 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficientMorph: Parameter-Efficient Transformer-Based Architecture for 3D Image Registration
Mar 16, 2024



Transformers have emerged as the state-of-the-art architecture in medical image registration, outperforming convolutional neural networks (CNNs) by addressing their limited receptive fields and overcoming gradient instability in deeper models. Despite their success, transformer-based models require substantial resources for training, including data, memory, and computational power, which may restrict their applicability for end users with limited resources. In particular, existing transformer-based 3D image registration architectures face three critical gaps that challenge their efficiency and effectiveness. Firstly, while mitigating the quadratic complexity of full attention by focusing on local regions, window-based attention mechanisms often fail to adequately integrate local and global information. Secondly, feature similarities across attention heads that were recently found in multi-head attention architectures indicate a significant computational redundancy, suggesting that the capacity of the network could be better utilized to enhance performance. Lastly, the granularity of tokenization, a key factor in registration accuracy, presents a trade-off; smaller tokens improve detail capture at the cost of higher computational complexity, increased memory demands, and a risk of overfitting. Here, we propose EfficientMorph, a transformer-based architecture for unsupervised 3D image registration. It optimizes the balance between local and global attention through a plane-based attention mechanism, reduces computational redundancy via cascaded group attention, and captures fine details without compromising computational efficiency, thanks to a Hi-Res tokenization strategy complemented by merging operations. Notably, EfficientMorph sets a new benchmark for performance on the OASIS dataset with 16-27x fewer parameters.
Progressive DeepSSM: Training Methodology for Image-To-Shape Deep Models
Oct 02, 2023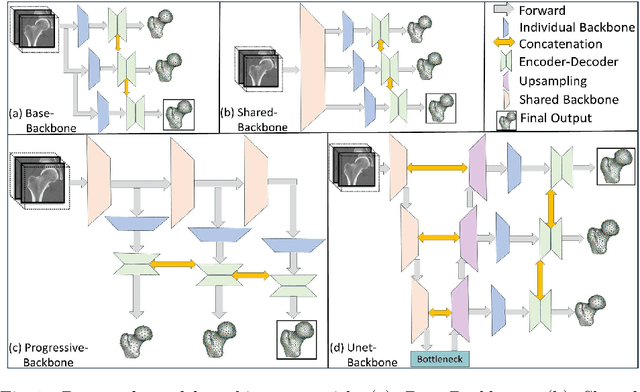
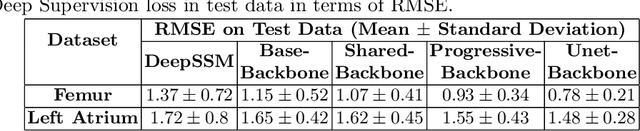
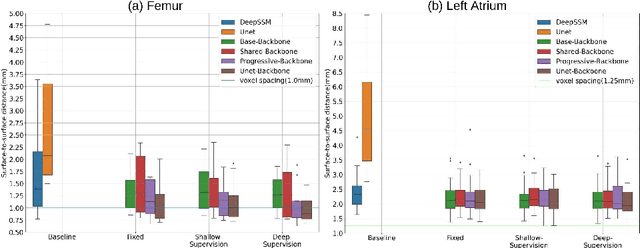

Statistical shape modeling (SSM) is an enabling quantitative tool to study anatomical shapes in various medical applications. However, directly using 3D images in these applications still has a long way to go. Recent deep learning methods have paved the way for reducing the substantial preprocessing steps to construct SSMs directly from unsegmented images. Nevertheless, the performance of these models is not up to the mark. Inspired by multiscale/multiresolution learning, we propose a new training strategy, progressive DeepSSM, to train image-to-shape deep learning models. The training is performed in multiple scales, and each scale utilizes the output from the previous scale. This strategy enables the model to learn coarse shape features in the first scales and gradually learn detailed fine shape features in the later scales. We leverage shape priors via segmentation-guided multi-task learning and employ deep supervision loss to ensure learning at each scale. Experiments show the superiority of models trained by the proposed strategy from both quantitative and qualitative perspectives. This training methodology can be employed to improve the stability and accuracy of any deep learning method for inferring statistical representations of anatomies from medical images and can be adopted by existing deep learning methods to improve model accuracy and training stability.