 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Flexible Scenario Generation in Godot Simulator
Dec 24, 2024Cyber-physical systems (CPS) combine cyber and physical components engineered to make decisions and interact within dynamic environments. Ensuring the safety of CPS is of great importance, requiring extensive testing across diverse and complex scenarios. To generate as many testing scenarios as possible, previous efforts have focused on describing scenarios using formal languages to generate scenes. In this paper, we introduce an alternative approach: reconstructing scenes inside the open-source game engine, Godot. We have developed a pipeline that enables the reconstruction of testing scenes directly from provided images of scenarios. These reconstructed scenes can then be deployed within simulated environments to assess a CPS. This approach offers a scalable and flexible solution for testing CPS in realistic environments.
The Task Shield: Enforcing Task Alignment to Defend Against Indirect Prompt Injection in LLM Agents
Dec 21, 2024Large Language Model (LLM) agents are increasingly being deployed as conversational assistants capable of performing complex real-world tasks through tool integration. This enhanced ability to interact with external systems and process various data sources, while powerful, introduces significant security vulnerabilities. In particular, indirect prompt injection attacks pose a critical threat, where malicious instructions embedded within external data sources can manipulate agents to deviate from user intentions. While existing defenses based on rule constraints, source spotlighting, and authentication protocols show promise, they struggle to maintain robust security while preserving task functionality. We propose a novel and orthogonal perspective that reframes agent security from preventing harmful actions to ensuring task alignment, requiring every agent action to serve user objectives. Based on this insight, we develop Task Shield, a test-time defense mechanism that systematically verifies whether each instruction and tool call contributes to user-specified goals. Through experiments on the AgentDojo benchmark, we demonstrate that Task Shield reduces attack success rates (2.07\%) while maintaining high task utility (69.79\%) on GPT-4o.
Multi-agent Path Finding for Timed Tasks using Evolutionary Games
Nov 15, 2024Autonomous multi-agent systems such as hospital robots and package delivery drones often operate in highly uncertain environments and are expected to achieve complex temporal task objectives while ensuring safety. While learning-based methods such as reinforcement learning are popular methods to train single and multi-agent autonomous systems under user-specified and state-based reward functions, applying these methods to satisfy trajectory-level task objectives is a challenging problem. Our first contribution is the use of weighted automata to specify trajectory-level objectives, such that, maximal paths induced in the weighted automaton correspond to desired trajectory-level behaviors. We show how weighted automata-based specifications go beyond timeliness properties focused on deadlines to performance properties such as expeditiousness. Our second contribution