 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketchQL Demonstration: Zero-shot Video Moment Querying with Sketches
May 28, 2024
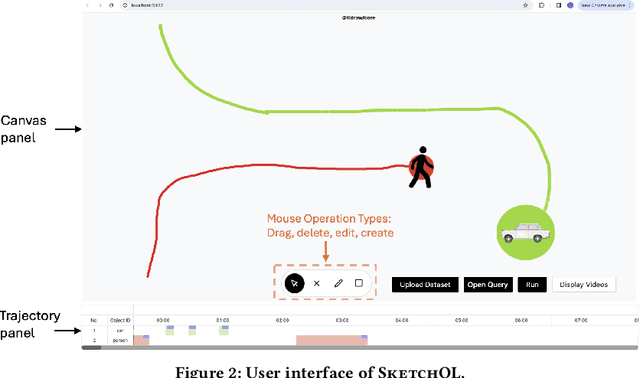
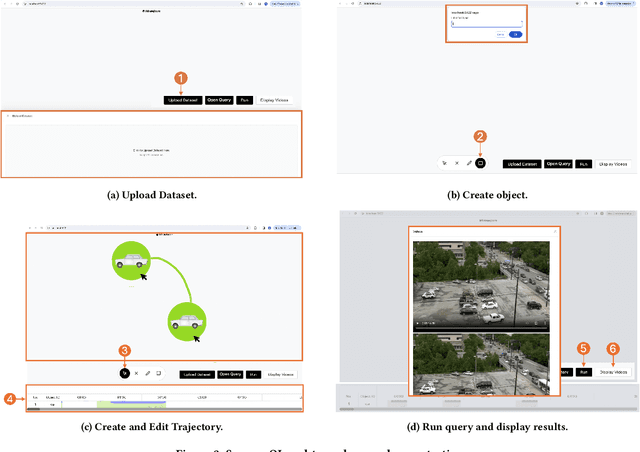
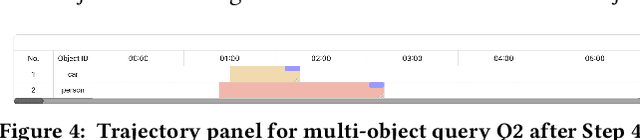
In this paper, we will present SketchQL, a video database management system (VDBMS) for retrieving video moments with a sketch-based query interface. This novel interface allows users to specify object trajectory events with simple mouse drag-and-drop operations. Users can use trajectories of single objects as building blocks to compose complex events. Using a pre-trained model that encodes trajectory similarity, SketchQL achieves zero-shot video moments retrieval by performing similarity searches over the video to identify clips that are the most similar to the visual query. In this demonstration, we introduce the graphic user interface of SketchQL and detail its functionalities and interaction mechanisms. We also demonstrate the end-to-end usage of SketchQL from query composition to video moments retrieval using real-world scenarios.
Decentralized Personalized Online Federated Learning
Nov 08, 2023Vanilla federated learning does not support learning in an online environment, learning a personalized model on each client, and learning in a decentralized setting. There are existing methods extending federated learning in each of the three aspects. However, some important applications on enterprise edge servers (e.g. online item recommendation at global scale) involve the three aspects at the same time. Therefore, we propose a new learning setting \textit{Decentralized Personalized Online Federated Learning} that considers all the three aspects at the same time. In this new setting for learning, the first technical challenge is how to aggregate the shared model parameters from neighboring clients to obtain a personalized local model with good performance on each client. We propose to directly learn an aggregation by optimizing the performance of the local model with respect to the aggregation weights. This not only improves personalization of each local model but also helps the local model adapting to potential data shift by intelligently incorporating the right amount of information from its neighbors. The second challenge is how to select the neighbors for each client. We propose a peer selection method based on the learned aggregation weights enabling each client to select the most helpful neighbors and reduce communication cost at the same time. We verify the effectiveness and robustness of our proposed method on three real-world item recommendation datasets and one air quality prediction dataset.
Rethinking Similarity Search: Embracing Smarter Mechanisms over Smarter Data
Aug 02, 2023



In this vision paper, we propose a shift in perspective for improving the effectiveness of similarity search. Rather than focusing solely on enhancing the data quality, particularly machine learning-generated embeddings, we advocate for a more comprehensive approach that also enhances the underpinning search mechanisms. We highlight three novel avenues that call for a redefinition of the similarity search problem: exploiting implicit data structures and distributions, engaging users in an iterative feedback loop, and moving beyond a single query vector. These novel pathways have gained relevance in emerging applications such as large-scale language models, video clip retrieval, and data labeling. We discuss the corresponding research challenges posed by these new problem areas and share insights from our preliminary discoveries.
