 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Challenging Math Problem Solving with GPT-4
Jun 08, 2023Employing Large Language Models (LLMs) to address mathematical problems is an intriguing research endeavor, considering the abundance of math problems expressed in natural language across numerous science and engineering fields. While several prior works have investigated solving elementary mathematics using LLMs, this work explores the frontier of using GPT-4 for solving more complex and challenging math problems. We evaluate various ways of using GPT-4. Some of them are adapted from existing work, and one is MathChat, a conversational problem-solving framework newly proposed in this work. We perform the evaluation on difficult high school competition problems from the MATH dataset, which shows the advantage of the proposed conversational approach.
$\ell_2$-norm Flow Diffusion in Near-Linear Time
Jun 03, 2021
Diffusion is a fundamental graph procedure and has been a basic building block in a wide range of theoretical and empirical applications such as graph partitioning and semi-supervised learning on graphs. In this paper, we study computationally efficient diffusion primitives beyond random walk. We design an $\widetilde{O}(m)$-time randomized algorithm for the $\ell_2$-norm flow diffusion problem, a recently proposed diffusion model based on network flow with demonstrated graph clustering related applications both in theory and in practice. Examples include finding locally-biased low conductance cuts. Using a known connection between the optimal dual solution of the flow diffusion problem and the local cut structure, our algorithm gives an alternative approach for finding such cuts in nearly linear time. From a technical point of view, our algorithm contributes a novel way of dealing with inequality constraints in graph optimization problems. It adapts the high-level algorithmic framework of nearly linear time Laplacian system solvers, but requires several new tools: vertex elimination under constraints, a new family of graph ultra-sparsifiers, and accelerated proximal gradient methods with inexact proximal mapping computation.
Concentration Bounds for Co-occurrence Matrices of Markov Chains
Aug 06, 2020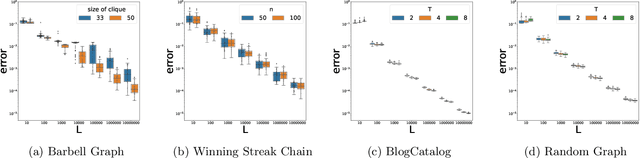
Co-occurrence statistics for sequential data are common and important data signals in machine learning, which provide rich correlation and clustering information about the underlying object space. We give the first bound on the convergence rate of estimating the co-occurrence matrix of a regular (aperiodic and irreducible) finite Markov chain from a single random trajectory. Our work is motivated by the analysis of a well-known graph learning algorithm DeepWalk by [Qiu et al. WSDM '18], who study the convergence (in probability) of co-occurrence matrix from random walk on undirected graphs in the limit, but left the convergence rate an open problem. We prove a Chernoff-type bound for sums of matrix-valued random variables sampled via an ergodic Markov chain, generalizing the regular undirected graph case studied by [Garg et al. STOC '18]. Using the Chernoff-type bound, we show that given a regular Markov chain with $n$ states and mixing time $\tau$, we need a trajectory of length $O(\tau (\log{(n)}+\log{(\tau)})/\epsilon^2)$ to achieve an estimator of the co-occurrence matrix with error bound $\epsilon$. We conduct several experiments and the experimental results are consistent with the exponentially fast convergence rate from theoretical analysis. Our result gives the first sample complexity analysis in graph representation learning.