is the use of evolutionary game theory (EGT) principles to train homogeneous multi-agent teams targeting homogeneous task objectives. We show how shared experiences of agents and EGT-based policy updates allow us to outperform state-of-the-art reinforcement learning (RL) methods in minimizing path length by nearly 30\% in large spaces. We also show that our algorithm is computationally faster than deep RL methods by at least an order of magnitude. Additionally our results indicate that it scales better with an increase in the number of agents as compared to other methods.
Data-Driven Reachability Analysis of Stochastic Dynamical Systems with Conformal Inference
Sep 17, 2023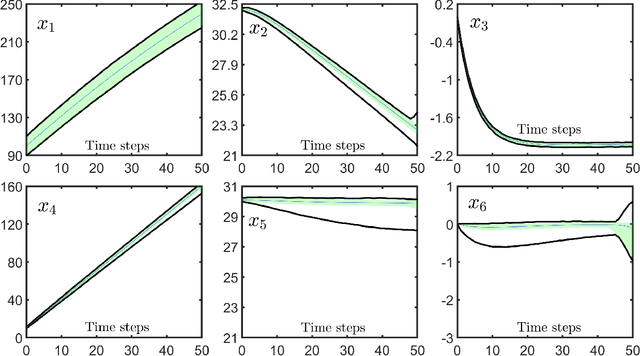
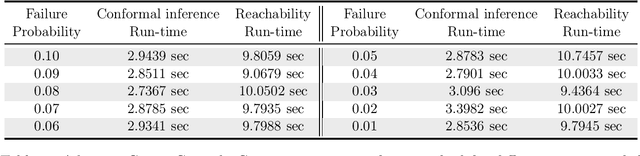
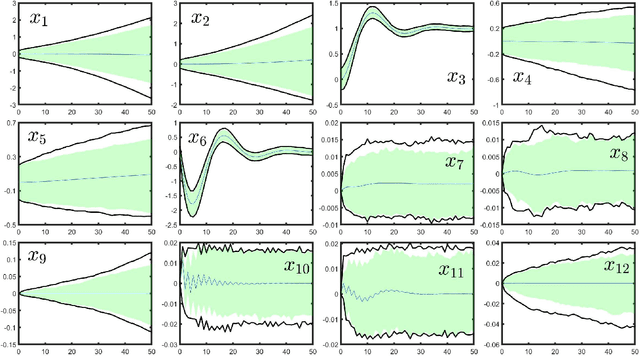
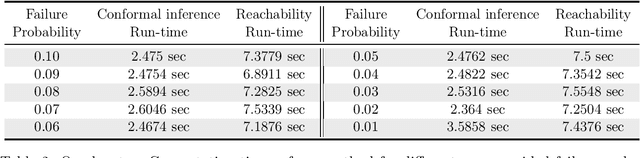
We consider data-driven reachability analysis of discrete-time stochastic dynamical systems using conformal inference. We assume that we are not provided with a symbolic representation of the stochastic system, but instead have access to a dataset of $K$-step trajectories. The reachability problem is to construct a probabilistic flowpipe such that the probability that a $K$-step trajectory can violate the bounds of the flowpipe does not exceed a user-specified failure probability threshold. The key ideas in this paper are: (1) to learn a surrogate predictor model from data, (2) to perform reachability analysis using the surrogate model, and (3) to quantify the surrogate model's incurred error using conformal inference in order to give probabilistic reachability guarantees. We focus on learning-enabled control systems with complex closed-loop dynamics that are difficult to model symbolically, but where state transition pairs can be queried, e.g., using a simulator. We demonstrate the applicability of our method on examples from the domain of learning-enabled cyber-physical systems.
Conformal Prediction for STL Runtime Verification
Nov 03, 2022



We are interested in predicting failures of cyber-physical systems during their operation. Particularly, we consider stochastic systems and signal temporal logic specifications, and we want to calculate the probability that the current system trajectory violates the specification. The paper presents two predictive runtime verification algorithms that predict future system states from the current observed system trajectory. As these predictions may not be accurate, we construct prediction regions that quantify prediction uncertainty by using conformal prediction, a statistical tool for uncertainty quantification. Our first algorithm directly constructs a prediction region for the satisfaction measure of the specification so that we can predict specification violations with a desired confidence. The second algorithm constructs prediction regions for future system states first, and uses these to obtain a prediction region for the satisfaction measure. To the best of our knowledge, these are the first formal guarantees for a predictive runtime verification algorithm that applies to widely used trajectory predictors such as RNNs and LSTMs, while being computationally simple and making no assumptions on the underlying distribution. We present numerical experiments of an F-16 aircraft and a self-driving car.
