 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSublinear-Time Algorithms for Diagonally Dominant Systems and Applications to the Friedkin-Johnsen Model
Sep 16, 2025We study sublinear-time algorithms for solving linear systems $Sz = b$, where $S$ is a diagonally dominant matrix, i.e., $|S_{ii}| \geq \delta + \sum_{j \ne i} |S_{ij}|$ for all $i \in [n]$, for some $\delta \geq 0$. We present randomized algorithms that, for any $u \in [n]$, return an estimate $z_u$ of $z^*_u$ with additive error $\varepsilon$ or $\varepsilon \lVert z^*\rVert_\infty$, where $z^*$ is some solution to $Sz^* = b$, and the algorithm only needs to read a small portion of the input $S$ and $b$. For example, when the additive error is $\varepsilon$ and assuming $\delta>0$, we give an algorithm that runs in time $O\left( \frac{\|b\|_\infty^2 S_{\max}}{\delta^3 \varepsilon^2} \log \frac{\| b \|_\infty}{\delta \varepsilon} \right)$, where $S_{\max} = \max_{i \in [n]} |S_{ii}|$. We also prove a matching lower bound, showing that the linear dependence on $S_{\max}$ is optimal. Unlike previous sublinear-time algorithms, which apply only to symmetric diagonally dominant matrices with non-negative diagonal entries, our algorithm works for general strictly diagonally dominant matrices ($\delta > 0$) and a broader class of non-strictly diagonally dominant matrices $(\delta = 0)$. Our approach is based on analyzing a simple probabilistic recurrence satisfied by the solution. As an application, we obtain an improved sublinear-time algorithm for opinion estimation in the Friedkin--Johnsen model.
A Differentially Private Clustering Algorithm for Well-Clustered Graphs
Mar 21, 2024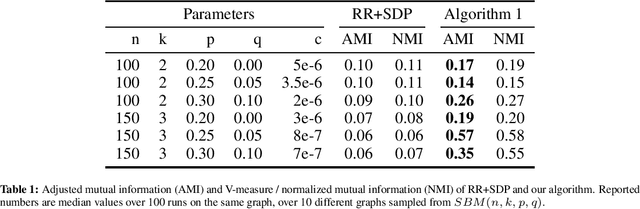
We study differentially private (DP) algorithms for recovering clusters in well-clustered graphs, which are graphs whose vertex set can be partitioned into a small number of sets, each inducing a subgraph of high inner conductance and small outer conductance. Such graphs have widespread application as a benchmark in the theoretical analysis of spectral clustering. We provide an efficient ($\epsilon$,$\delta$)-DP algorithm tailored specifically for such graphs. Our algorithm draws inspiration from the recent work of Chen et al., who developed DP algorithms for recovery of stochastic block models in cases where the graph comprises exactly two nearly-balanced clusters. Our algorithm works for well-clustered graphs with $k$ nearly-balanced clusters, and the misclassification ratio almost matches the one of the best-known non-private algorithms. We conduct experimental evaluations on datasets with known ground truth clusters to substantiate the prowess of our algorithm. We also show that any (pure) $\epsilon$-DP algorithm would result in substantial error.
A Sublinear-Time Spectral Clustering Oracle with Improved Preprocessing Time
Oct 27, 2023



We address the problem of designing a sublinear-time spectral clustering oracle for graphs that exhibit strong clusterability. Such graphs contain $k$ latent clusters, each characterized by a large inner conductance (at least $\varphi$) and a small outer conductance (at most $\varepsilon$). Our aim is to preprocess the graph to enable clustering membership queries, with the key requirement that both preprocessing and query answering should be performed in sublinear time, and the resulting partition should be consistent with a $k$-partition that is close to the ground-truth clustering. Previous oracles have relied on either a $\textrm{poly}(k)\log n$ gap between inner and outer conductances or exponential (in $k/\varepsilon$) preprocessing time. Our algorithm relaxes these assumptions, albeit at the cost of a slightly higher misclassification ratio. We also show that our clustering oracle is robust against a few random edge deletions. To validate our theoretical bounds, we conducted experiments on synthetic networks.
