 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIR: Amortized Image Reconstruction Framework for Self-Supervised Feed-Forward 2D Gaussian Splatting
May 20, 20262D Gaussian splatting provides an efficient explicit representation for image reconstruction, but existing methods still require costly per-image iterative optimization or rely on handcrafted priors for primitive allocation. We present AIR, a self-supervised feed-forward framework that amortizes iterative Gaussian fitting into a single network pass, eliminating per-image test-time optimization. AIR adopts a stage-wise residual architecture that progressively predicts additional Gaussian primitives from reconstruction residuals, together with an explicit Stage Control mechanism that activates new primitives only in under-reconstructed regions. A Predict--Optimize--Distill training strategy stabilizes multi-stage prediction by distilling short-horizon optimized Gaussian increments back into the predictor. The stabilized predictor is then jointly finetuned across stages and equipped with an image-adaptive quantizer for compact Gaussian storage. Experiments on Kodak and DIV2K show that AIR achieves better reconstruction quality than representative Gaussian-based baselines while reducing encoding time to 160--300\,ms. Code: https://github.com/whoiszzj/AIR.git
MIDAS: Multi-Image Dispersion and Semantic Reconstruction for Jailbreaking MLLMs
Feb 28, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable performance but remain vulnerable to jailbreak attacks that can induce harmful content and undermine their secure deployment. Previous studies have shown that introducing additional inference steps, which disrupt security attention, can make MLLMs more susceptible to being misled into generating malicious content. However, these methods rely on single-image masking or isolated visual cues, which only modestly extend reasoning paths and thus achieve limited effectiveness, particularly against strongly aligned commercial closed-source models. To address this problem, in this paper, we propose Multi-Image Dispersion and Semantic Reconstruction (MIDAS), a multimodal jailbreak framework that decomposes harmful semantics into risk-bearing subunits, disperses them across multiple visual clues, and leverages cross-image reasoning to gradually reconstruct the malicious intent, thereby bypassing existing safety mechanisms. The proposed MIDAS enforces longer and more structured multi-image chained reasoning, substantially increases the model's reliance on visual cues while delaying the exposure of malicious semantics and significantly reducing the model's security attention, thereby improving the performance of jailbreak against advanced MLLMs. Extensive experiments across different datasets and MLLMs demonstrate that the proposed MIDAS outperforms state-of-the-art jailbreak attacks for MLLMs and achieves an average attack success rate of 81.46% across 4 closed-source MLLMs. Our code is available at this [link](https://github.com/Winnie-Lian/MIDAS).
Frequency-Aware Density Control via Reparameterization for High-Quality Rendering of 3D Gaussian Splatting
Mar 10, 2025By adaptively controlling the density and generating more Gaussians in regions with high-frequency information, 3D Gaussian Splatting (3DGS) can better represent scene details. From the signal processing perspective, representing details usually needs more Gaussians with relatively smaller scales. However, 3DGS currently lacks an explicit constraint linking the density and scale of 3D Gaussians across the domain, leading to 3DGS using improper-scale Gaussians to express frequency information, resulting in the loss of accuracy. In this paper, we propose to establish a direct relation between density and scale through the reparameterization of the scaling parameters and ensure the consistency between them via explicit constraints (i.e., density responds well to changes in frequency). Furthermore, we develop a frequency-aware density control strategy, consisting of densification and deletion, to improve representation quality with fewer Gaussians. A dynamic threshold encourages densification in high-frequency regions, while a scale-based filter deletes Gaussians with improper scale. Experimental results on various datasets demonstrate that our method outperforms existing state-of-the-art methods quantitatively and qualitatively.