Risk-Awareness in Learning Neural Controllers for Temporal Logic Objectives
Oct 14, 2022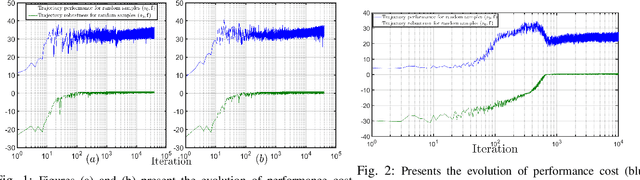
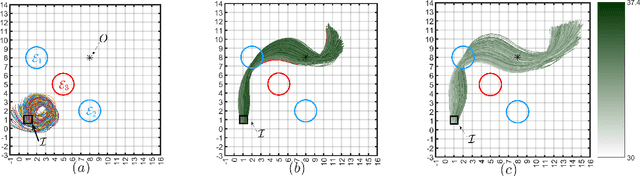
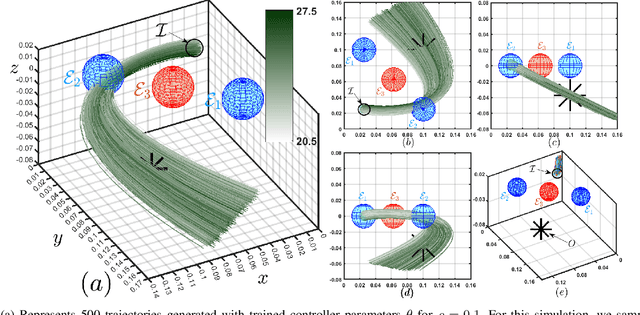
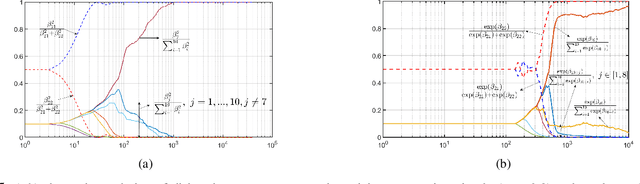
In this paper, we consider the problem of synthesizing a controller in the presence of uncertainty such that the resulting closed-loop system satisfies certain hard constraints while optimizing certain (soft) performance objectives. We assume that the hard constraints encoding safety or mission-critical task objectives are expressed using Signal Temporal Logic (STL), while performance is quantified using standard cost functions on system trajectories. In order to prioritize the satisfaction of the hard STL constraints, we utilize the framework of control barrier functions (CBFs) and algorithmically obtain CBFs for STL objectives. We assume that the controllers are modeled using neural networks (NNs) and provide an optimization algorithm to learn the optimal parameters for the NN controller that optimize the performance at a user-specified robustness margin for the safety specifications. We use the formalism of risk measures to evaluate the risk incurred by the trade-off between robustness margin of the system and its performance. We demonstrate the efficacy of our approach on well-known difficult examples for nonlinear control such as a quad-rotor and a unicycle, where the mission objectives for each system include hard timing constraints and safety objectives.
Domain Generalization for Activity Recognition via Adaptive Feature Fusion
Jul 21, 2022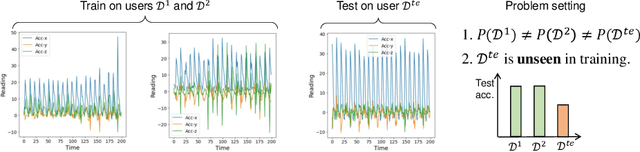

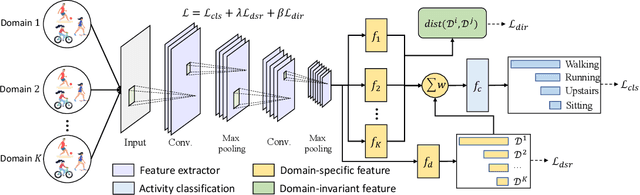

Human activity recognition requires the efforts to build a generalizable model using the training datasets with the hope to achieve good performance in test datasets. However, in real applications, the training and testing datasets may have totally different distributions due to various reasons such as different body shapes, acting styles, and habits, damaging the model's generalization performance. While such a distribution gap can be reduced by existing domain adaptation approaches, they typically assume that the test data can be accessed in the training stage, which is not realistic. In this paper, we consider a more practical and challenging scenario: domain-generalized activity recognition (DGAR) where the test dataset \emph{cannot} be accessed during training. To this end, we propose \emph{Adaptive Feature Fusion for Activity Recognition~(AFFAR)}, a domain generalization approach that learns to fuse the domain-invariant and domain-specific representations to improve the model's generalization performance. AFFAR takes the best of both worlds where domain-invariant representations enhance the transferability across domains and domain-specific representations leverage the model discrimination power from each domain. Extensive experiments on three public HAR datasets show its effectiveness. Furthermore, we apply AFFAR to a real application, i.e., the diagnosis of Children's Attention Deficit Hyperactivity Disorder~(ADHD), which also demonstrates the superiority of our approach.