Ground Truth Inference for Weakly Supervised Entity Matching
Nov 13, 2022



Entity matching (EM) refers to the problem of identifying pairs of data records in one or more relational tables that refer to the same entity in the real world. Supervised machine learning (ML) models currently achieve state-of-the-art matching performance; however, they require many labeled examples, which are often expensive or infeasible to obtain. This has inspired us to approach data labeling for EM using weak supervision. In particular, we use the labeling function abstraction popularized by Snorkel, where each labeling function (LF) is a user-provided program that can generate many noisy match/non-match labels quickly and cheaply. Given a set of user-written LFs, the quality of data labeling depends on a labeling model to accurately infer the ground-truth labels. In this work, we first propose a simple but powerful labeling model for general weak supervision tasks. Then, we tailor the labeling model specifically to the task of entity matching by considering the EM-specific transitivity property. The general form of our labeling model is simple while substantially outperforming the best existing method across ten general weak supervision datasets. To tailor the labeling model for EM, we formulate an approach to ensure that the final predictions of the labeling model satisfy the transitivity property required in EM, utilizing an exact solution where possible and an ML-based approximation in remaining cases. On two single-table and nine two-table real-world EM datasets, we show that our labeling model results in a 9% higher F1 score on average than the best existing method. We also show that a deep learning EM end model (DeepMatcher) trained on labels generated from our weak supervision approach is comparable to an end model trained using tens of thousands of ground-truth labels, demonstrating that our approach can significantly reduce the labeling efforts required in EM.
Learned Label Aggregation for Weak Supervision
Jul 27, 2022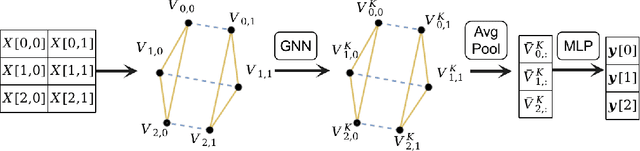
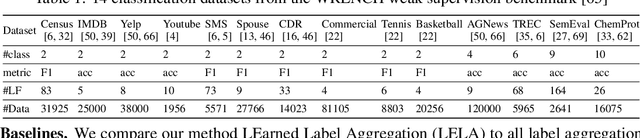
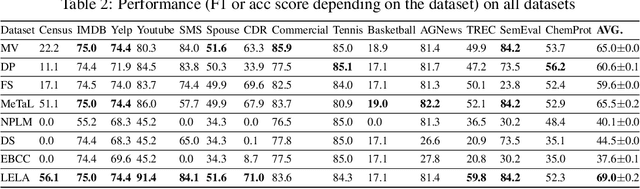
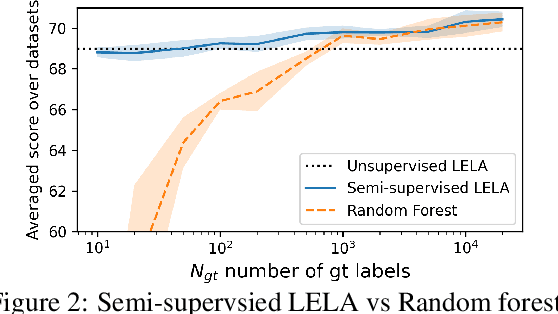
The lack of labeled training data is the bottleneck of machine learning in many applications. To resolve the bottleneck, one promising direction is the data programming approach that aggregates different sources of weak supervision signals to generate labeled data easily. Data programming encodes each weak supervision source with a labeling function (LF), a user-provided program that predicts noisy labels. The quality of the generated labels depends on a label aggregation model that aggregates all noisy labels from all LFs to infer the ground-truth labels. Existing label aggregation methods typically rely on various assumptions and are not robust across datasets, as we will show empirically. We for the first time provide an analytical label aggregation method that makes minimum assumption and is optimal in minimizing a certain form of the averaged prediction error. Since the complexity of the analytical form is exponential, we train a model that learns to be the analytical method. Once trained, the model can be used for any unseen datasets and the model predicts the ground-truth labels for each dataset in a single forward pass in linear time. We show the model can be trained using synthetically generated data and design an effective architecture for the model. On 14 real-world datasets, our model significantly outperforms the best existing methods in both accuracy (by 3.5 points on average) and efficiency (by six times on average).