Sublinear-Time Clustering Oracle for Signed Graphs
Jun 28, 2022
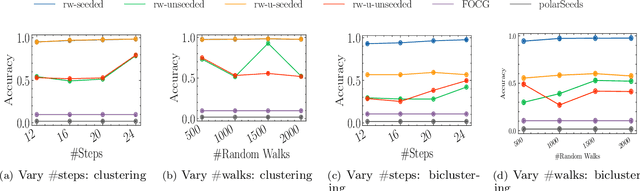
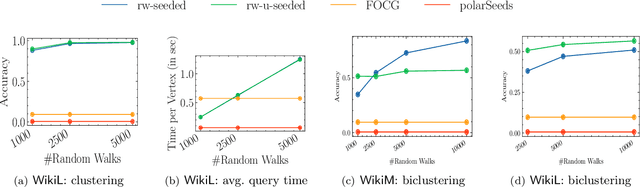
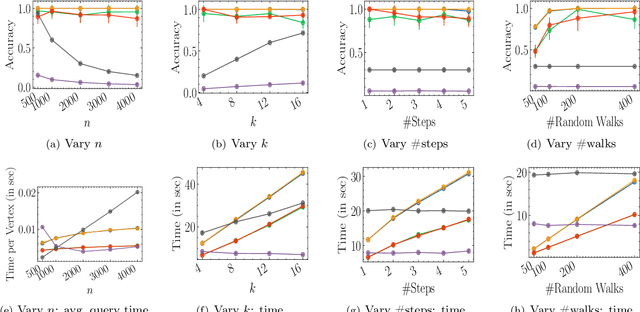
Social networks are often modeled using signed graphs, where vertices correspond to users and edges have a sign that indicates whether an interaction between users was positive or negative. The arising signed graphs typically contain a clear community structure in the sense that the graph can be partitioned into a small number of polarized communities, each defining a sparse cut and indivisible into smaller polarized sub-communities. We provide a local clustering oracle for signed graphs with such a clear community structure, that can answer membership queries, i.e., "Given a vertex $v$, which community does $v$ belong to?", in sublinear time by reading only a small portion of the graph. Formally, when the graph has bounded maximum degree and the number of communities is at most $O(\log n)$, then with $\tilde{O}(\sqrt{n}\operatorname{poly}(1/\varepsilon))$ preprocessing time, our oracle can answer each membership query in $\tilde{O}(\sqrt{n}\operatorname{poly}(1/\varepsilon))$ time, and it correctly classifies a $(1-\varepsilon)$-fraction of vertices w.r.t. a set of hidden planted ground-truth communities. Our oracle is desirable in applications where the clustering information is needed for only a small number of vertices. Previously, such local clustering oracles were only known for unsigned graphs; our generalization to signed graphs requires a number of new ideas and gives a novel spectral analysis of the behavior of random walks with signs. We evaluate our algorithm for constructing such an oracle and answering membership queries on both synthetic and real-world datasets, validating its performance in practice.
Recovering Unbalanced Communities in the Stochastic Block Model With Application to Clustering with a Faulty Oracle
Feb 17, 2022The stochastic block model (SBM) is a fundamental model for studying graph clustering or community detection in networks. It has received great attention in the last decade and the balanced case, i.e., assuming all clusters have large size, has been well studied. However, our understanding of SBM with unbalanced communities (arguably, more relevant in practice) is still very limited. In this paper, we provide a simple SVD-based algorithm for recovering the communities in the SBM with communities of varying sizes. Under the KS-threshold conjecture, the tradeoff between the parameters in our algorithm is nearly optimal up to polylogarithmic factors for a wide range of regimes. As a byproduct, we obtain a time-efficient algorithm with improved query complexity for a clustering problem with a faulty oracle, which improves upon a number of previous work (Mazumdarand Saha [NIPS 2017], Larsen, Mitzenmacher and Tsourakakis [WWW 2020], Peng and Zhang[COLT 2021]). Under the KS-threshold conjecture, the query complexity of our algorithm is nearly optimal up to polylogarithmic factors.
Towards a Query-Optimal and Time-Efficient Algorithm for Clustering with a Faulty Oracle
Jun 18, 2021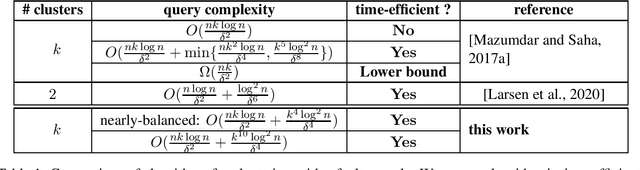
Motivated by applications in crowdsourced entity resolution in database, signed edge prediction in social networks and correlation clustering, Mazumdar and Saha [NIPS 2017] proposed an elegant theoretical model for studying clustering with a faulty oracle. In this model, given a set of $n$ items which belong to $k$ unknown groups (or clusters), our goal is to recover the clusters by asking pairwise queries to an oracle. This oracle can answer the query that ``do items $u$ and $v$ belong to the same cluster?''. However, the answer to each pairwise query errs with probability $\varepsilon$, for some $\varepsilon\in(0,\frac12)$. Mazumdar and Saha provided two algorithms under this model: one algorithm is query-optimal while time-inefficient (i.e., running in quasi-polynomial time), the other is time efficient (i.e., in polynomial time) while query-suboptimal. Larsen, Mitzenmacher and Tsourakakis [WWW 2020] then gave a new time-efficient algorithm for the special case of $2$ clusters, which is query-optimal if the bias $\delta:=1-2\varepsilon$ of the model is large. It was left as an open question whether one can obtain a query-optimal, time-efficient algorithm for the general case of $k$ clusters and other regimes of $\delta$. In this paper, we make progress on the above question and provide a time-efficient algorithm with nearly-optimal query complexity (up to a factor of $O(\log^2 n)$) for all constant $k$ and any $\delta$ in the regime when information-theoretic recovery is possible. Our algorithm is built on a connection to the stochastic block model.