MetaFed: Federated Learning among Federations with Cyclic Knowledge Distillation for Personalized Healthcare
Jun 17, 2022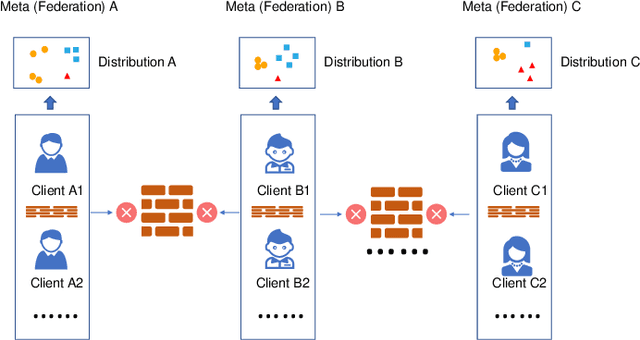
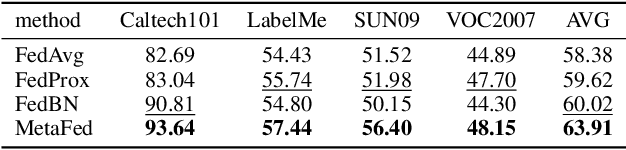
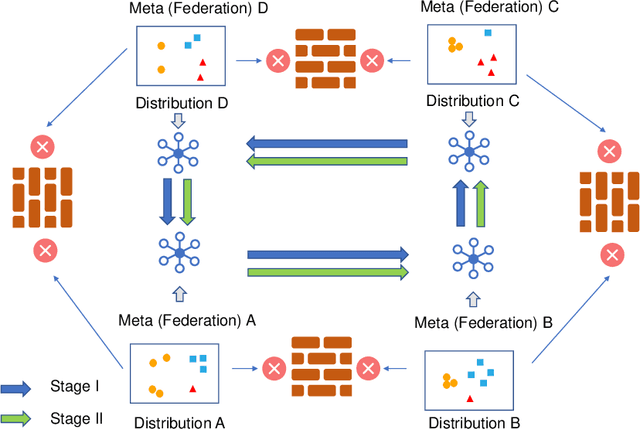

Federated learning has attracted increasing attention to building models without accessing the raw user data, especially in healthcare. In real applications, different federations can seldom work together due to possible reasons such as data heterogeneity and distrust/inexistence of the central server. In this paper, we propose a novel framework called MetaFed to facilitate trustworthy FL between different federations. MetaFed obtains a personalized model for each federation without a central server via the proposed Cyclic Knowledge Distillation. Specifically, MetaFed treats each federation as a meta distribution and aggregates knowledge of each federation in a cyclic manner. The training is split into two parts: common knowledge accumulation and personalization. Comprehensive experiments on three benchmarks demonstrate that MetaFed without a server achieves better accuracy compared to state-of-the-art methods (e.g., 10%+ accuracy improvement compared to the baseline for PAMAP2) with fewer communication costs.
Semantic-Discriminative Mixup for Generalizable Sensor-based Cross-domain Activity Recognition
Jun 14, 2022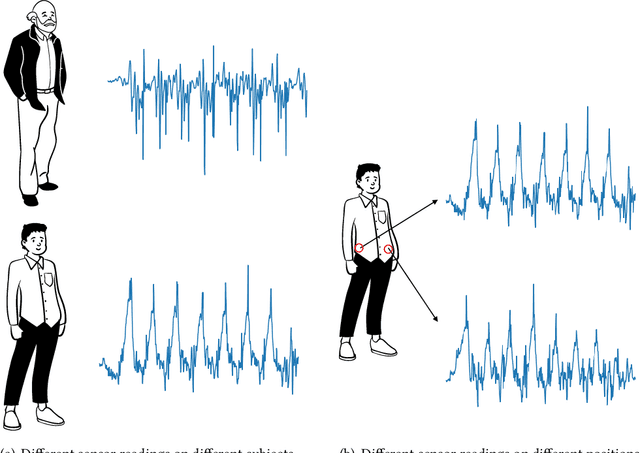
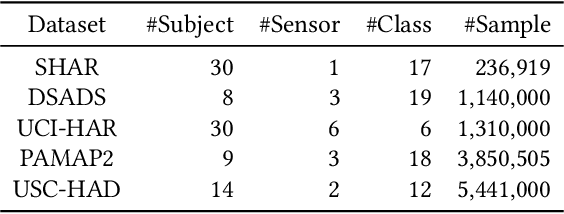
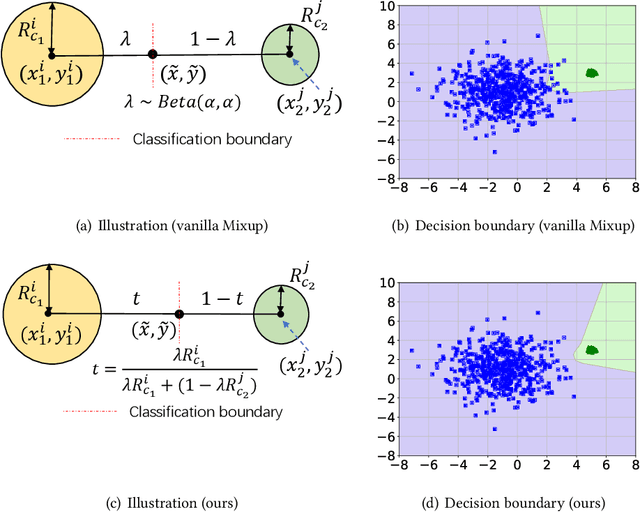
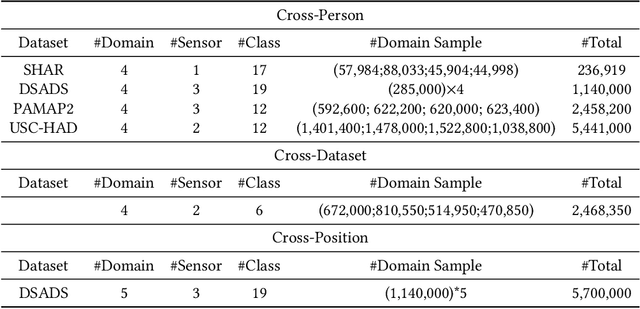
It is expensive and time-consuming to collect sufficient labeled data to build human activity recognition (HAR) models. Training on existing data often makes the model biased towards the distribution of the training data, thus the model might perform terribly on test data with different distributions. Although existing efforts on transfer learning and domain adaptation try to solve the above problem, they still need access to unlabeled data on the