Learning to be a Statistician: Learned Estimator for Number of Distinct Values
Feb 06, 2022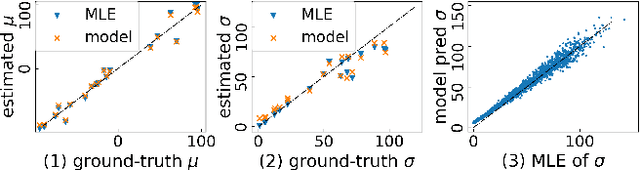

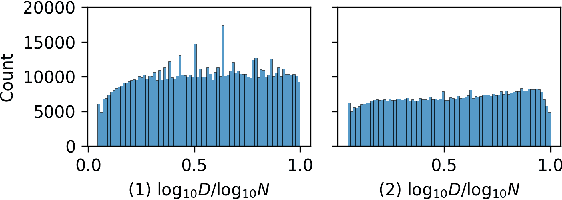
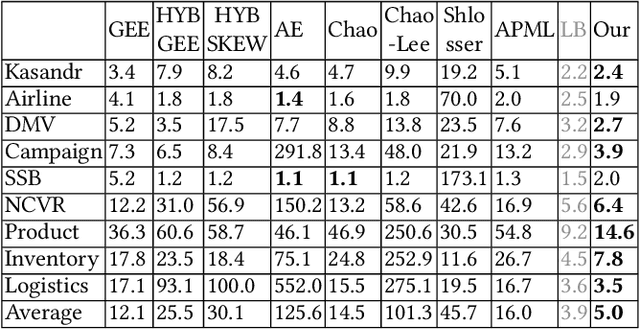
Estimating the number of distinct values (NDV) in a column is useful for many tasks in database systems, such as columnstore compression and data profiling. In this work, we focus on how to derive accurate NDV estimations from random (online/offline) samples. Such efficient estimation is critical for tasks where it is prohibitive to scan the data even once. Existing sample-based estimators typically rely on heuristics or assumptions and do not have robust performance across different datasets as the assumptions on data can easily break. On the other hand, deriving an estimator from a principled formulation such as maximum likelihood estimation is very challenging due to the complex structure of the formulation. We propose to formulate the NDV estimation task in a supervised learning framework, and aim to learn a model as the estimator. To this end, we need to answer several questions: i) how to make the learned model workload agnostic; ii) how to obtain training data; iii) how to perform model training. We derive conditions of the learning framework under which the learned model is workload agnostic, in the sense that the model/estimator can be trained with synthetically generated training data, and then deployed into any data warehouse simply as, e.g., user-defined functions (UDFs), to offer efficient (within microseconds on CPU) and accurate NDV estimations for unseen tables and workloads. We compare the learned estimator with the state-of-the-art sample-based estimators on nine real-world datasets to demonstrate its superior estimation accuracy. We publish our code for training data generation, model training, and the learned estimator online for reproducibility.
* Published at International Conference on Very Large Data Bases (VLDB) 2022
Demonstration of Panda: A Weakly Supervised Entity Matching System
Jun 21, 2021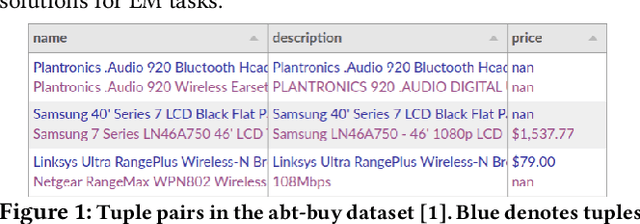

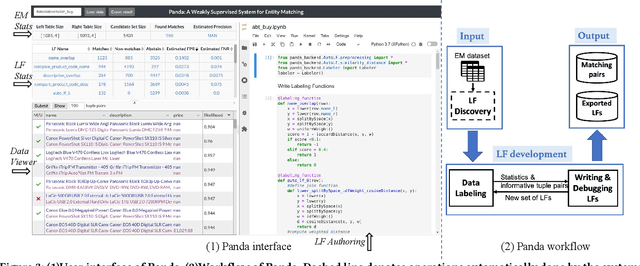
Entity matching (EM) refers to the problem of identifying tuple pairs in one or more relations that refer to the same real world entities. Supervised machine learning (ML) approaches, and deep learning based approaches in particular, typically achieve state-of-the-art matching results. However, these approaches require many labeled examples, in the form of matching and non-matching pairs, which are expensive and time-consuming to label. In this paper, we introduce Panda, a weakly supervised system specifically designed for EM. Panda uses the same labeling function abstraction as Snorkel, where labeling functions (LF) are user-provided programs that can generate large amounts of (somewhat noisy) labels quickly and cheaply, which can then be combined via a labeling model to generate accurate final predictions. To support users developing LFs for EM, Panda provides an integrated development environment (IDE) that lives in a modern browser architecture. Panda's IDE facilitates the development, debugging, and life-cycle management of LFs in the context of EM tasks, similar to how IDEs such as Visual Studio or Eclipse excel in general-purpose programming. Panda's IDE includes many novel features purpose-built for EM, such as smart data sampling, a builtin library of EM utility functions, automatically generated LFs, visual debugging of LFs, and finally, an EM-specific labeling model. We show in this demo that Panda IDE can greatly accelerate the development of high-quality EM solutions using weak supervision.
