 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Anomaly Detection with Unsupervised GNNs
Oct 20, 2022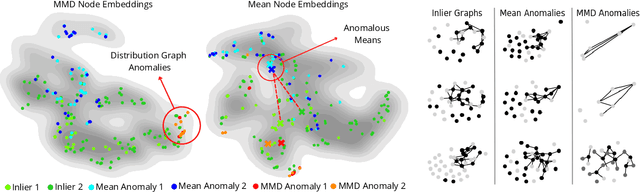
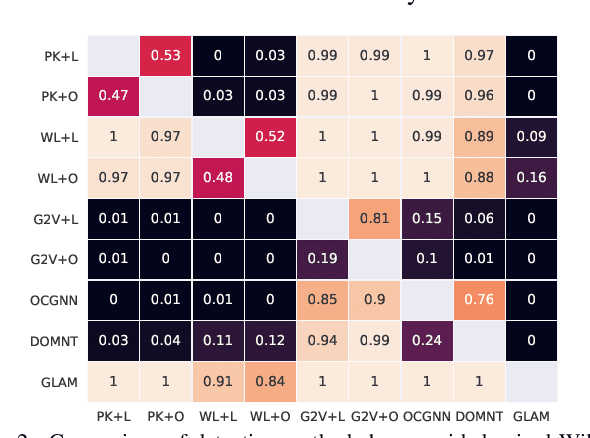
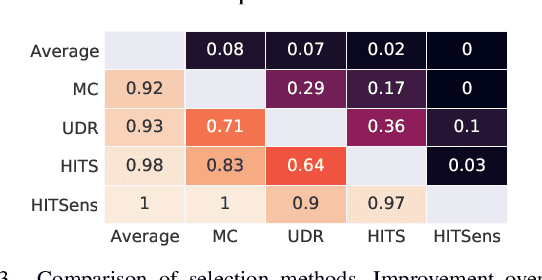

Graph-based anomaly detection finds numerous applications in the real-world. Thus, there exists extensive literature on the topic that has recently shifted toward deep detection models due to advances in deep learning and graph neural networks (GNNs). A vast majority of prior work focuses on detecting node/edge/subgraph anomalies within a single graph, with much less work on graph-level anomaly detection in a graph database. This work aims to fill two gaps in the literature: We (1) design GLAM, an end-to-end graph-level anomaly detection model based on GNNs, and (2) focus on unsupervised model selection, which is notoriously hard due to lack of any labels, yet especially critical for deep NN based models with a long list of hyper-parameters. Further, we propose a new pooling strategy for graph-level embedding, called MMD-pooling, that is geared toward detecting distribution anomalies which has not been considered before. Through extensive experiments on 15 real-world datasets, we show that (i) GLAM outperforms node-level and two-stage (i.e. not end-to-end) baselines, and (ii) model selection picks a significantly more effective model than expectation (i.e. average) -- without using any labels -- among candidates with otherwise large variation in performance.