EfficientGS: Streamlining Gaussian Splatting for Large-Scale High-Resolution Scene Representation
Apr 19, 2024



In the domain of 3D scene representation, 3D Gaussian Splatting (3DGS) has emerged as a pivotal technology. However, its application to large-scale, high-resolution scenes (exceeding 4k$\times$4k pixels) is hindered by the excessive computational requirements for managing a large number of Gaussians. Addressing this, we introduce 'EfficientGS', an advanced approach that optimizes 3DGS for high-resolution, large-scale scenes. We analyze the densification process in 3DGS and identify areas of Gaussian over-proliferation. We propose a selective strategy, limiting Gaussian increase to key primitives, thereby enhancing the representational efficiency. Additionally, we develop a pruning mechanism to remove redundant Gaussians, those that are merely auxiliary to adjacent ones. For further enhancement, we integrate a sparse order increment for Spherical Harmonics (SH), designed to alleviate storage constraints and reduce training overhead. Our empirical evaluations, conducted on a range of datasets including extensive 4K+ aerial images, demonstrate that 'EfficientGS' not only expedites training and rendering times but also achieves this with a model size approximately tenfold smaller than conventional 3DGS while maintaining high rendering fidelity.
C2F2NeUS: Cascade Cost Frustum Fusion for High Fidelity and Generalizable Neural Surface Reconstruction
Jun 16, 2023There is an emerging effort to combine the two popular technical paths, i.e., the multi-view stereo (MVS) and neural implicit surface (NIS), in scene reconstruction from sparse views. In this paper, we introduce a novel integration scheme that combines the multi-view stereo with neural signed distance function representations, which potentially overcomes the limitations of both methods. MVS uses per-view depth estimation and cross-view fusion to generate accurate surface, while NIS relies on a common coordinate volume. Based on this, we propose to construct per-view cost frustum for finer geometry estimation, and then fuse cross-view frustums and estimate the implicit signed distance functions to tackle noise and hole issues. We further apply a cascade frustum fusion strategy to effectively captures global-local information and structural consistency. Finally, we apply cascade sampling and a pseudo-geometric loss to foster stronger integration between the two architectures. Extensive experiments demonstrate that our method reconstructs robust surfaces and outperforms existing state-of-the-art methods.
Learning to be a Statistician: Learned Estimator for Number of Distinct Values
Feb 06, 2022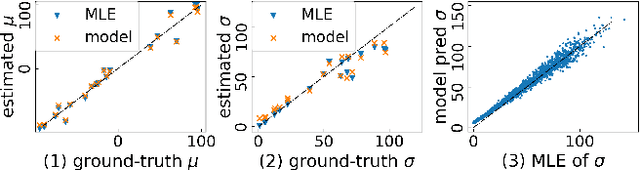

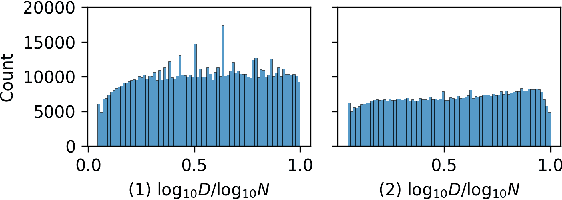
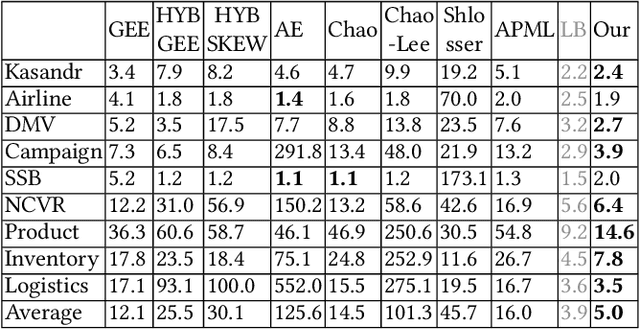
Estimating the number of distinct values (NDV) in a column is useful for many tasks in database systems, such as columnstore compression and data profiling. In this work, we focus on how to derive accurate NDV estimations from random (online/offline) samples. Such efficient estimation is critical for tasks where it is prohibitive to scan the data even once. Existing sample-based estimators typically rely on heuristics or assumptions and do not have robust performance across different datasets as the assumptions on data can easily break. On the other hand, deriving an estimator from a principled formulation such as maximum likelihood estimation is very challenging due to the complex structure of the formulation. We propose to formulate the NDV estimation task in a supervised learning framework, and aim to learn a model as the estimator. To this end, we need to answer several questions: i) how to make the learned model workload agnostic; ii) how to obtain training data; iii) how to perform model training. We derive conditions of the learning framework under which the learned model is workload agnostic, in the sense that the model/estimator can be trained with synthetically generated training data, and then deployed into any data warehouse simply as, e.g., user-defined functions (UDFs), to offer efficient (within microseconds on CPU) and accurate NDV estimations for unseen tables and workloads. We compare the learned estimator with the state-of-the-art sample-based estimators on nine real-world datasets to demonstrate its superior estimation accuracy. We publish our code for training data generation, model training, and the learned estimator online for reproducibility.
