 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Task Shield: Enforcing Task Alignment to Defend Against Indirect Prompt Injection in LLM Agents
Dec 21, 2024Large Language Model (LLM) agents are increasingly being deployed as conversational assistants capable of performing complex real-world tasks through tool integration. This enhanced ability to interact with external systems and process various data sources, while powerful, introduces significant security vulnerabilities. In particular, indirect prompt injection attacks pose a critical threat, where malicious instructions embedded within external data sources can manipulate agents to deviate from user intentions. While existing defenses based on rule constraints, source spotlighting, and authentication protocols show promise, they struggle to maintain robust security while preserving task functionality. We propose a novel and orthogonal perspective that reframes agent security from preventing harmful actions to ensuring task alignment, requiring every agent action to serve user objectives. Based on this insight, we develop Task Shield, a test-time defense mechanism that systematically verifies whether each instruction and tool call contributes to user-specified goals. Through experiments on the AgentDojo benchmark, we demonstrate that Task Shield reduces attack success rates (2.07\%) while maintaining high task utility (69.79\%) on GPT-4o.
Can Large Language Model Agents Simulate Human Trust Behaviors?
Feb 07, 2024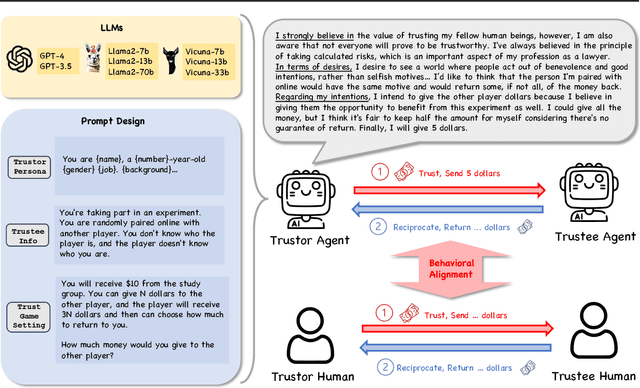
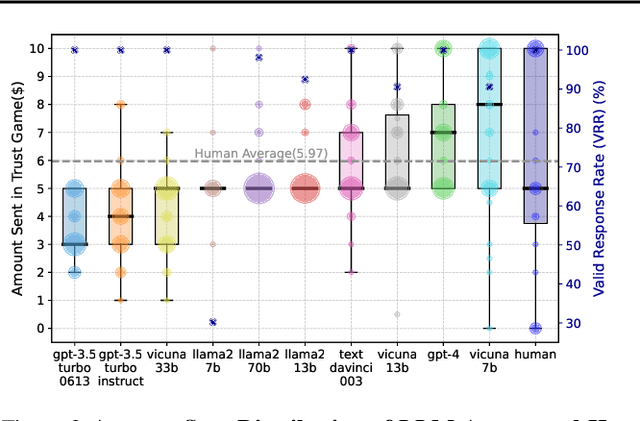
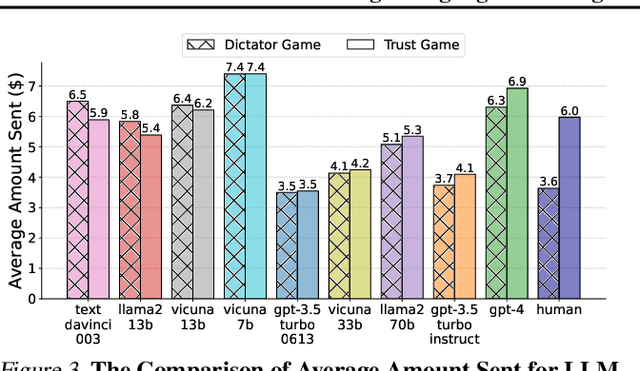
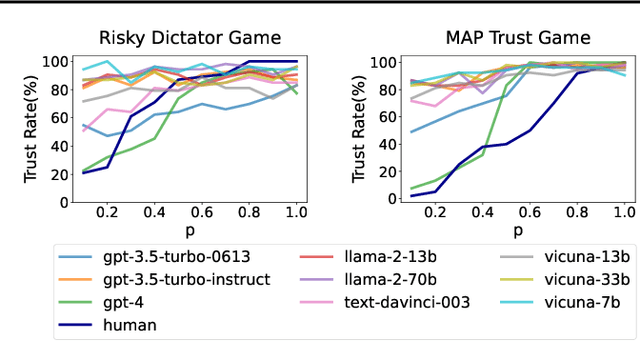
Large Language Model (LLM) agents have been increasingly adopted as simulation tools to model humans in applications such as social science. However, one fundamental question remains: can LLM agents really simulate human behaviors? In this paper, we focus on one of the most critical behaviors in human interactions, trust, and aim to investigate whether or not LLM agents can simulate human trust behaviors. We first find that LLM agents generally exhibit trust behaviors, referred to as agent trust, under the framework of Trust Games, which are widely recognized in behavioral economics. Then, we discover that LLM agents can have high behavioral alignment with humans regarding trust behaviors, indicating the feasibility to simulate human trust behaviors with LLM agents. In addition, we probe into the biases in agent trust and the differences in agent trust towards agents and humans. We also explore the intrinsic properties of agent trust under conditions including advanced reasoning strategies and external manipulations. We further offer important implications for various scenarios where trust is paramount. Our study represents a significant step in understanding the behaviors of LLM agents and the LLM-human analogy.
