising computational efficiency, thanks to a Hi-Res tokenization strategy complemented by merging operations. Notably, EfficientMorph sets a new benchmark for performance on the OASIS dataset with 16-27x fewer parameters.