* Published at International Conference on Very Large Data Bases (VLDB) 2022
Adversarial Style Mining for One-Shot Unsupervised Domain Adaptation
Apr 13, 2020
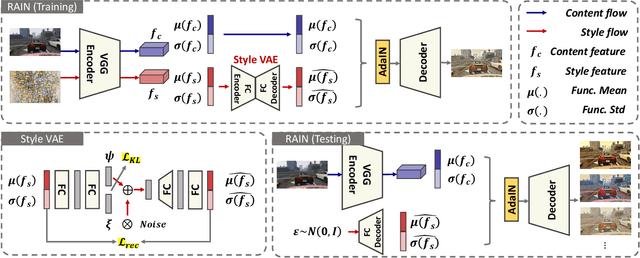
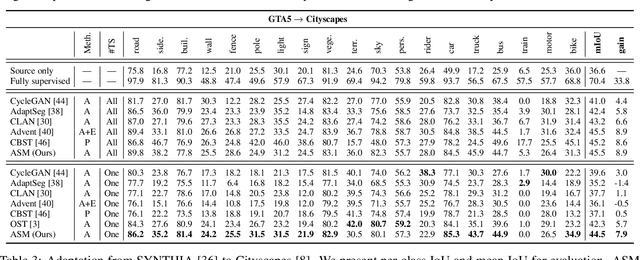
We aim at the problem named One-Shot Unsupervised Domain Adaptation. Unlike traditional Unsupervised Domain Adaptation, it assumes that only one unlabeled target sample can be available when learning to adapt. This setting is realistic but more challenging, in which conventional adaptation approaches are prone to failure due to the scarce of unlabeled target data. To this end, we propose a novel Adversarial Style Mining approach, which combines the style transfer module and task-specific module into an adversarial manner. Specifically, the style transfer module iteratively searches for harder stylized images around the one-shot target sample according to the current learning state, leading the task model to explore the potential styles that are difficult to solve in the almost unseen target domain, thus boosting the adaptation performance in a data-scarce scenario. The adversarial learning framework makes the style transfer module and task-specific module benefit each other during the competition. Extensive experiments on both cross-domain classification and segmentation benchmarks verify that ASM achieves state-of-the-art adaptation performance under the challenging one-shot setting.