Faster Graph Embeddings via Coarsening
Jul 06, 2020
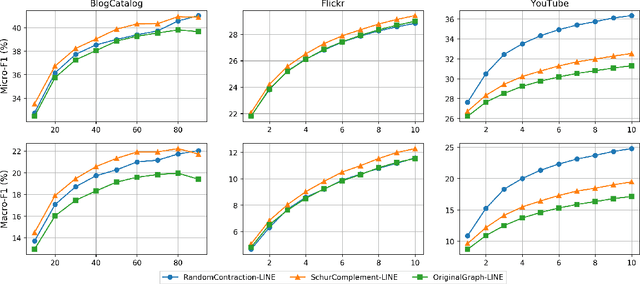
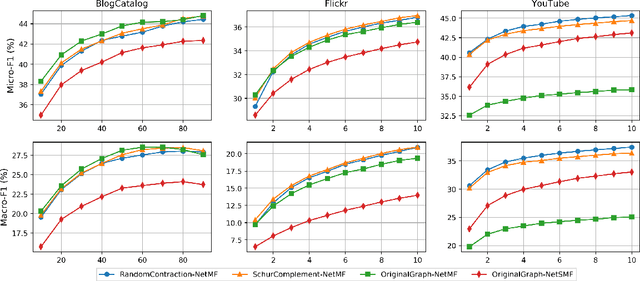
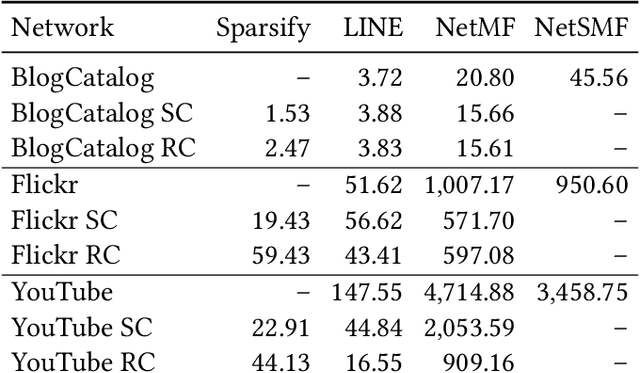
Graph embeddings are a ubiquitous tool for machine learning tasks, such as node classification and link prediction, on graph-structured data. However, computing the embeddings for large-scale graphs is prohibitively inefficient even if we are interested only in a small subset of relevant vertices. To address this, we present an efficient graph coarsening approach, based on Schur complements, for computing the embedding of the relevant vertices. We prove that these embeddings are preserved exactly by the Schur complement graph that is obtained via Gaussian elimination on the non-relevant vertices. As computing Schur complements is expensive, we give a nearly-linear time algorithm that generates a coarsened graph on the relevant vertices that provably matches the Schur complement in expectation in each iteration. Our experiments involving prediction tasks on graphs demonstrate that computing embeddings on the coarsened graph, rather than the entire graph, leads to significant time savings without sacrificing accuracy.
* 18 pages, 2 figures
A Study of Performance of Optimal Transport
May 03, 2020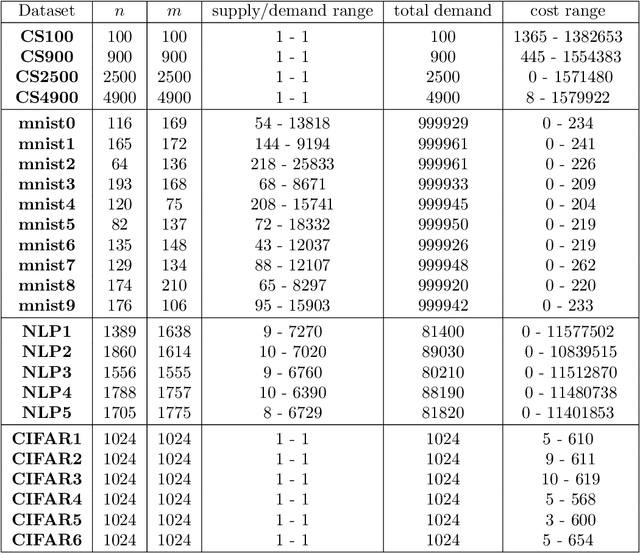
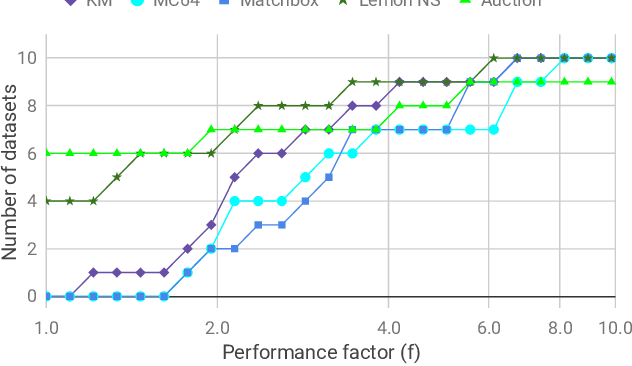
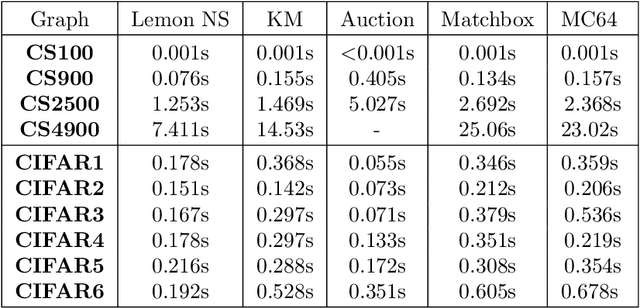
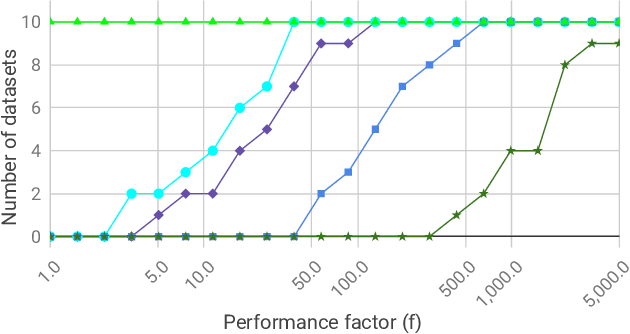
We investigate the problem of efficiently computing optimal transport (OT) distances, which is equivalent to the node-capacitated minimum cost maximum flow problem in a bipartite graph. We compare runtimes in computing OT distances on data from several domains, such as synthetic data of geometric shapes, embeddings of tokens in documents, and pixels in images. We show that in practice, combinatorial methods such as network simplex and augmenting path based algorithms can consistently outperform numerical matrix-scaling based methods such as Sinkhorn [Cuturi'13] and Greenkhorn [Altschuler et al'17], even in low accuracy regimes, with up to orders of magnitude speedups. Lastly, we present a new combinatorial algorithm that improves upon the classical Kuhn-Munkres algorithm.
