 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoER: Automated Entity Resolution using Generative Modelling
Aug 16, 2019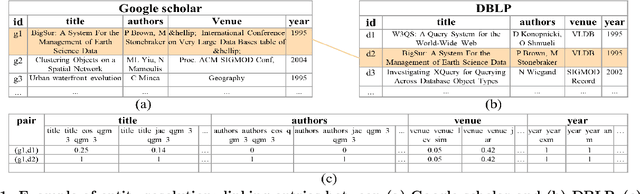
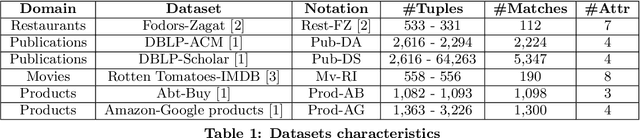
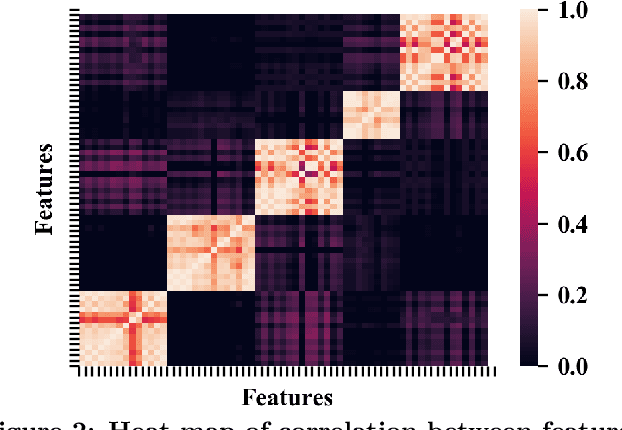
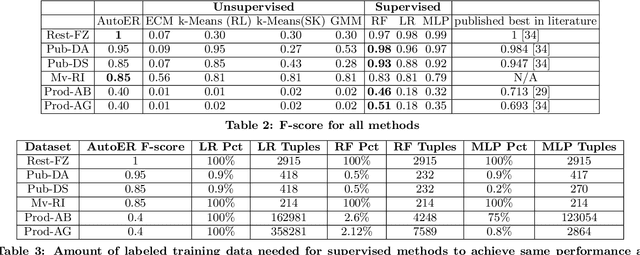
Entity resolution (ER) refers to the problem of identifying records in one or more relations that refer to the same real-world entity. ER has been extensively studied by the database community with supervised machine learning approaches achieving the state-of-the-art results. However, supervised ML requires many labeled examples, both matches and unmatches, which are expensive to obtain. In this paper, we investigate an important problem: how can we design an unsupervised algorithm for ER that can achieve performance comparable to supervised approaches? We propose an automated ER solution, AutoER, that requires zero labeled examples. Our central insight is that the similarity vectors for matches should look different from that of unmatches. A number of innovations are needed to translate the intuition into an actual algorithm for ER. We advocate for the use of generative models to capture the two similarity vector distributions (the match distribution and the unmatch distribution). We propose an expectation maximization based algorithm to learn the model parameters. Our algorithm addresses many practical challenges including feature correlations, model overfitting, class imbalance, and transitivity between matches. On six datasets from four different domains, we show that the performance of AutoER is comparable and sometimes even better than supervised ML approaches.
GOGGLES: Automatic Training Data Generation with Affinity Coding
Mar 11, 2019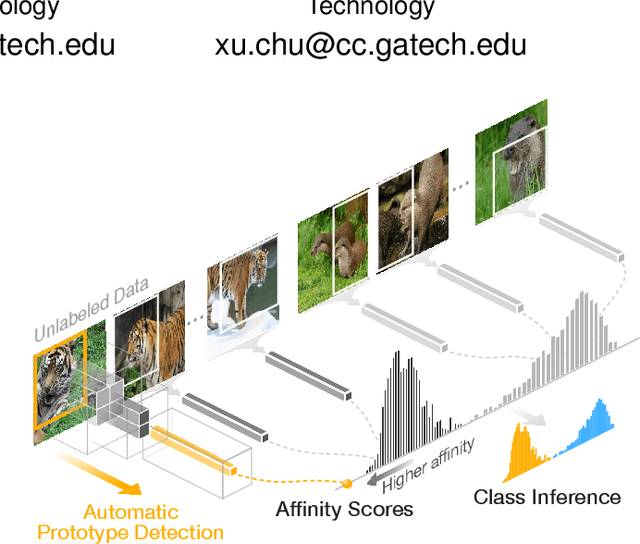
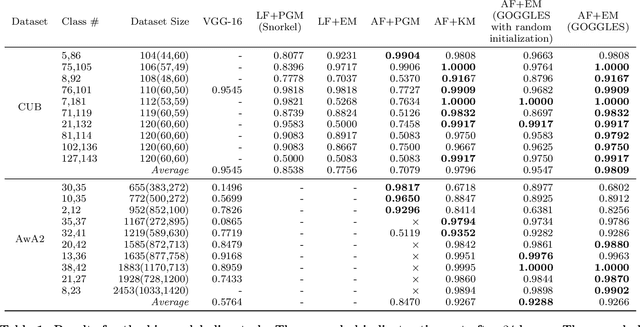
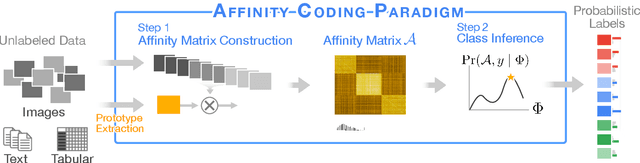
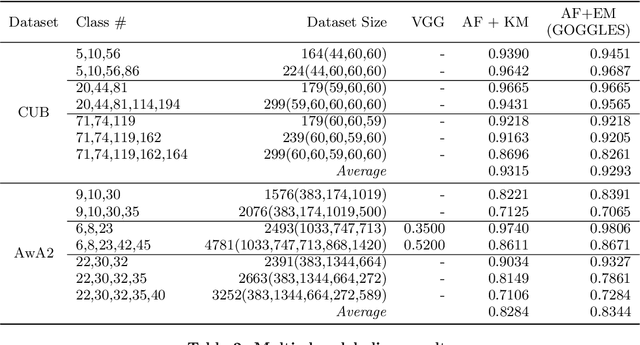
Generating large labeled training data is becoming the biggest bottleneck in building and deploying supervised machine learning models. Recently, data programming has been proposed in the data management community to reduce the human cost in training data generation. Data programming expects users to write a set of labeling functions, each of which is a weak supervision source that labels a subset of data points with better-than-random accuracy. However, the success of data programming heavily depends on the quality (in terms of both accuracy and coverage) of the labeling functions that users still need to design manually. We propose affinity coding, a new paradigm for fully automatic generation of training data. In affinity coding, the similarity between the unlabeled instances and prototypes that are derived from the same unlabeled instances serve as signals (or sources of weak supervision) for determining class membership. We term this implicit similarity as the affinity score. Consequently, we can have as many sources of weak supervision as the number of unlabeled data points, without any human input. We also propose a system called GOGGLES that is an implementation of affinity coding for labeling image datasets. GOGGLES features novel techniques for deriving affinity scores from image datasets based on "semantic prototypes" extracted from convolutional neural nets, as well as an expectation-maximization approach for performing class label inference based on the computed affinity scores. Compared to the state-of-the-art data programming system Snorkel, GOGGLES exhibits 14.88% average improvement in terms of the quality of labels generated for the binary labeling task. The GOGGLES system is open-sourced at https://github.com/chu-data-lab/GOGGLES/.