Significance-aware Information Bottleneck for Domain Adaptive Semantic Segmentation
Apr 01, 2019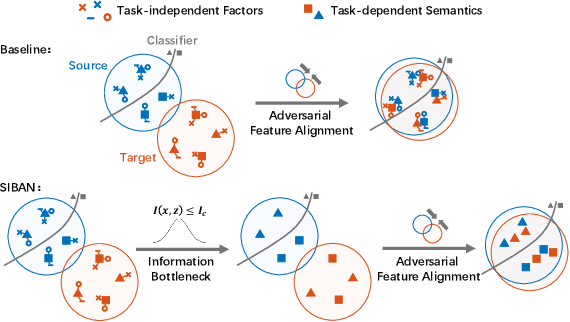
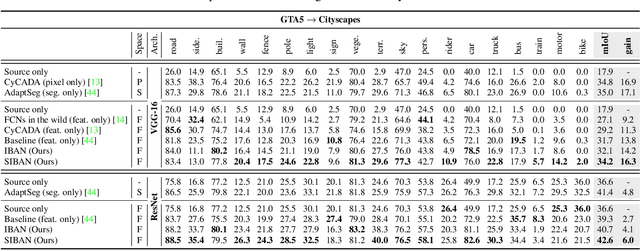
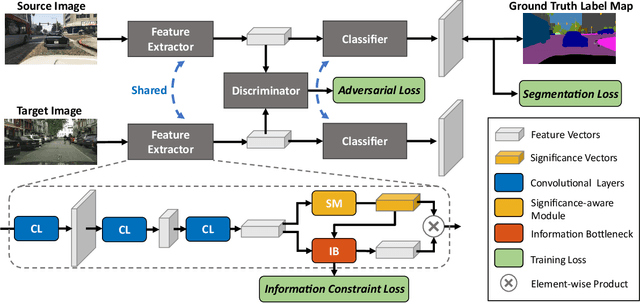
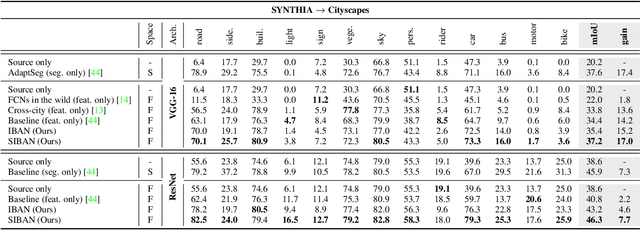
For unsupervised domain adaptation problems, the strategy of aligning the two domains in latent feature space through adversarial learning has achieved much progress in image classification, but usually fails in semantic segmentation tasks in which the latent representations are overcomplex. In this work, we equip the adversarial network with a "significance-aware information bottleneck (SIB)", to address the above problem. The new network structure, called SIBAN, enables a significance-aware feature purification before the adversarial adaptation, which eases the feature alignment and stabilizes the adversarial training course. In two domain adaptation tasks, i.e., GTA5 -> Cityscapes and SYNTHIA -> Cityscapes, we validate that the proposed method can yield leading results compared with other feature-space alternatives. Moreover, SIBAN can even match the state-of-the-art output-space methods in segmentation accuracy, while the latter are often considered to be better choices for domain adaptive segmentation task.
Taking A Closer Look at Domain Shift: Category-level Adversaries for Semantics Consistent Domain Adaptation
Sep 27, 2018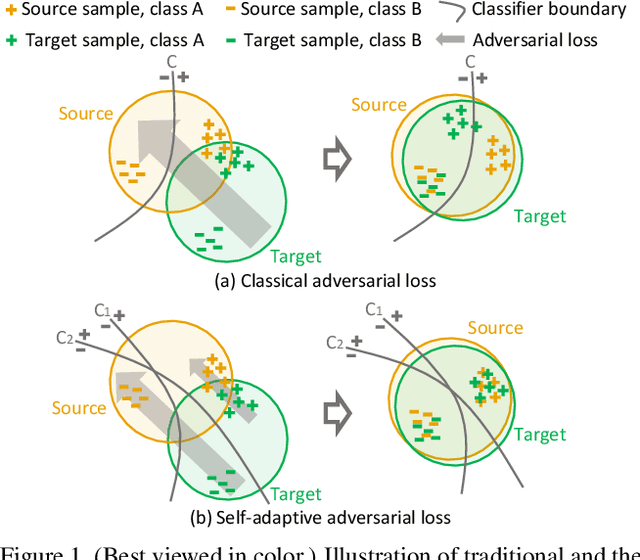
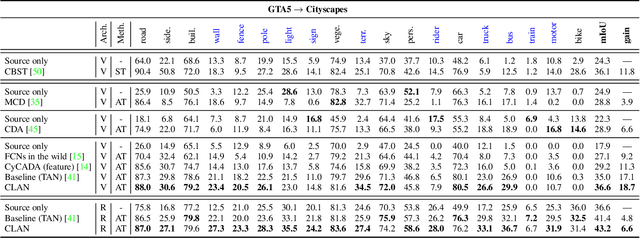
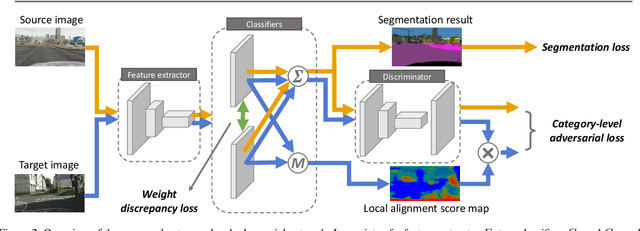
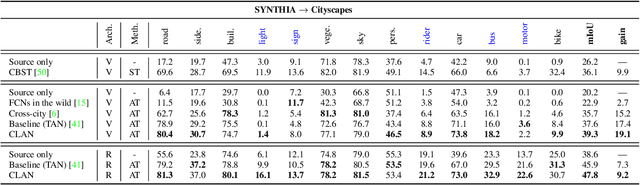
We consider the problem of unsupervised domain adaptation in semantic segmentation, in which the source domain is fully annotated, and the target domain is unlabeled. The key in this campaign consists in reducing the domain shift, i.e., enforcing the data distributions of the two domains to be similar. A popular strategy is to align the marginal distribution in the feature space through adversarial learning. However, this global alignment strategy does not consider the local category-level feature distribution. A possible consequence of the global movement is that some categories which are originally well aligned between the source and target may be incorrectly