 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Driven Compression for Low-Bitrate Talking Head Videos
Jun 16, 2025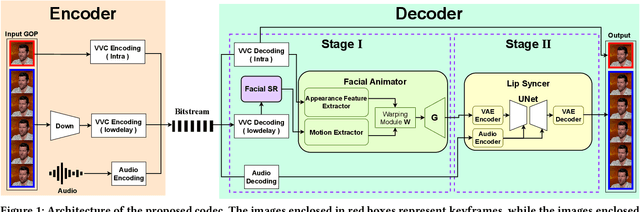

Talking head video compression has advanced with neural rendering and keypoint-based methods, but challenges remain, especially at low bit rates, including handling large head movements, suboptimal lip synchronization, and distorted facial reconstructions. To address these problems, we propose a novel audio-visual driven video codec that integrates compact 3D motion features and audio signals. This approach robustly models significant head rotations and aligns lip movements with speech, improving both compression efficiency and reconstruction quality. Experiments on the CelebV-HQ dataset show that our method reduces bitrate by 22% compared to VVC and by 8.5% over state-of-the-art learning-based codec. Furthermore, it provides superior lip-sync accuracy and visual fidelity at comparable bitrates, highlighting its effectiveness in bandwidth-constrained scenarios.
Bidirectional Learned Facial Animation Codec for Low Bitrate Talking Head Videos
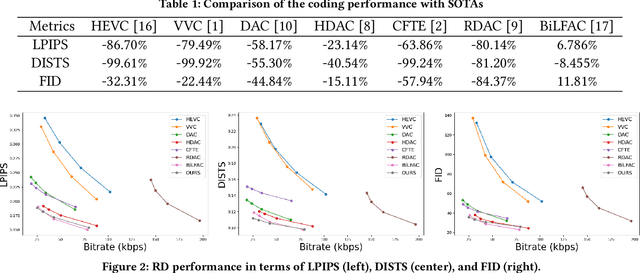
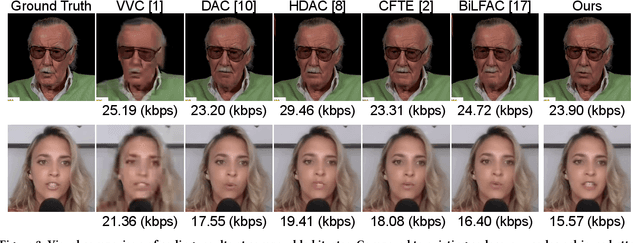
Mar 12, 2025Existing deep facial animation coding techniques efficiently compress talking head videos by applying deep generative models. Instead of compressing the entire video sequence, these methods focus on compressing only the keyframe and the keypoints of non-keyframes (target frames). The target frames are then reconstructed by utilizing a single keyframe, and the keypoints of the target frame. Although these unidirectional methods can reduce the bitrate, they rely on a single keyframe and often struggle to capture large head movements accurately, resulting in distortions in the facial region. In this paper, we propose a novel bidirectional learned animation codec that generates natural facial videos using past and future keyframes. First, in the Bidirectional Reference-Guided Auxiliary Stream Enhancement (BRG-ASE) process, we introduce a compact auxiliary stream for non-keyframes, which is enhanced by adaptively selecting one of two keyframes (past and future). This stream improves video quality with a slight increase in bitrate. Then, in the Bidirectional Reference-Guided Video Reconstruction (BRG-VRec) process, we animate the adaptively selected keyframe and reconstruct the target frame using both the animated keyframe and the auxiliary frame. Extensive experiments demonstrate a 55% bitrate reduction compared to the latest animation based video codec, and a 35% bitrate reduction compared to the latest video coding standard, Versatile Video Coding (VVC) on a talking head video dataset. It showcases the efficiency of our approach in improving video quality while simultaneously decreasing bitrate.
TKG-DM: Training-free Chroma Key Content Generation Diffusion Model
Nov 23, 2024