Fast, Provably convergent IRLS Algorithm for p-norm Linear Regression
Jul 16, 2019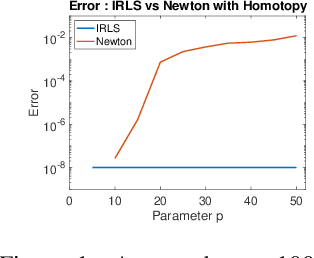
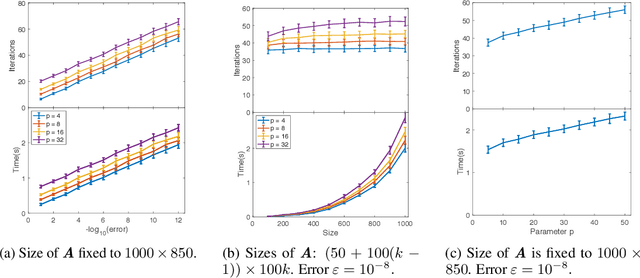
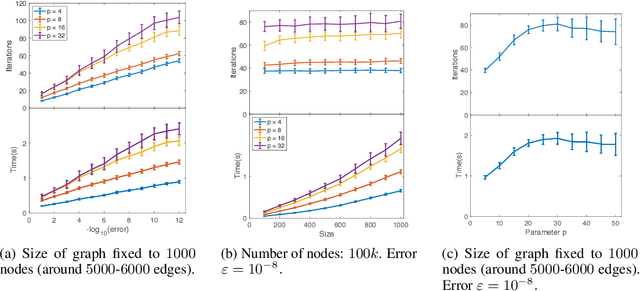

Linear regression in $\ell_p$-norm is a canonical optimization problem that arises in several applications, including sparse recovery, semi-supervised learning, and signal processing. Generic convex optimization algorithms for solving $\ell_p$-regression are slow in practice. Iteratively Reweighted Least Squares (IRLS) is an easy to implement family of algorithms for solving these problems that has been studied for over 50 years. However, these algorithms often diverge for p > 3, and since the work of Osborne (1985), it has been an open problem whether there is an IRLS algorithm that is guaranteed to converge rapidly for p > 3. We propose p-IRLS, the first IRLS algorithm that provably converges geometrically for any $p \in [2,\infty).$ Our algorithm is simple to implement and is guaranteed to find a $(1+\varepsilon)$-approximate solution in $O(p^{3.5} m^{\frac{p-2}{2(p-1)}} \log \frac{m}{\varepsilon}) \le O_p(\sqrt{m} \log \frac{m}{\varepsilon} )$ iterations. Our experiments demonstrate that it performs even better than our theoretical bounds, beats the standard Matlab/CVX implementation for solving these problems by 10--50x, and is the fastest among available implementations in the high-accuracy regime.
Higher-Order Accelerated Methods for Faster Non-Smooth Optimization
Jun 04, 2019We provide improved convergence rates for various \emph{non-smooth} optimization problems via higher-order accelerated methods. In the case of $\ell_\infty$ regression, we achieves an $O(\epsilon^{-4/5})$ iteration complexity, breaking the $O(\epsilon^{-1})$ barrier so far present for previous methods. We arrive at a similar rate for the problem of $\ell_1$-SVM, going beyond what is attainable by first-order methods with prox-oracle access for non-smooth non-strongly convex problems. We further show how to achieve even faster rates by introducing higher-order regularization. Our results rely on recent advances in near-optimal accelerated methods for higher-order smooth convex optimization. In particular, we extend