Fast Attributed Graph Embedding via Density of States
Oct 11, 2021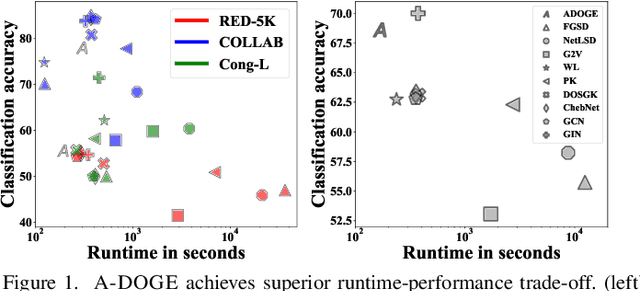
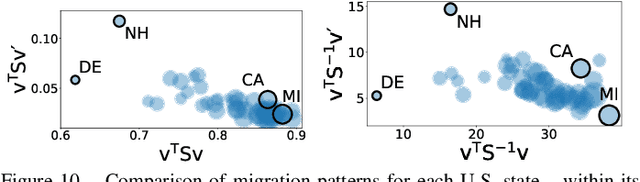
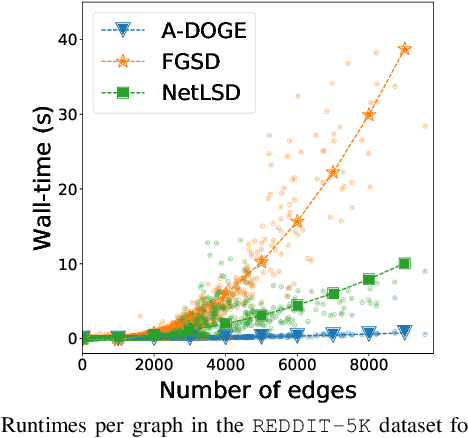
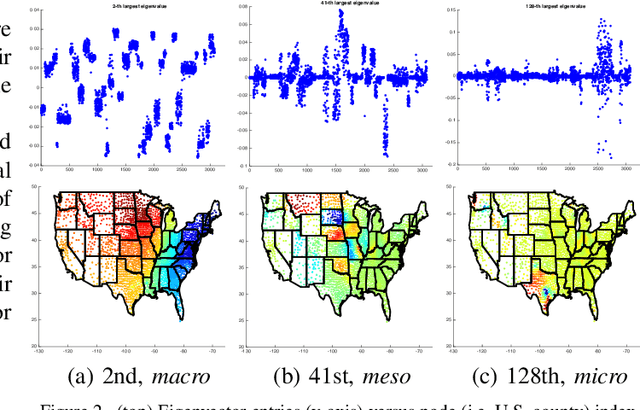
Given a node-attributed graph, how can we efficiently represent it with few numerical features that expressively reflect its topology and attribute information? We propose A-DOGE, for Attributed DOS-based Graph Embedding, based on density of states (DOS, a.k.a. spectral density) to tackle this problem. A-DOGE is designed to fulfill a long desiderata of desirable characteristics. Most notably, it capitalizes on efficient approximation algorithms for DOS, that we extend to blend in node labels and attributes for the first time, making it fast and scalable for large attributed graphs and graph databases. Being based on the entire eigenspectrum of a graph, A-DOGE can capture structural and attribute properties at multiple ("glocal") scales. Moreover, it is unsupervised (i.e. agnostic to any specific objective) and lends itself to various interpretations, which makes it is suitable for exploratory graph mining tasks. Finally, it processes each graph independent of others, making it amenable for streaming settings as well as parallelization. Through extensive experiments, we show the efficacy and efficiency of A-DOGE on exploratory graph analysis and graph classification tasks, where it significantly outperforms unsupervised baselines and achieves competitive performance with modern supervised GNNs, while achieving the best trade-off between accuracy and runtime.
