 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeer-aided Repairer: Empowering Large Language Models to Repair Advanced Student Assignments
Apr 02, 2024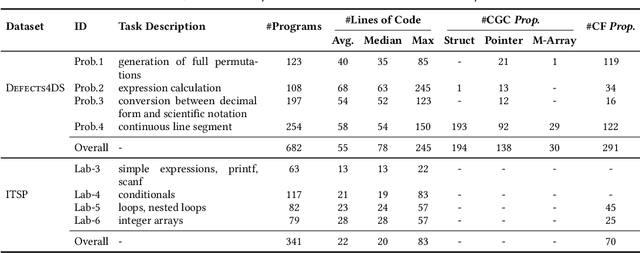
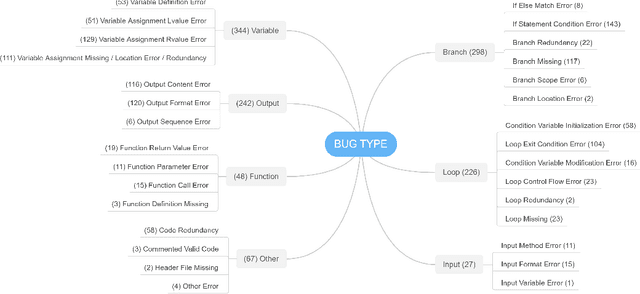
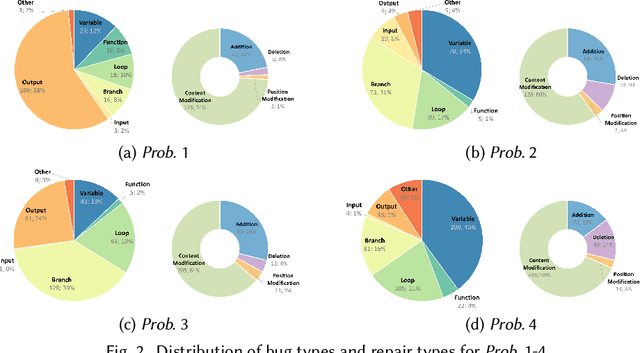
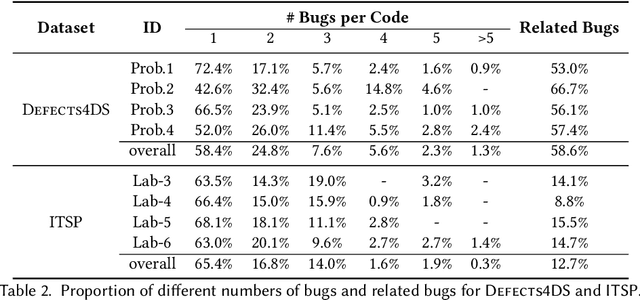
Automated generation of feedback on programming assignments holds significant benefits for programming education, especially when it comes to advanced assignments. Automated Program Repair techniques, especially Large Language Model based approaches, have gained notable recognition for their potential to fix introductory assignments. However, the programs used for evaluation are relatively simple. It remains unclear how existing approaches perform in repairing programs from higher-level programming courses. To address these limitations, we curate a new advanced student assignment dataset named Defects4DS from a higher-level programming course. Subsequently, we identify the challenges related to fixing bugs in advanced assignments. Based on the analysis, we develop a framework called PaR that is powered by the LLM. PaR works in three phases: Peer Solution Selection, Multi-Source Prompt Generation, and Program Repair. Peer Solution Selection identifies the closely related peer programs based on lexical, semantic, and syntactic criteria. Then Multi-Source Prompt Generation adeptly combines multiple sources of information to create a comprehensive and informative prompt for the last Program Repair stage. The evaluation on Defects4DS and another well-investigated ITSP dataset reveals that PaR achieves a new state-of-the-art performance, demonstrating impressive improvements of 19.94% and 15.2% in repair rate compared to prior state-of-the-art LLM- and symbolic-based approaches, respectively
Differentially Private Pre-Trained Model Fusion using Decentralized Federated Graph Matching
Nov 05, 2023



Model fusion is becoming a crucial component in the context of model-as-a-service scenarios, enabling the delivery of high-quality model services to local users. However, this approach introduces privacy risks and imposes certain limitations on its applications. Ensuring secure model exchange and knowledge fusion among users becomes a significant challenge in this setting. To tackle this issue, we propose PrivFusion, a novel architecture that preserves privacy while facilitating model fusion under the constraints of local differential privacy. PrivFusion leverages a graph-based structure, enabling the fusion of models from multiple parties without necessitating retraining. By employing randomized mechanisms, PrivFusion ensures privacy guarantees throughout the fusion process. To enhance model privacy, our approach incorporates a hybrid local differentially private mechanism and decentralized federated graph matching, effectively protecting both activation values and weights. Additionally, we introduce a perturbation filter adapter to alleviate the impact of randomized noise, thereby preserving the utility of the fused model. Through extensive experiments conducted on diverse image datasets and real-world healthcare applications, we provide empirical evidence showcasing the effectiveness of PrivFusion in maintaining model performance while preserving privacy. Our contributions offer valuable insights and practical solutions for secure and collaborative data analysis within the domain of privacy-preserving model fusion.