Nesterov's smoothing technique to show that the standard softmax approximation is not only smooth in the usual sense, but also \emph{higher-order} smooth. With this observation in hand, we provide the first example of higher-order acceleration techniques yielding faster rates for \emph{non-smooth} optimization, to the best of our knowledge.
Iterative Refinement for $\ell_p$-norm Regression
Jan 21, 2019We give improved algorithms for the $\ell_{p}$-regression problem, $\min_{x} \|x\|_{p}$ such that $A x=b,$ for all $p \in (1,2) \cup (2,\infty).$ Our algorithms obtain a high accuracy solution in $\tilde{O}_{p}(m^{\frac{|p-2|}{2p + |p-2|}}) \le \tilde{O}_{p}(m^{\frac{1}{3}})$ iterations, where each iteration requires solving an $m \times m$ linear system, $m$ being the dimension of the ambient space. By maintaining an approximate inverse of the linear systems that we solve in each iteration, we give algorithms for solving $\ell_{p}$-regression to $1 / \text{poly}(n)$ accuracy that run in time $\tilde{O}_p(m^{\max\{\omega, 7/3\}}),$ where $\omega$ is the matrix multiplication constant. For the current best value of $\omega > 2.37$, we can thus solve $\ell_{p}$ regression as fast as $\ell_{2}$ regression, for all constant $p$ bounded away from $1.$ Our algorithms can be combined with fast graph Laplacian linear equation solvers to give minimum $\ell_{p}$-norm flow / voltage solutions to $1 / \text{poly}(n)$ accuracy on an undirected graph with $m$ edges in $\tilde{O}_{p}(m^{1 + \frac{|p-2|}{2p + |p-2|}}) \le \tilde{O}_{p}(m^{\frac{4}{3}})$ time. For sparse graphs and for matrices with similar dimensions, our iteration counts and running times improve on the $p$-norm regression algorithm by [Bubeck-Cohen-Lee-Li STOC`18] and general-purpose convex optimization algorithms. At the core of our algorithms is an iterative refinement scheme for $\ell_{p}$-norms, using the smoothed $\ell_{p}$-norms introduced in the work of Bubeck et al. Given an initial solution, we construct a problem that seeks to minimize a quadratically-smoothed $\ell_{p}$ norm over a subspace, such that a crude solution to this problem allows us to improve the initial solution by a constant factor, leading to algorithms with fast convergence.
