 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Query-Optimal and Time-Efficient Algorithm for Clustering with a Faulty Oracle
Paper and Code
Jun 18, 2021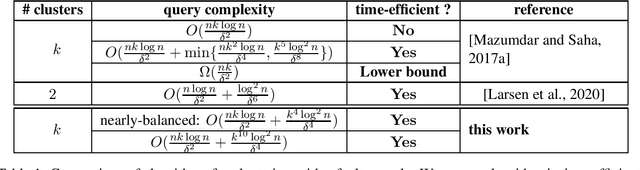
Motivated by applications in crowdsourced entity resolution in database, signed edge prediction in social networks and correlation clustering, Mazumdar and Saha [NIPS 2017] proposed an elegant theoretical model for studying clustering with a faulty oracle. In this model, given a set of $n$ items which belong to $k$ unknown groups (or clusters), our goal is to recover the clusters by asking pairwise queries to an oracle. This oracle can answer the query that ``do items $u$ and $v$ belong to the same cluster?''. However, the answer to each pairwise query errs with probability $\varepsilon$, for some $\varepsilon\in(0,\frac12)$. Mazumdar and Saha provided two algorithms under this model: one algorithm is query-optimal while time-inefficient (i.e., running in quasi-polynomial time), the other is time efficient (i.e., in polynomial time) while query-suboptimal. Larsen, Mitzenmacher and Tsourakakis [WWW 2020] then gave a new time-efficient algorithm for the special case of $2$ clusters, which is query-optimal if the bias $\delta:=1-2\varepsilon$ of the model is large. It was left as an open question whether one can obtain a query-optimal, time-efficient algorithm for the general case of $k$ clusters and other regimes of $\delta$. In this paper, we make progress on the above question and provide a time-efficient algorithm with nearly-optimal query complexity (up to a factor of $O(\log^2 n)$) for all constant $k$ and any $\delta$ in the regime when information-theoretic recovery is possible. Our algorithm is built on a connection to the stochastic block model.