target domain, which may not be possible in real scenarios. Few works pay attention to training a model that can generalize well to unseen target domains for HAR. In this paper, we propose a novel method called Semantic-Discriminative Mixup (SDMix) for generalizable cross-domain HAR. Firstly, we introduce semantic-aware Mixup that considers the activity semantic ranges to overcome the semantic inconsistency brought by domain differences. Secondly, we introduce the large margin loss to enhance the discrimination of Mixup to prevent misclassification brought by noisy virtual labels. Comprehensive generalization experiments on five public datasets demonstrate that our SDMix substantially outperforms the state-of-the-art approaches with 6% average accuracy improvement on cross-person, cross-dataset, and cross-position HAR.
Federated Learning with Adaptive Batchnorm for Personalized Healthcare
Dec 01, 2021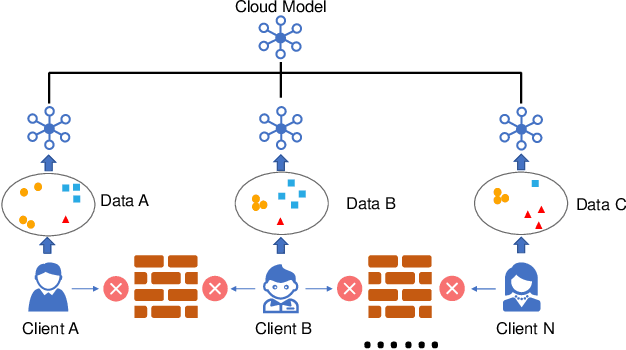

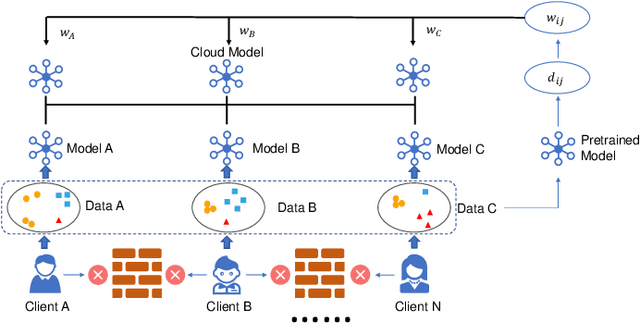

There is a growing interest in applying machine learning techniques for healthcare. Recently, federated machine learning (FL) is gaining popularity since it allows researchers to train powerful models without compromising data privacy and security. However, the performance of existing FL approaches often deteriorates when encountering non-iid situations where there exist distribution gaps among clients, and few previous efforts focus on personalization in healthcare. In this article, we propose AdaFed to tackle domain shifts and obtain personalized models for local clients. AdaFed learns the similarity between clients via the statistics of the batch normalization layers while preserving the specificity of each client with different local batch normalization. Comprehensive experiments on five healthcare benchmarks demonstrate that AdaFed achieves better accuracy compared to state-of-the-art methods (e.g., \textbf{10}\%+ accuracy improvement for PAMAP2) with faster convergence speed.