Improving speech recognition models with small samples for air traffic control systems
Feb 16, 2021
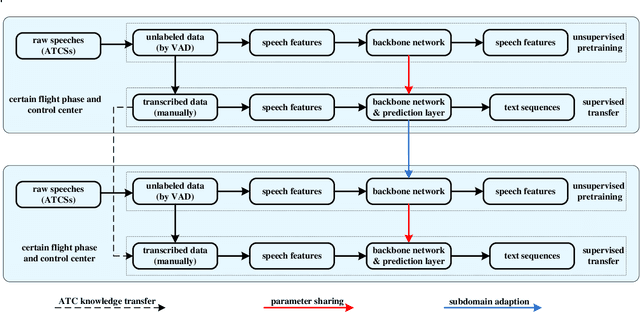
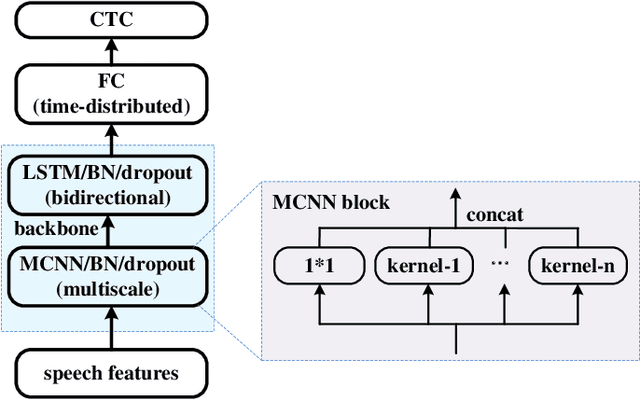
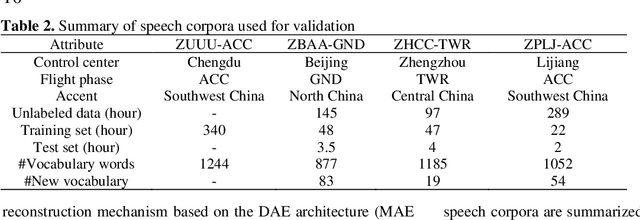
In the domain of air traffic control (ATC) systems, efforts to train a practical automatic speech recognition (ASR) model always faces the problem of small training samples since the collection and annotation of speech samples are expert- and domain-dependent task. In this work, a novel training approach based on pretraining and transfer learning is proposed to address this issue, and an improved end-to-end deep learning model is developed to address the specific challenges of ASR in the ATC domain. An unsupervised pretraining strategy is first proposed to learn speech representations from unlabeled samples for a certain dataset. Specifically, a masking strategy is applied to improve the diversity of the sample without losing their general patterns. Subsequently, transfer learning is applied to fine-tune a pretrained or other optimized baseline models to finally achieves the supervised ASR task. By virtue of the common terminology used in the ATC domain, the transfer learning task can be regarded as a sub-domain adaption task, in which the transferred model is optimized using a joint corpus consisting of baseline samples and new transcribed samples from the target dataset. This joint corpus construction strategy enriches the size and diversity of the training samples, which is important for addressing the issue of the small transcribed corpus. In addition, speed perturbation is applied to augment the new transcribed samples to further improve the quality of the speech corpus. Three real ATC datasets are used to validate the proposed ASR model and training strategies. The experimental results demonstrate that the ASR performance is significantly improved on all three datasets, with an absolute character error rate only one-third of that achieved through the supervised training. The applicability of the proposed strategies to other ASR approaches is also validated.