Local Algorithms for Estimating Effective Resistance
Jun 07, 2021
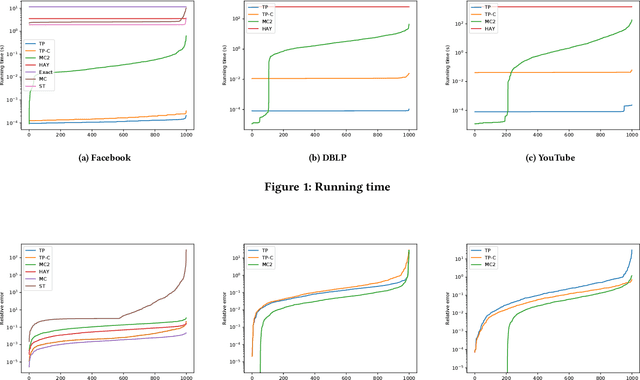

Effective resistance is an important metric that measures the similarity of two vertices in a graph. It has found applications in graph clustering, recommendation systems and network reliability, among others. In spite of the importance of the effective resistances, we still lack efficient algorithms to exactly compute or approximate them on massive graphs. In this work, we design several \emph{local algorithms} for estimating effective resistances, which are algorithms that only read a small portion of the input while still having provable performance guarantees. To illustrate, our main algorithm approximates the effective resistance between any vertex pair $s,t$ with an arbitrarily small additive error $\varepsilon$ in time $O(\mathrm{poly}(\log n/\varepsilon))$, whenever the underlying graph has bounded mixing time. We perform an extensive empirical study on several benchmark datasets, validating the performance of our algorithms.
Time Complexity Analysis of Randomized Search Heuristics for the Dynamic Graph Coloring Problem
May 26, 2021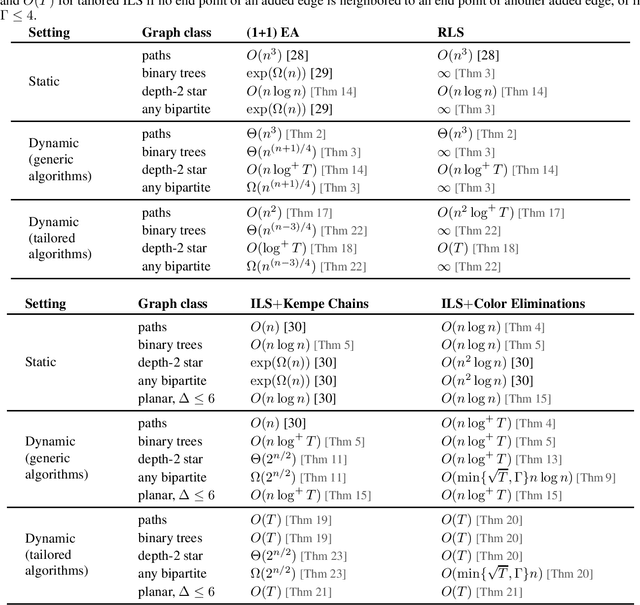
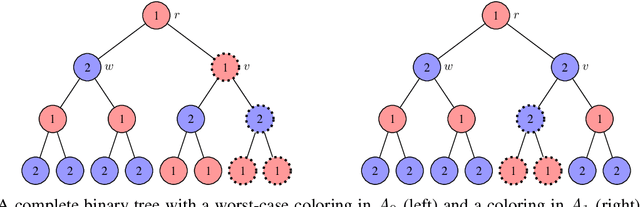
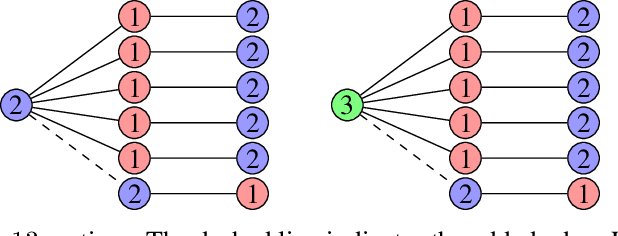

We contribute to the theoretical understanding of randomized search heuristics for dynamic problems. We consider the classical vertex coloring problem on graphs and investigate the dynamic setting where edges are added to the current graph. We then analyze the expected time for randomized search heuristics to recompute high quality solutions. The (1+1)~Evolutionary Algorithm and RLS operate in a setting where the number of colors is bounded and we are minimizing the number of conflicts. Iterated local search algorithms use an unbounded color palette and aim to use the smallest colors and, consequently, the smallest number of colors. We identify classes of bipartite graphs where reoptimization is as hard as or even harder than optimization from scratch, i.e., starting with a random initialization. Even adding a single edge can lead to hard symmetry problems. However, graph classes that are hard for one algorithm turn out to be easy for others. In most cases our bounds show that reoptimization is faster than optimizing from scratch. We further show that tailoring mutation operators to parts of the graph where changes have occurred can significantly reduce the expected reoptimization time. In most settings the expected reoptimization time for such tailored algorithms is linear in the number of added edges. However, tailored algorithms cannot prevent exponential times in settings where the original algorithm is inefficient.
