 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic algorithms for k-center on graphs
Jul 28, 2023In this paper we give the first efficient algorithms for the $k$-center problem on dynamic graphs undergoing edge updates. In this problem, the goal is to partition the input into $k$ sets by choosing $k$ centers such that the maximum distance from any data point to the closest center is minimized. It is known that it is NP-hard to get a better than $2$ approximation for this problem. While in many applications the input may naturally be modeled as a graph, all prior works on $k$-center problem in dynamic settings are on metrics. In this paper, we give a deterministic decremental $(2+\epsilon)$-approximation algorithm and a randomized incremental $(4+\epsilon)$-approximation algorithm, both with amortized update time $kn^{o(1)}$ for weighted graphs. Moreover, we show a reduction that leads to a fully dynamic $(2+\epsilon)$-approximation algorithm for the $k$-center problem, with worst-case update time that is within a factor $k$ of the state-of-the-art upper bound for maintaining $(1+\epsilon)$-approximate single-source distances in graphs. Matching this bound is a natural goalpost because the approximate distances of each vertex to its center can be used to maintain a $(2+\epsilon)$-approximation of the graph diameter and the fastest known algorithms for such a diameter approximation also rely on maintaining approximate single-source distances.
Local Algorithms for Estimating Effective Resistance
Jun 07, 2021
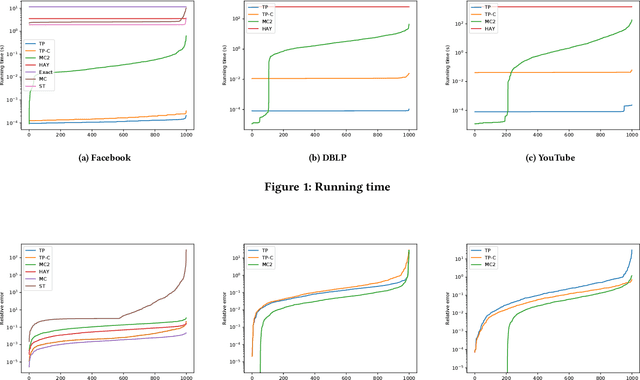

Effective resistance is an important metric that measures the similarity of two vertices in a graph. It has found applications in graph clustering, recommendation systems and network reliability, among others. In spite of the importance of the effective resistances, we still lack efficient algorithms to exactly compute or approximate them on massive graphs. In this work, we design several \emph{local algorithms} for estimating effective resistances, which are algorithms that only read a small portion of the input while still having provable performance guarantees. To illustrate, our main algorithm approximates the effective resistance between any vertex pair $s,t$ with an arbitrarily small additive error $\varepsilon$ in time $O(\mathrm{poly}(\log n/\varepsilon))$, whenever the underlying graph has bounded mixing time. We perform an extensive empirical study on several benchmark datasets, validating the performance of our algorithms.
Faster Graph Embeddings via Coarsening
Jul 06, 2020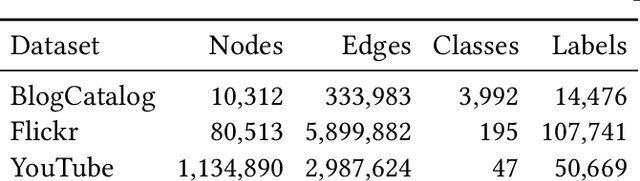
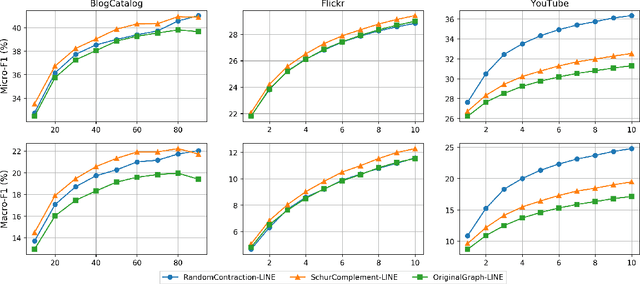
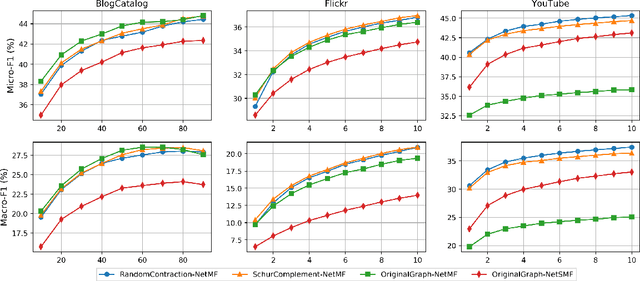
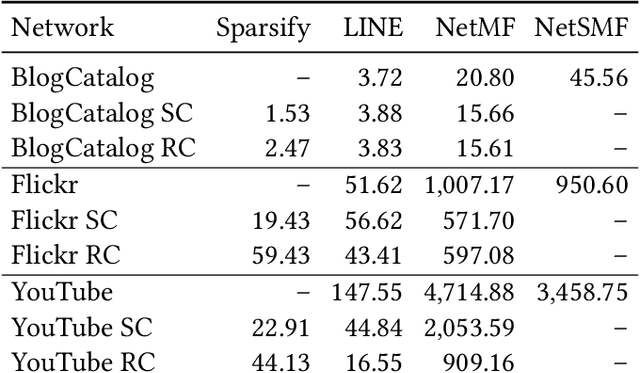
Graph embeddings are a ubiquitous tool for machine learning tasks, such as node classification and link prediction, on graph-structured data. However, computing the embeddings for large-scale graphs is prohibitively inefficient even if we are interested only in a small subset of relevant vertices. To address this, we present an efficient graph coarsening approach, based on Schur complements, for computing the embedding of the relevant vertices. We prove that these embeddings are preserved exactly by the Schur complement graph that is obtained via Gaussian elimination on the non-relevant vertices. As computing Schur complements is expensive, we give a nearly-linear time algorithm that generates a coarsened graph on the relevant vertices that provably matches the Schur complement in expectation in each iteration. Our experiments involving prediction tasks on graphs demonstrate that computing embeddings on the coarsened graph, rather than the entire graph, leads to significant time savings without sacrificing accuracy.
* 18 pages, 2 figures