* video can be found at https://chu-data-lab.cc.gatech.edu/ml-for-data-integration/
Nearest Neighbor Classifiers over Incomplete Information: From Certain Answers to Certain Predictions
May 12, 2020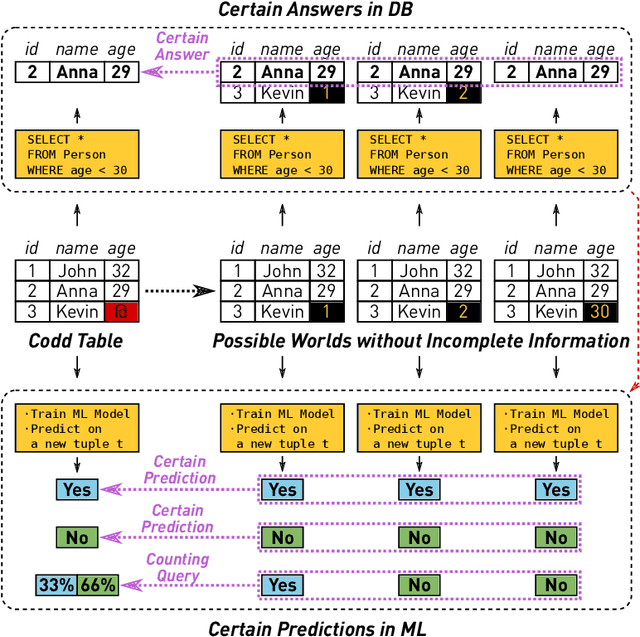
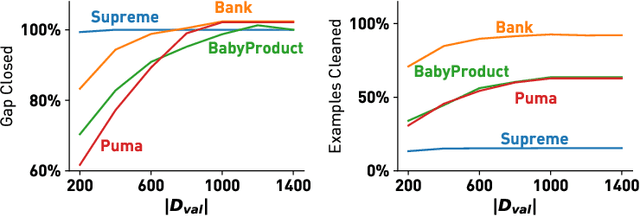
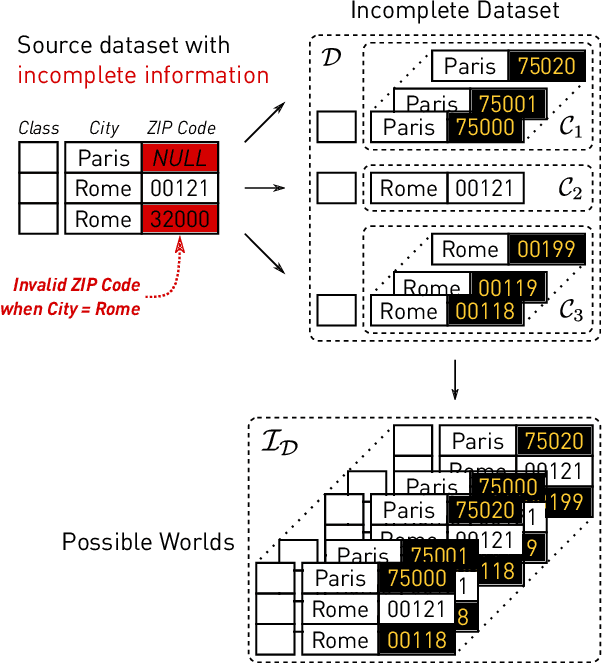
Machine learning (ML) applications have been thriving recently, largely attributed to the increasing availability of data. However, inconsistency and incomplete information are ubiquitous in real-world datasets, and their impact on ML applications remains elusive. In this paper, we present a formal study of this impact by extending the notion of Certain Answers for Codd tables, which has been explored by the database research community for decades, into the field of machine learning. Specifically, we focus on classification problems and propose the notion of "Certain Predictions" (CP) -- a test data example can be certainly predicted (CP'ed) if all possible classifiers trained on top of all possible worlds induced by the incompleteness of data would yield the same prediction. We study two fundamental CP queries: (Q1) checking query that determines whether a data example can be CP'ed; and (Q2) counting query that computes the number of classifiers that support a particular prediction (i.e., label). Given that general solutions to CP queries are, not surprisingly, hard without assumption over the type of classifier, we further present a case study in the context of nearest neighbor (NN) classifiers, where efficient solutions to CP queries can be developed -- we show that it is possible to answer both queries in linear or polynomial time over exponentially many possible worlds. We demonstrate one example use case of CP in the important application of "data cleaning for machine learning (DC for ML)." We show that our proposed CPClean approach built based on CP can often significantly outperform existing techniques in terms of classification accuracy with mild manual cleaning effort.