An Empirical Study on Challenging Math Problem Solving with GPT-4
Jun 08, 2023Employing Large Language Models (LLMs) to address mathematical problems is an intriguing research endeavor, considering the abundance of math problems expressed in natural language across numerous science and engineering fields. While several prior works have investigated solving elementary mathematics using LLMs, this work explores the frontier of using GPT-4 for solving more complex and challenging math problems. We evaluate various ways of using GPT-4. Some of them are adapted from existing work, and one is MathChat, a conversational problem-solving framework newly proposed in this work. We perform the evaluation on difficult high school competition problems from the MATH dataset, which shows the advantage of the proposed conversational approach.
Uncovering Adversarial Risks of Test-Time Adaptation
Feb 04, 2023



Recently, test-time adaptation (TTA) has been proposed as a promising solution for addressing distribution shifts. It allows a base model to adapt to an unforeseen distribution during inference by leveraging the information from the batch of (unlabeled) test data. However, we uncover a novel security vulnerability of TTA based on the insight that predictions on benign samples can be impacted by malicious samples in the same batch. To exploit this vulnerability, we propose Distribution Invading Attack (DIA), which injects a small fraction of malicious data into the test batch. DIA causes models using TTA to misclassify benign and unperturbed test data, providing an entirely new capability for adversaries that is infeasible in canonical machine learning pipelines. Through comprehensive evaluations, we demonstrate the high effectiveness of our attack on multiple benchmarks across six TTA methods. In response, we investigate two countermeasures to robustify the existing insecure TTA implementations, following the principle of "security by design". Together, we hope our findings can make the community aware of the utility-security tradeoffs in deploying TTA and provide valuable insights for developing robust TTA approaches.
RoCourseNet: Distributionally Robust Training of a Prediction Aware Recourse Model
Jun 01, 2022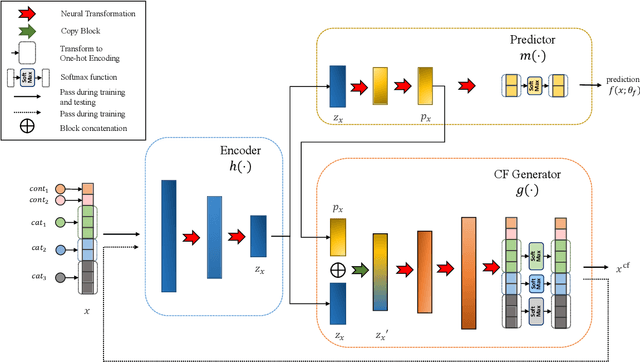
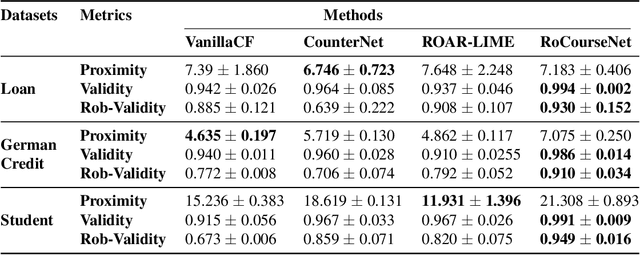
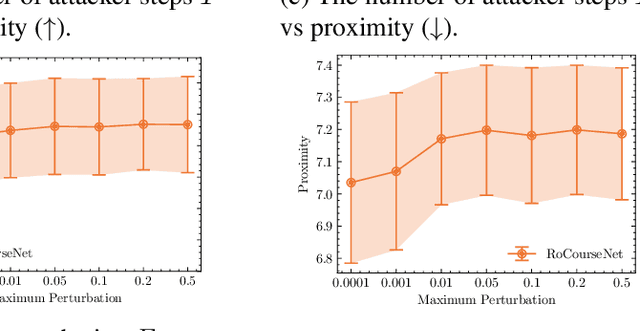
Counterfactual (CF) explanations for machine learning (ML) models are preferred by end-users, as they explain the predictions of ML models by providing a recourse case to individuals who are adversely impacted by predicted outcomes. Existing CF explanation methods generate recourses under the assumption that the underlying target ML model remains stationary over time. However, due to commonly occurring distributional shifts in training data, ML models constantly get updated in practice, which might render previously generated recourses invalid and diminish end-users trust in our algorithmic framework. To address this problem, we propose RoCourseNet, a training framework that jointly optimizes for predictions and robust recourses to future data shifts. We have three main contributions: (i) We propose a novel virtual data shift (VDS) algorithm to find worst-case shifted ML models by explicitly considering the worst-case data shift in the training dataset. (ii) We leverage adversarial training to solve a novel tri-level optimization problem inside RoCourseNet, which simultaneously generates predictions and corresponding robust recourses. (iii) Finally, we evaluate RoCourseNet's performance on three real-world datasets and show that RoCourseNet outperforms state-of-the-art baselines by 10% in generating robust CF explanations.