Diffusion models have enabled the generation of high-quality images with a strong focus on realism and textual fidelity. Yet, large-scale text-to-image models, such as Stable Diffusion, struggle to generate images where foreground objects are placed over a chroma key background, limiting their ability to separate foreground and background elements without fine-tuning. To address this limitation, we present a novel Training-Free Chroma Key Content Generation Diffusion Model (TKG-DM), which optimizes the initial random noise to produce images with foreground objects on a specifiable color background. Our proposed method is the first to explore the manipulation of the color aspects in initial noise for controlled background generation, enabling precise separation of foreground and background without fine-tuning. Extensive experiments demonstrate that our training-free method outperforms existing methods in both qualitative and quantitative evaluations, matching or surpassing fine-tuned models. Finally, we successfully extend it to other tasks (e.g., consistency models and text-to-video), highlighting its transformative potential across various generative applications where independent control of foreground and background is crucial.
Block based Adaptive Compressive Sensing with Sampling Rate Control
Nov 15, 2024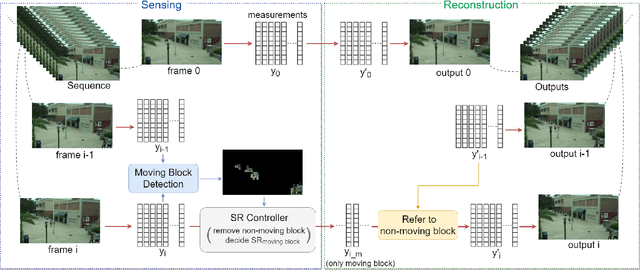
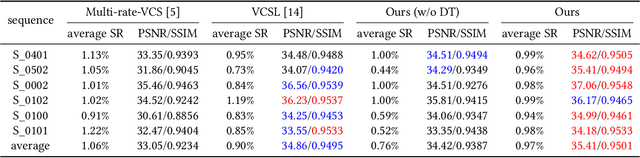
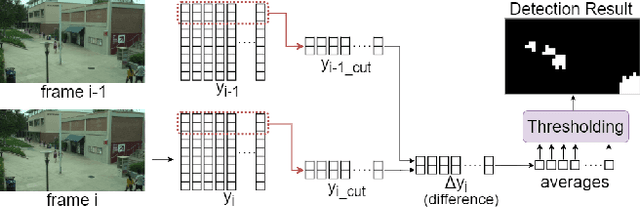
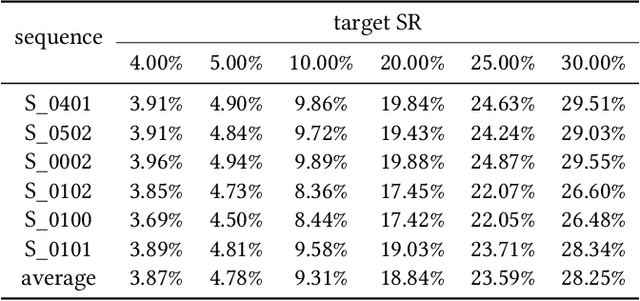
Compressive sensing (CS), acquiring and reconstructing signals below the Nyquist rate, has great potential in image and video acquisition to exploit data redundancy and greatly reduce the amount of sampled data. To further reduce the sampled data while keeping the video quality, this paper explores the temporal redundancy in video CS and proposes a block based adaptive compressive sensing framework with a sampling rate (SR) control strategy. To avoid redundant compression of non-moving regions, we first incorporate moving block detection between consecutive frames, and only transmit the measurements of moving blocks. The non-moving regions are reconstructed from the previous frame. In addition, we propose a block storage system and a dynamic threshold to achieve adaptive SR allocation to each frame based on the area of moving regions and target SR for controlling the average SR within the target SR. Finally, to reduce blocking artifacts and improve reconstruction quality, we adopt a cooperative reconstruction of the moving and non-moving blocks by referring to the measurements of the non-moving blocks from the previous frame. Extensive experiments have demonstrated that this work is able to control SR and obtain better performance than existing works.
Visual question answering based evaluation metrics for text-to-image generation
Nov 15, 2024Text-to-image generation and text-guided image manipulation have received considerable attention in the field of image generation tasks. However, the mainstream evaluation methods for these tasks have difficulty in evaluating whether all the information from the input text is accurately reflected in the generated images, and they mainly focus on evaluating the overall alignment between the input text and the generated images. This paper proposes new evaluation metrics that assess the alignment between input text and generated images for every individual object. Firstly, according to the input text, chatGPT is utilized to produce questions for the generated images. After that, we use Visual Question Answering(VQA) to measure the relevance of the generated images to the input text, which allows for a more detailed evaluation of the alignment compared to existing methods. In addition, we use Non-Reference Image Quality Assessment(NR-IQA) to evaluate not only the text-image alignment but also the quality of the generated images. Experimental results show that our proposed evaluation approach is the superior metric that can simultaneously assess finer text-image alignment and image quality while allowing for the adjustment of these ratios.
Edge-based Denoising Image Compression
Sep 17, 2024



In recent years, deep learning-based image compression, particularly through generative models, has emerged as a pivotal area of research. Despite significant advancements, challenges such as diminished sharpness and quality in reconstructed images, learning inefficiencies due to mode collapse, and data loss during transmission persist. To address these issues, we propose a novel compression model that incorporates a denoising step with diffusion models, significantly enhancing image reconstruction fidelity by sub-information(e.g., edge and depth) from leveraging latent space. Empirical experiments demonstrate that our model achieves superior or comparable results in terms of image quality and compression efficiency when measured against the existing models. Notably, our model excels in scenarios of partial image loss or excessive noise by introducing an edge estimation network to preserve the integrity of reconstructed images, offering a robust solution to the current limitations of image compression.
BATINet: Background-Aware Text to Image Synthesis and Manipulation Network
Aug 11, 2023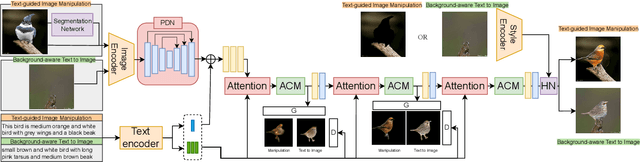