Partitioning Well-Clustered Graphs: Spectral Clustering Works!
Jan 31, 2017
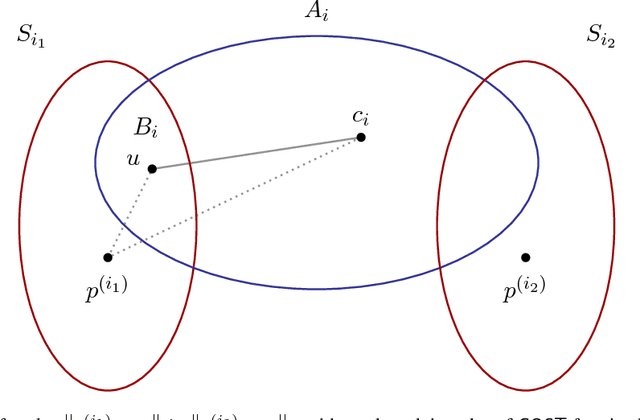
In this paper we study variants of the widely used spectral clustering that partitions a graph into k clusters by (1) embedding the vertices of a graph into a low-dimensional space using the bottom eigenvectors of the Laplacian matrix, and (2) grouping the embedded points into k clusters via k-means algorithms. We show that, for a wide class of graphs, spectral clustering gives a good approximation of the optimal clustering. While this approach was proposed in the early 1990s and has comprehensive applications, prior to our work similar results were known only for graphs generated from stochastic models. We also give a nearly-linear time algorithm for partitioning well-clustered graphs based on computing a matrix exponential and approximate nearest neighbor data structures.
Spectral Sparsification of Random-Walk Matrix Polynomials
Feb 12, 2015We consider a fundamental algorithmic question in spectral graph theory: Compute a spectral sparsifier of random-walk matrix-polynomial $$L_\alpha(G)=D-\sum_{r=1}^d\alpha_rD(D^{-1}A)^r$$ where $A$ is the adjacency matrix of a weighted, undirected graph, $D$ is the diagonal matrix of weighted degrees, and $\alpha=(\alpha_1...\alpha_d)$ are nonnegative coefficients with $\sum_{r=1}^d\alpha_r=1$. Recall that $D^{-1}A$ is the transition matrix of random walks on the graph. The sparsification of $L_\alpha(G)$ appears to be algorithmically challenging as the matrix power $(D^{-1}A)^r$ is defined by all paths of length $r$, whose precise calculation would be prohibitively expensive. In this paper, we develop the first nearly linear time algorithm for this sparsification problem: For any $G$ with $n$ vertices and $m$ edges, $d$ coefficients $\alpha$, and $\epsilon > 0$, our algorithm runs in time $O(d^2m\log^2n/\epsilon^{2})$ to construct a Laplacian matrix $\tilde{L}=D-\tilde{A}$ with $O(n\log n/\epsilon^{2})$ non-zeros such that $\tilde{L}\approx_{\epsilon}L_\alpha(G)$. Matrix polynomials arise in mathematical analysis of matrix functions as well as numerical solutions of matrix equations. Our work is particularly motivated by the algorithmic problems for speeding up the classic Newton's method in applications such as computing the inverse square-root of the precision matrix of a Gaussian random field, as well as computing the $q$th-root transition (for $q\geq1$) in a time-reversible Markov model. The key algorithmic step for both applications is the construction of a spectral sparsifier of a constant degree random-walk matrix-polynomials introduced by Newton's method. Our algorithm can also be used to build efficient data structures for effective resistances for multi-step time-reversible Markov models, and we anticipate that it could be useful for other tasks in network analysis.