A Study of Performance of Optimal Transport
May 03, 2020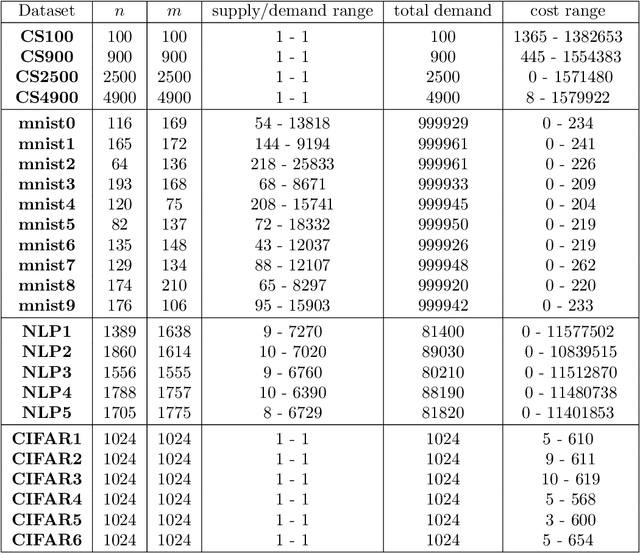
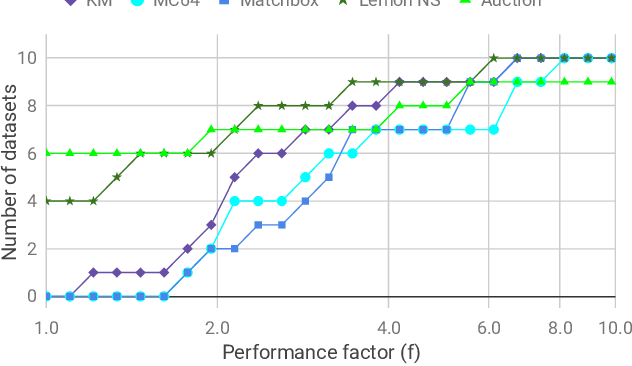
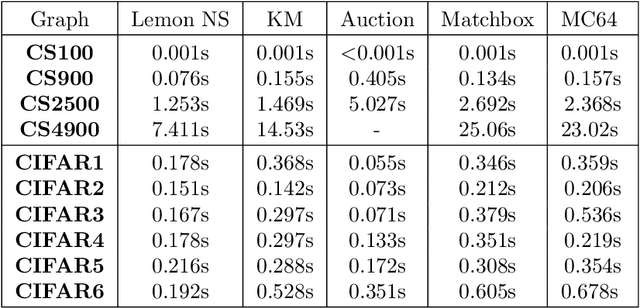
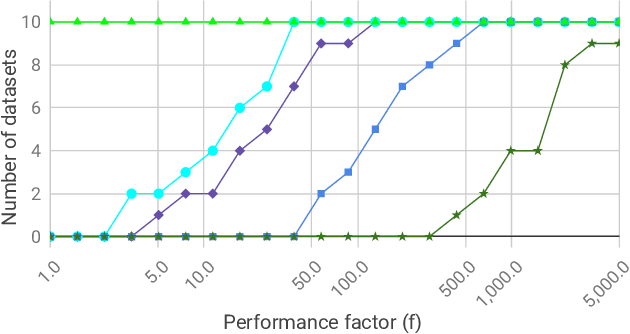
We investigate the problem of efficiently computing optimal transport (OT) distances, which is equivalent to the node-capacitated minimum cost maximum flow problem in a bipartite graph. We compare runtimes in computing OT distances on data from several domains, such as synthetic data of geometric shapes, embeddings of tokens in documents, and pixels in images. We show that in practice, combinatorial methods such as network simplex and augmenting path based algorithms can consistently outperform numerical matrix-scaling based methods such as Sinkhorn [Cuturi'13] and Greenkhorn [Altschuler et al'17], even in low accuracy regimes, with up to orders of magnitude speedups. Lastly, we present a new combinatorial algorithm that improves upon the classical Kuhn-Munkres algorithm.
Faster width-dependent algorithm for mixed packing and covering LPs
Sep 26, 2019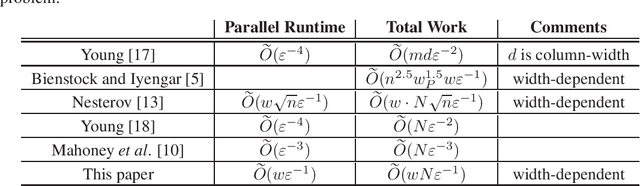
In this paper, we give a faster width-dependent algorithm for mixed packing-covering LPs. Mixed packing-covering LPs are fundamental to combinatorial optimization in computer science and operations research. Our algorithm finds a $1+\eps$ approximate solution in time $O(Nw/ \eps)$, where $N$ is number of nonzero entries in the constraint matrix and $w$ is the maximum number of nonzeros in any constraint. This run-time is better than Nesterov's smoothing algorithm which requires $O(N\sqrt{n}w/ \eps)$ where $n$ is the dimension of the problem. Our work utilizes the framework of area convexity introduced in [Sherman-FOCS'17] to obtain the best dependence on $\eps$ while breaking the infamous $\ell_{\infty}$ barrier to eliminate the factor of $\sqrt{n}$. The current best width-independent algorithm for this problem runs in time $O(N/\eps^2)$ [Young-arXiv-14] and hence has worse running time dependence on $\eps$. Many real life instances of the mixed packing-covering problems exhibit small width and for such cases, our algorithm can report higher precision results when compared to width-independent algorithms. As a special case of our result, we report a $1+\eps$ approximation algorithm for the densest subgraph problem which runs in time $O(md/ \eps)$, where $m$ is the number of edges in the graph and $d$ is the maximum graph degree.