Average Sensitivity of Spectral Clustering
Jun 07, 2020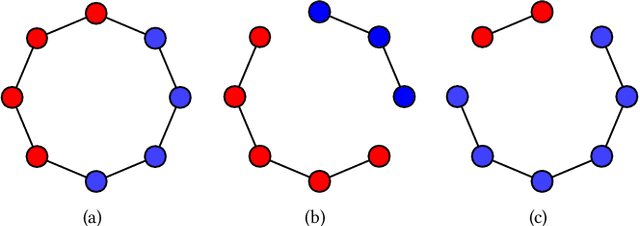

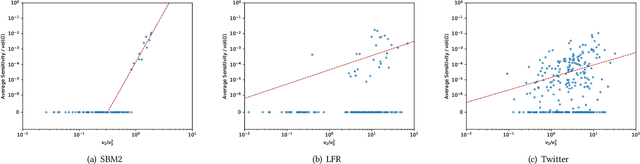

Spectral clustering is one of the most popular clustering methods for finding clusters in a graph, which has found many applications in data mining. However, the input graph in those applications may have many missing edges due to error in measurement, withholding for a privacy reason, or arbitrariness in data conversion. To make reliable and efficient decisions based on spectral clustering, we assess the stability of spectral clustering against edge perturbations in the input graph using the notion of average sensitivity, which is the expected size of the symmetric difference of the output clusters before and after we randomly remove edges. We first prove that the average sensitivity of spectral clustering is proportional to $\lambda_2/\lambda_3^2$, where $\lambda_i$ is the $i$-th smallest eigenvalue of the (normalized) Laplacian. We also prove an analogous bound for $k$-way spectral clustering, which partitions the graph into $k$ clusters. Then, we empirically confirm our theoretical bounds by conducting experiments on synthetic and real networks. Our results suggest that spectral clustering is stable against edge perturbations when there is a cluster structure in the input graph.
More Effective Randomized Search Heuristics for Graph Coloring Through Dynamic Optimization
May 28, 2020
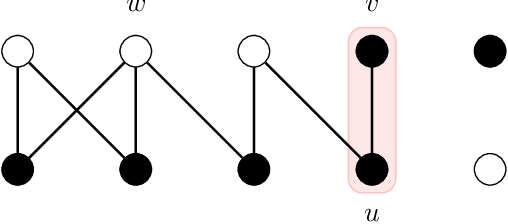
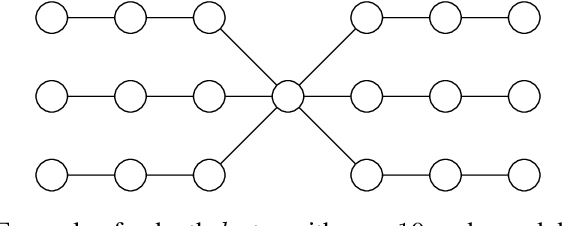

Dynamic optimization problems have gained significant attention in evolutionary computation as evolutionary algorithms (EAs) can easily adapt to changing environments. We show that EAs can solve the graph coloring problem for bipartite graphs more efficiently by using dynamic optimization. In our approach the graph instance is given incrementally such that the EA can reoptimize its coloring when a new edge introduces a conflict. We show that, when edges are inserted in a way that preserves graph connectivity, Randomized Local Search (RLS) efficiently finds a proper 2-coloring for all bipartite graphs. This includes graphs for which RLS and other EAs need exponential expected time in a static optimization scenario. We investigate different ways of building up the graph by popular graph traversals such as breadth-first-search and depth-first-search and analyse the resulting runtime behavior. We further show that offspring populations (e. g. a (1+$\lambda$) RLS) lead to an exponential speedup in $\lambda$. Finally, an island model using 3 islands succeeds in an optimal time of $\Theta(m)$ on every $m$-edge bipartite graph, outperforming offspring populations. This is the first example where an island model guarantees a speedup that is not bounded in the number of islands.