mapped. To address this problem, this paper introduces a category-level adversarial network, aiming to enforce local semantic consistency during the trend of global alignment. Our idea is to take a close look at the category-level data distribution and align each class with an adaptive adversarial loss. Specifically, we reduce the weight of the adversarial loss for category-level aligned features while increasing the adversarial force for those poorly aligned. In this process, we decide how well a feature is category-level aligned between source and target by a co-training approach. In two domain adaptation tasks, i.e., GTA5 -> Cityscapes and SYNTHIA -> Cityscapes, we validate that the proposed method matches the state of the art in segmentation accuracy.
Every Node Counts: Self-Ensembling Graph Convolutional Networks for Semi-Supervised Learning
Sep 26, 2018
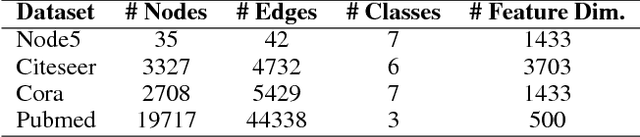
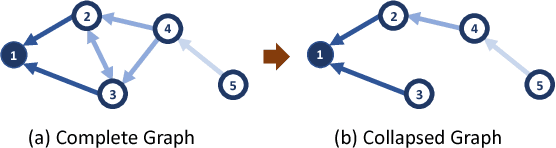
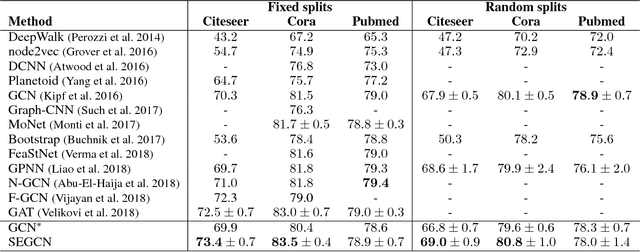
Graph convolutional network (GCN) provides a powerful means for graph-based semi-supervised tasks. However, as a localized first-order approximation of spectral graph convolution, the classic GCN can not take full advantage of unlabeled data, especially when the unlabeled node is far from labeled ones. To capitalize on the information from unlabeled nodes to boost the training for GCN, we propose a novel framework named Self-Ensembling GCN (SEGCN), which marries GCN with Mean Teacher - another powerful model in semi-supervised learning. SEGCN contains a student model and a teacher model. As a student, it not only learns to correctly classify the labeled nodes, but also tries to be consistent with the teacher on unlabeled nodes in more challenging situations, such as a high dropout rate and graph collapse. As a teacher, it averages the student model weights and generates more accurate predictions to lead the student. In such a mutual-promoting process, both labeled and unlabeled samples can be fully utilized for backpropagating effective gradients to train GCN. In three article classification tasks, i.e. Citeseer, Cora and Pubmed, we validate that the proposed method matches the state of the arts in the classification accuracy.