AutoER: Automated Entity Resolution using Generative Modelling
Aug 16, 2019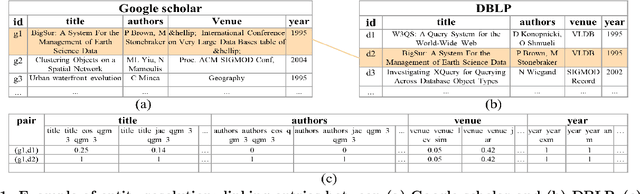
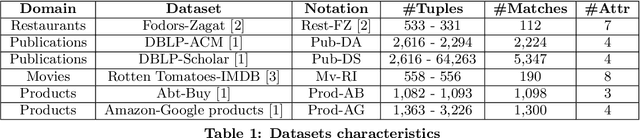
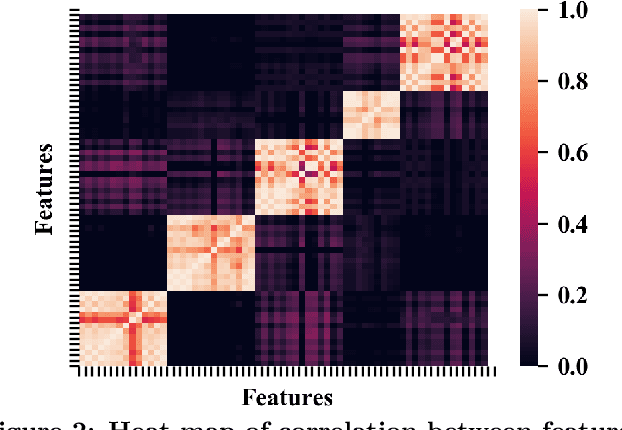
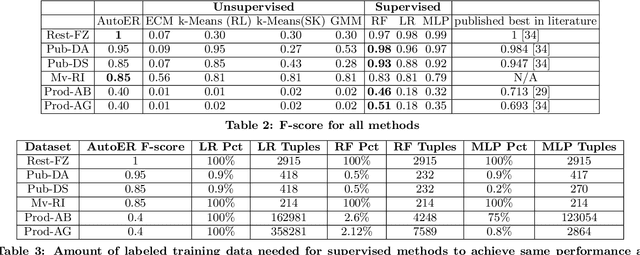
Entity resolution (ER) refers to the problem of identifying records in one or more relations that refer to the same real-world entity. ER has been extensively studied by the database community with supervised machine learning approaches achieving the state-of-the-art results. However, supervised ML requires many labeled examples, both matches and unmatches, which are expensive to obtain. In this paper, we investigate an important problem: how can we design an unsupervised algorithm for ER that can achieve performance comparable to supervised approaches? We propose an automated ER solution, AutoER, that requires zero labeled examples. Our central insight is that the similarity vectors for matches should look different from that of unmatches. A number of innovations are needed to translate the intuition into an actual algorithm for ER. We advocate for the use of generative models to capture the two similarity vector distributions (the match distribution and the unmatch distribution). We propose an expectation maximization based algorithm to learn the model parameters. Our algorithm addresses many practical challenges including feature correlations, model overfitting, class imbalance, and transitivity between matches. On six datasets from four different domains, we show that the performance of AutoER is comparable and sometimes even better than supervised ML approaches.