 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Pre-Trained Model Fusion using Decentralized Federated Graph Matching
Nov 05, 2023



Model fusion is becoming a crucial component in the context of model-as-a-service scenarios, enabling the delivery of high-quality model services to local users. However, this approach introduces privacy risks and imposes certain limitations on its applications. Ensuring secure model exchange and knowledge fusion among users becomes a significant challenge in this setting. To tackle this issue, we propose PrivFusion, a novel architecture that preserves privacy while facilitating model fusion under the constraints of local differential privacy. PrivFusion leverages a graph-based structure, enabling the fusion of models from multiple parties without necessitating retraining. By employing randomized mechanisms, PrivFusion ensures privacy guarantees throughout the fusion process. To enhance model privacy, our approach incorporates a hybrid local differentially private mechanism and decentralized federated graph matching, effectively protecting both activation values and weights. Additionally, we introduce a perturbation filter adapter to alleviate the impact of randomized noise, thereby preserving the utility of the fused model. Through extensive experiments conducted on diverse image datasets and real-world healthcare applications, we provide empirical evidence showcasing the effectiveness of PrivFusion in maintaining model performance while preserving privacy. Our contributions offer valuable insights and practical solutions for secure and collaborative data analysis within the domain of privacy-preserving model fusion.
FedBone: Towards Large-Scale Federated Multi-Task Learning
Jun 30, 2023



Heterogeneous federated multi-task learning (HFMTL) is a federated learning technique that combines heterogeneous tasks of different clients to achieve more accurate, comprehensive predictions. In real-world applications, visual and natural language tasks typically require large-scale models to extract high-level abstract features. However, large-scale models cannot be directly applied to existing federated multi-task learning methods. Existing HFML methods also disregard the impact of gradient conflicts on multi-task optimization during the federated aggregation process. In this work, we propose an innovative framework called FedBone, which enables the construction of large-scale models with better generalization from the perspective of server-client split learning and gradient projection. We split the entire model into two components: a large-scale general model (referred to as the general model) on the cloud server and multiple task-specific models (referred to as the client model) on edge clients, solving the problem of insufficient computing power on edge clients. The conflicting gradient projection technique is used to enhance the generalization of the large-scale general model between different tasks. The proposed framework is evaluated on two benchmark datasets and a real ophthalmic dataset. Comprehensive results demonstrate that FedBone efficiently adapts to heterogeneous local tasks of each client and outperforms existing federated learning algorithms in most dense prediction and classification tasks with off-the-shelf computational resources on the client side.
Domain Generalization for Activity Recognition via Adaptive Feature Fusion
Jul 21, 2022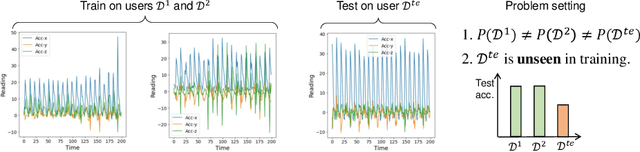

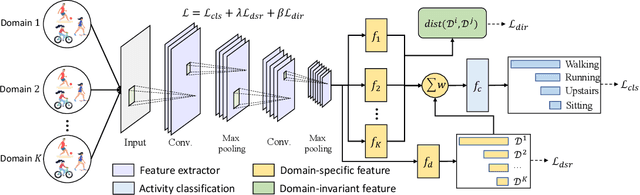

Human activity recognition requires the efforts to build a generalizable model using the training datasets with the hope to achieve good performance in test datasets. However, in real applications, the training and testing datasets may have totally different distributions due to various reasons such as different body shapes, acting styles, and habits, damaging the model's generalization performance. While such a distribution gap can be reduced by existing domain adaptation approaches, they typically assume that the test data can be accessed in the training stage, which is not realistic. In this paper, we consider a more practical and challenging scenario: domain-generalized activity recognition (DGAR) where the test dataset \emph{cannot} be accessed during training. To this end, we propose \emph{Adaptive Feature Fusion for Activity Recognition~(AFFAR)}, a domain generalization approach that learns to fuse the domain-invariant and domain-specific representations to improve the model's generalization performance. AFFAR takes the best of both worlds where domain-invariant representations enhance the transferability across domains and domain-specific representations leverage the model discrimination power from each domain. Extensive experiments on three public HAR datasets show its effectiveness. Furthermore, we apply AFFAR to a real application, i.e., the diagnosis of Children's Attention Deficit Hyperactivity Disorder~(ADHD), which also demonstrates the superiority of our approach.