Background-Induced Text2Image (BIT2I) aims to generate foreground content according to the text on the given background image. Most studies focus on generating high-quality foreground content, although they ignore the relationship between the two contents. In this study, we analyzed a novel Background-Aware Text2Image (BAT2I) task in which the generated content matches the input background. We proposed a Background-Aware Text to Image synthesis and manipulation Network (BATINet), which contains two key components: Position Detect Network (PDN) and Harmonize Network (HN). The PDN detects the most plausible position of the text-relevant object in the background image. The HN harmonizes the generated content referring to background style information. Finally, we reconstructed the generation network, which consists of the multi-GAN and attention module to match more user preferences. Moreover, we can apply BATINet to text-guided image manipulation. It solves the most challenging task of manipulating the shape of an object. We demonstrated through qualitative and quantitative evaluations on the CUB dataset that the proposed model outperforms other state-of-the-art methods.
Interactive Image Manipulation with Complex Text Instructions
Nov 25, 2022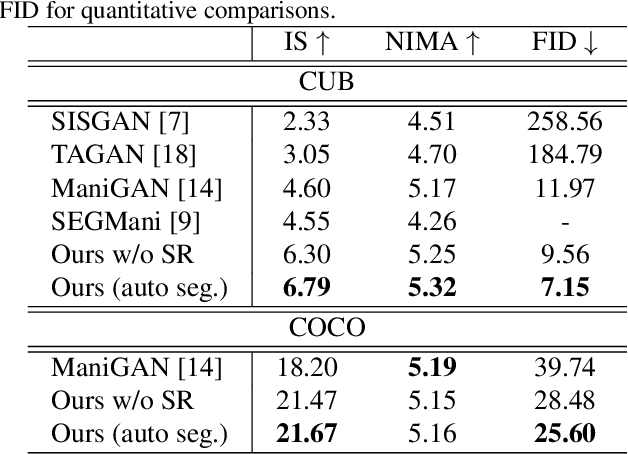
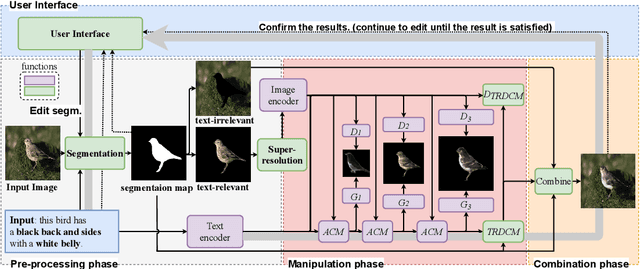
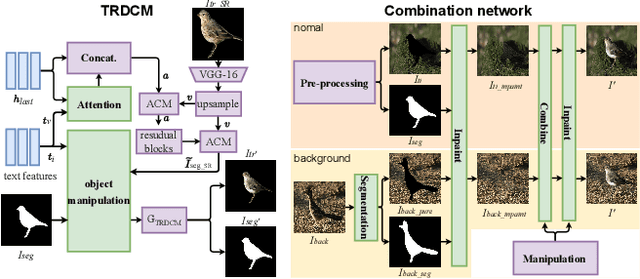

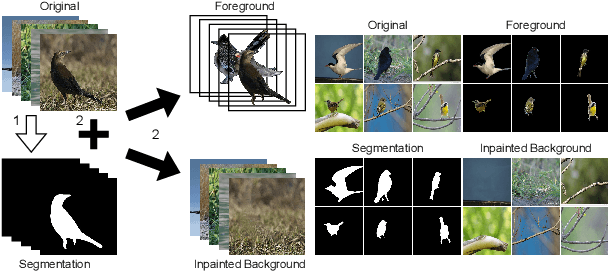
Recently, text-guided image manipulation has received increasing attention in the research field of multimedia processing and computer vision due to its high flexibility and controllability. Its goal is to semantically manipulate parts of an input reference image according to the text descriptions. However, most of the existing works have the following problems: (1) text-irrelevant content cannot always be maintained but randomly changed, (2) the performance of image manipulation still needs to be further improved, (3) only can manipulate descriptive attributes. To solve these problems, we propose a novel image manipulation method that interactively edits an image using complex text instructions. It allows users to not only improve the accuracy of image manipulation but also achieve complex tasks such as enlarging, dwindling, or removing objects and replacing the background with the input image. To make these tasks possible, we apply three strategies. First, the given image is divided into text-relevant content and text-irrelevant content. Only the text-relevant content is manipulated and the text-irrelevant content can be maintained. Second, a super-resolution method is used to enlarge the manipulation region to further improve the operability and to help manipulate the object itself. Third, a user interface is introduced for editing the segmentation map interactively to re-modify the generated image according to the user's desires. Extensive experiments on the Caltech-UCSD Birds-200-2011 (CUB) dataset and Microsoft Common Objects in Context (MS COCO) datasets demonstrate our proposed method can enable interactive, flexible, and accurate image manipulation in real-time. Through qualitative and quantitative evaluations, we show that the proposed model outperforms other state-of-the-art methods.