AutoER: Automated Entity Resolution using Generative Modelling
Aug 16, 2019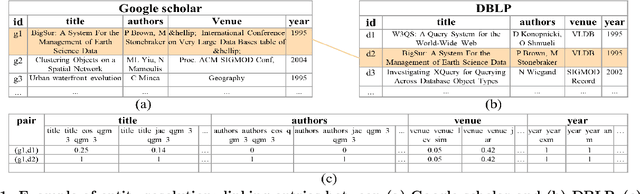
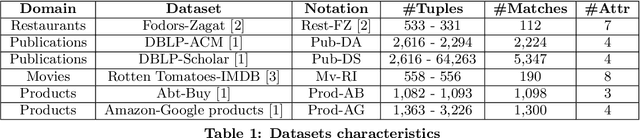
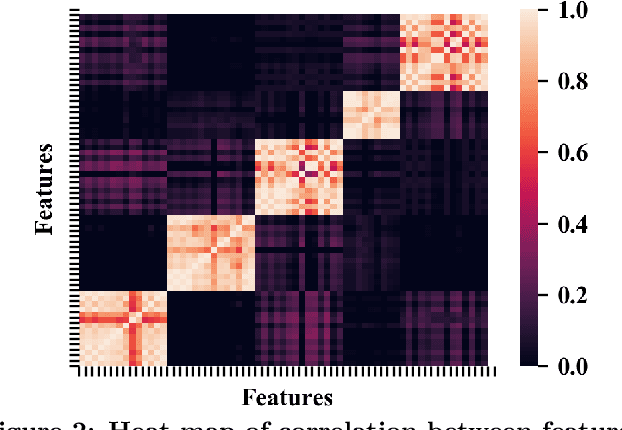
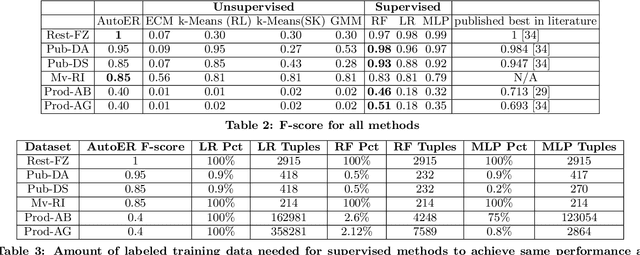
Entity resolution (ER) refers to the problem of identifying records in one or more relations that refer to the same real-world entity. ER has been extensively studied by the database community with supervised machine learning approaches achieving the state-of-the-art results. However, supervised ML requires many labeled examples, both matches and unmatches, which are expensive to obtain. In this paper, we investigate an important problem: how can we design an unsupervised algorithm for ER that can achieve performance comparable to supervised approaches? We propose an automated ER solution, AutoER, that requires zero labeled examples. Our central insight is that the similarity vectors for matches should look different from that of unmatches. A number of innovations are needed to translate the intuition into an actual algorithm for ER. We advocate for the use of generative models to capture the two similarity vector distributions (the match distribution and the unmatch distribution). We propose an expectation maximization based algorithm to learn the model parameters. Our algorithm addresses many practical challenges including feature correlations, model overfitting, class imbalance, and transitivity between matches. On six datasets from four different domains, we show that the performance of AutoER is comparable and sometimes even better than supervised ML approaches.